操作系统课设探索
参考资料
正文
环境配置
官方工具链
安装所需的包:
sudo apt update && sudo apt install -y clang llvm lld qemu-system-riscv32 curlclang:C 编译器。确保支持 32 位 RISC-V CPUlld: LLVM 链接器,将编译后的目标文件链接成可执行文件qemu-system-riscv32:32 位的 RISC-V CPU 模拟器。它是 QEMU 包的一部分
下载OpenSBI(引导程序)(把它理解成是 PC 的 BIOS/UEFI):
curl -LO https://github.com/qemu/qemu/raw/v8.0.4/pc-bios/opensbi-riscv32-generic-fw_dynamic.bin(这里我直接从浏览器下载,curl莫名走不了代理)
提示
用下面的指令检查clang是否支持32位RISC-V CPU:
$ clang -print-targets | grep riscv32
riscv32 - 32-bit RISC-Vgcc + qemu 工具链
默认的GCC不包含RISC-V工具链,因此也需要额外安装RISC-V架构的GCC工具
sudo apt update
sudo apt install -y gcc-riscv64-linux-gnu binutils-riscv64-linux-gnu
sudo apt install -y llvm lld qemu-system-riscv32 curl环境要求 && 须知
RISC-V(操作系统的指令集基础)
Github官方项目就拿这个做,图省事就没弄别的
QEMU虚拟机
- 用于模拟完整的系统,而不只是虚拟化
- 用于在物理机无关的系统上模拟ARM架构CPU等物理硬件,而不会像VMWare或VirtualBox那样受制于物理机的硬件
RISC-V Assembly
使用Compiler Explorer观察C语言与汇编代码的互相映射
提示
Compiler Explorer是一个在线编译器,写下C代码后会在右边的输出框中显示相应的汇编代码
Compiler Explorer 默认使用 x86-64 CPU 汇编。可以通过在右边面板中指定 RISC-V rv32gc clang (trunk) 来输出 32 位 RISC-V 汇编
(实际我没有找到RISC-V rv32gc clang (trunk)这个选项,只好先拿gcc凑凑数)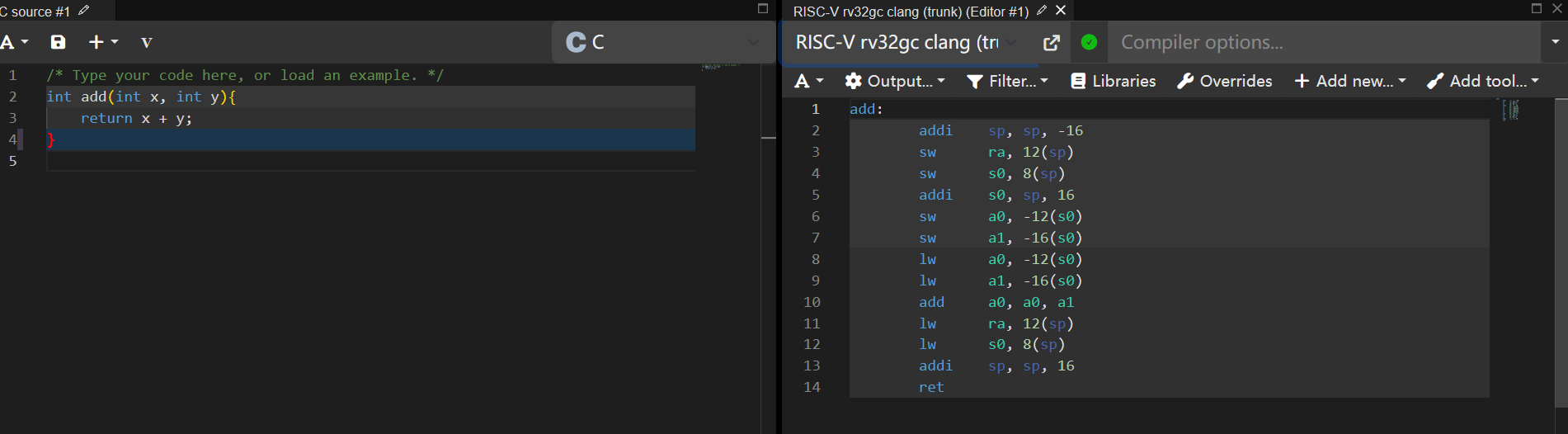
默认没有编译优化,下面是-O2优化的效果: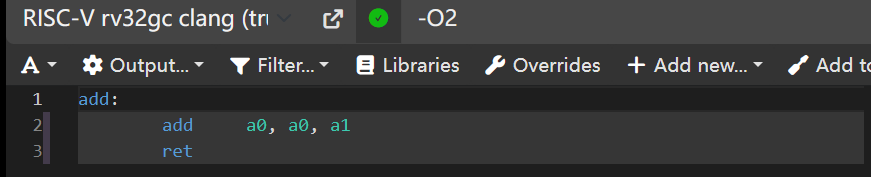
直接变寄存器相加了
汇编语言基础
汇编语言(几乎)是机器代码的直接表示。
寄存器
寄存器类就像 CPU 中的临时变量,它们比内存快很多。CPU 将内存中的数据读取到寄存器,对寄存器做算术运算,然后将结果回写到内存或者寄存器。
下面是RISC-V中的常见寄存器:
| 寄存器 | ABI 名称 (别名) | 解释 |
|---|---|---|
pc | pc | 程序计数器(下一条指令的位置) |
x0 | zero | 硬连线零(始终读为零) |
x1 | ra | 返回地址 |
x2 | sp | 栈指针 |
x5 - x7 | t0 - t2 | 临时寄存器 |
x8 | fp | 栈帧指针 |
x10 - x11 | a0 - a1 | 函数参数/返回值 |
x12 - x17 | a2 - a7 | 函数参数 |
x18 - x27 | s0 - s11 | 调用期间保存的临时寄存器 |
x28 - x31 | t3 - t6 | 临时寄存器 |
调用约定
通常来说,你可以按照你的喜好来使用寄存器,但为了和其他软件互通,寄存器的使用方式有明确的定义 —— 这被称为 调用约定。
内存访问
程序从内存中读取数据或者往内存中写入数据是通过
lw(load word) 指令和sw(store word) 指令来实现的:
lw a0, (a1) // 从 a1 寄存器中保存的地址中读取一个字(word,32 位)
// 然后保存到 a0 寄存器。在 C 语言就是: a0 = *a1;sw a0, (a1) // 向 a1 保存的地址中写入一个字,这个字是保存在 a0 的。
// 在 C 语言中是: *a1 = a0;分支指令
分支指令将会改变程序的控制流。它们被用于实现
if、for和while语句
与8086的条件转移指令 类似,但具体的指令并不相同
函数调用
jal(jump and link,跳转和链接)和ret(return,返回)指令被用作调用函数和返回:
li a0, 123 // 加载 123 到 a0 寄存器(函数参数)
jal ra, <label> // 跳转到 <label> 并且将返回地址保存到
// ra 寄存器中。
// 函数调用结束后将会从这里继续...
// int func(int a) {
// a += 1;
// return a;
// }
<label>:
addi a0, a0, 1 // 给 a0 (第一个参数) 加 1
ret // 返回到 ra 保存的地址。
// 返回值在 a0 寄存器。按照调用约定,函数参数会通过
a0-a7寄存器传递,返回值则是保存在a0寄存器。
栈
栈是一个被用于函数调用和局部变量的后进先出(LIFO)的内存空间。它是向下发展的,栈指针
sp指向栈顶。
为了保存一个值到栈中,需要减小(后移)栈指针然后保存值(也被称作 push 操作):
addi sp, sp, -4 // 将栈指针向下移动 4 字节
// (即栈分配)
sw a0, (sp) // 将 a0 保存到栈而从栈读取一个值,则是读取值然后增加(前移)栈指针(也被称作 pop 操作):
lw a0, (sp) // 从栈中读取到 a0
addi sp, sp, 4 // 将栈指针向上移动 4 字节
// (即栈释放)CPU模式
CPU 有多种模式,每个有不同的特权。在 RISC-V 中有三种模式
特权指令
在 CPU 指令中,有一些被称为特权指令的是应用程序(用户模式)不能执行的
内联汇编
uint32_t value;
__asm__ __volatile__("csrr %0, sepc" : "=r"(value));“内联汇编”,一种在 C 语言中嵌入汇编的语法。虽然你可以在一个单独的文件(
.S扩展名)中写汇编,但是更建议首选内联汇编,因为:
- 你可以在汇编中使用 C 变量。同样的,你也可以将汇编结果分配给 C 变量。
- 你可以将寄存器分配工作交给 C 编译器。这么做你就不需要手写汇编代码来处理寄存器的保存和恢复。
内联汇编代码的编码格式如下:
__asm__ __volatile__("assembly" : output operands : input operands : clobbered registers);| 部分 | 释义 |
|---|---|
__asm__ | 表示这是内联汇编 |
__volatile__ | 告诉编译器不要优化 "assembly" 这部分代码。 |
"assembly" | 以字符串字面量编写的汇编代码 |
| output operands | 用来保存汇编结果的 C 变量 |
| input operands | 在汇编中使用的 C 表达式(例如 123、x)。 |
| clobbered registers | 在汇编中会被破坏内容的寄存器。如果忘写,C 编译器将不会保留这些寄存器的内容,然后可能会引发 bug。 |
输出和输入操作数是用冒号隔开的,每个操作数都是按
约束 (C 表达式)格式写的。约束被用来指定操作数类型,通常用=r(寄存器) 表示输出操作数,r表示输入操作数。
在汇编中可以用
%0、%1、%2等等(第一个是输出)来访问输出和输入操作数。
示例
uint32_t value;
__asm__ __volatile__("csrr %0, sepc" : "=r"(value));使用
csrr指令来读取sepcCSR 的值,然后将它分配给value变量。%0对应到value变量。
__asm__ __volatile__("csrw sscratch, %0" : : "r"(123));使用
csrw指令将123写入到sscratchCSR。%0对应到包含123(r约束) 的寄存器,它实际上像是:
li a0, 123 // 将 123 存到 a0 寄存器
csrw sscratch, a0 // 将 a0 寄存器的值写入到 sscratch 寄存器虽然内联汇编中只有
csrw指令,但是li指令会被编译器自动插入以满足"r"约束(寄存器中的值)。
系统引导
当计算机开机时,CPU 会初始化自身并开始执行操作系统。操作系统初始化硬件并启动应用程序。这个过程称为“引导”(booting)。
SBI
监管者二进制接口(Supervisor Binary Interface,SBI)是一个面向操作系统内核的 API,它定义了固件(OpenSBI)向操作系统提供的功能。
一个著名的 SBI 实现是 OpenSBI。在 QEMU 中,默认启动 OpenSBI,执行特定硬件的初始化,然后引导内核。
启动OpenSBI
创建一个run.sh,写上:
#!/bin/bash
set -xue
# QEMU 文件路径
QEMU=qemu-system-riscv32
# 启动 QEMU
$QEMU -machine virt -bios default -nographic -serial mon:stdio --no-reboot-machine virt:启动一个virt机器。你可以用-machine '?'选项查看其他支持的机器。-bios default:使用默认固件(在本例中是 OpenSBI)。-nographic:启动 QEMU 时不使用 GUI 窗口。-serial mon:stdio:将 QEMU 的标准输入/输出连接到虚拟机的串行端口。指定mon:允许通过按下 Ctrl+A 然后 C 切换到 QEMU 监视器。--no-reboot:如果虚拟机崩溃,停止模拟器而不重启(对调试有用)。
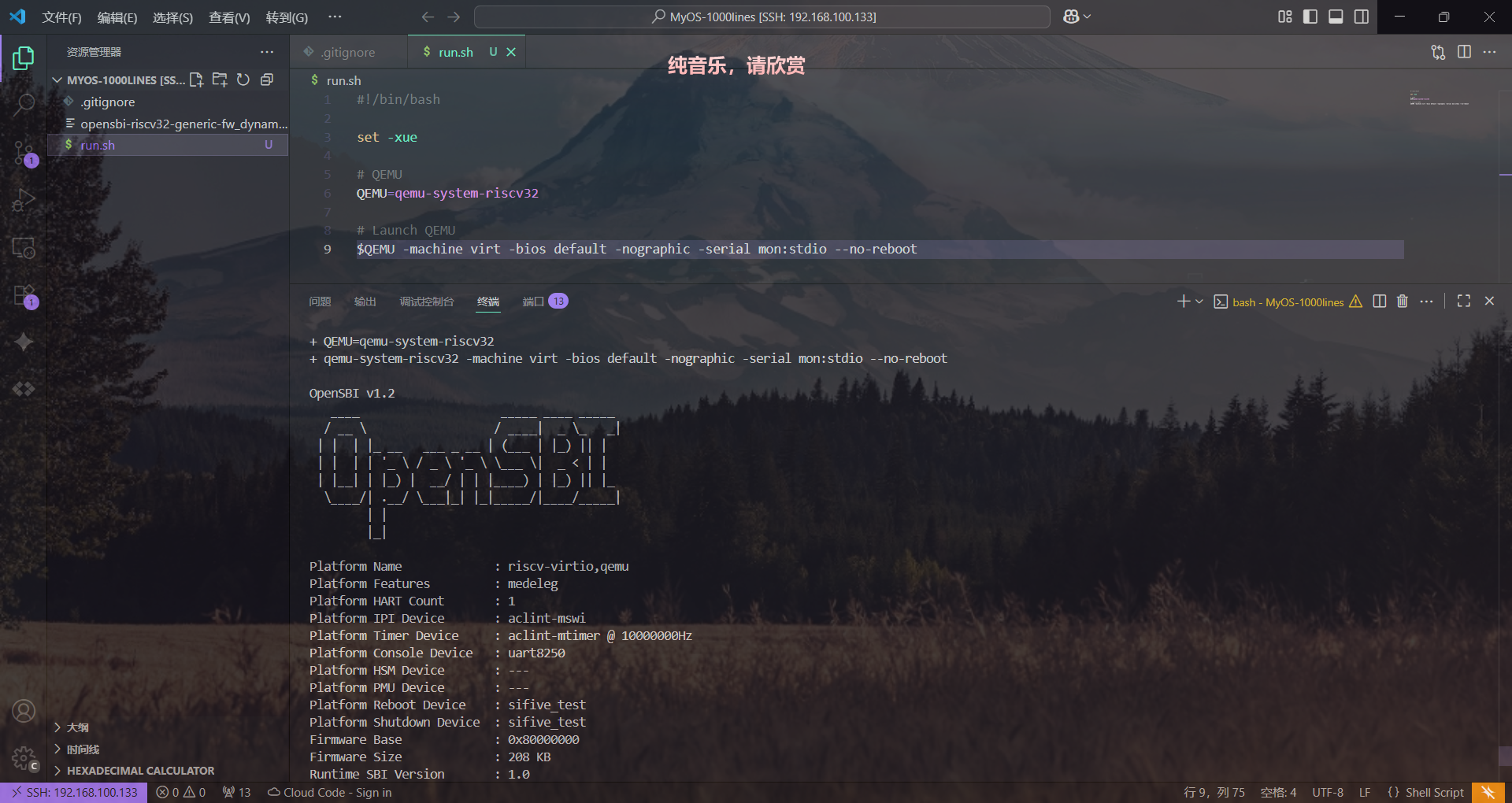
运行脚本将会看到所示Banner
接下来按下 Ctrl+A 然后 C 切换到 QEMU 调试控制台(QEMU 监视器)
QEMU 10.0.3 monitor - type 'help' for more information
(qemu)输入q可退出控制台,其他指令排列方式如下(以Ctrl + A为例)
C-a h 打印此帮助
C-a x 退出模拟器
C-a s 将磁盘数据保存回文件(如果使用 -snapshot)
C-a t 切换控制台时间戳
C-a b 发送中断(magic sysrq)
C-a c 在控制台和监视器之间切换
C-a C-a 发送 C-a链接器脚本
链接器脚本是定义可执行文件内存布局的文件。根据此布局,链接器为函数和变量分配内存地址。
创建kernel.ld:
ENTRY(boot)
SECTIONS {
. = 0x80200000;
.text :{
KEEP(*(.text.boot));
*(.text .text.*);
}
.rodata : ALIGN(4) {
*(.rodata .rodata.*);
}
.data : ALIGN(4) {
*(.data .data.*);
}
.bss : ALIGN(4) {
__bss = .;
*(.bss .bss.* .sbss .sbss.*);
__bss_end = .;
}
. = ALIGN(4);
. += 128 * 1024; /* 128KB */
__stack_top = .;
}参数和语句解释如下:
- 内核的入口点是
boot函数。 - 基地址是
0x80200000。 .text.boot段总是放在开头。- 各段按
.text、.rodata、.data和.bss的顺序放置。 - 内核栈放在
.bss段之后,大小为 128KB。
| 段名 | 描述 |
|---|---|
.text | 此段包含程序的代码。 |
.rodata | 此段包含只读的常量数据。 |
.data | 此段包含可读写的数据。 |
.bss | 此段包含初始值为零的可读写数据。 |
对于上面的链接器脚本代码,首先,ENTRY(boot) 声明 boot 函数是程序的入口点。然后,在 SECTIONS 块中定义每个段的放置位置。*(.text .text.*) 指示将所有文件(*)中的 .text 段和任何以 .text. 开头的段放在该位置。. 符号代表当前地址。它会随着数据的放置(如 *(.text))自动增加。语句 . += 128 * 1024 表示"当前地址前进 128KB"。ALIGN(4) 指示确保当前地址调整到 4 字节边界。
最后,__bss = . 将当前地址分配给符号 __bss。
在 C 语言中,可以使用
extern char symbol_name引用已定义的符号。
最小内核
typedef unsigned char uint8_t;
// 字符类型就是一个无符号的8位比特数据
typedef unsigned int uint32_t;
// 目标架构是32位,所以基础整型大小为32位,指针大小也为32位
typedef uint32_t size_t;
// 定义一些全局变量,用于存放从链接器脚本获得的BSS段和栈顶的地址
extern char __bss[], __bss_end[], __stack_top[];
void* memset(
void *buffer, char c, size_t n
) {
uint8_t* p = (uint8_t*)buffer;
while(n--) {
*p++ = c; // 填充字符c到目标缓冲区buffer中,直到n个字节被填充
};
return buffer;
};
void kernel_main(void) {
memset(
__bss, 0x00, (size_t)__bss_end - (size_t)__bss
); // 将BSS段清零
for(;;); // 无限循环,用于测试
};
__attribute__((section(".text.boot")));
// 告诉编译器将此函数放在.text.boot段
// 该段与物理地址紧密相关,是内核中的关键位置, BIOS启动完就会执行该段的第一行指令
__attribute__((naked));
// 告诉编译器:不要为这个函数生成任何“函数序言(prologue)”和“函数尾声(epilogue)”
// 生成函数序言的操作涉及栈操作,而栈初始化还在下面呢,一运行就真得爆炸
void boot(void) { // 内核启动函数不一定要叫boot
// 入口函数必须用汇编或者位置敏感的C内联汇编写
__asm__ __volatile__ (
// "mov sp, %0\n\t"
// %0在这里用来获取输入的操作数,这里是栈顶地址
"mv sp, %[stack_top]\n"
"bl kernel_main\n"
// bl指令用于跳转到kernel_main函数
// bl本身用于跳转,并保存返回地址到链接寄存器LR中
:
: [stack_top] "r" (__stack_top)
// 将栈顶地址加载到寄存器sp中,并跳转到kernel_main函数
);
};ENTRY(boot)
/* 链接器脚本是这么写的 */
/* GNU ld指令 ENTRY(...) */内核的执行从
boot函数开始,该函数在链接器脚本中指定为入口点。在此函数中,栈指针(sp)被设置为链接器脚本中定义的栈区域的结束地址。
"mov sp, %[stack_top]\n"
boot函数有两个特殊属性。__attribute__((naked))属性告诉编译器不要在函数体前后生成不必要的代码,比如返回指令。这确保内联汇编代码就是确切的函数体。
重要

正常编译一个C函数时,编译器默认函数是在位置不敏感的地方执行,会给函数生成完善的序言和尾声,涉及大量栈操作,而在内核编译中,由于栈初始化还未执行,因此在此时给boot函数生成完整的函数体会因为栈未初始化,sp的值不确定,导致内核运行出错
(正确的汇编指令偶不懂写,毕竟这玩意是RISC-V架构)
boot函数还有__attribute__((section(".text.boot")))属性,它控制函数在链接器脚本中的放置。由于 OpenSBI 简单地跳转到0x80200000而不知道入口点,所以需要将boot函数放在0x80200000。
SECTIONS {
. = 0x80200000;
.text :{
KEEP(*(.text.boot));
*(.text .text.*);
}
...
}接下来使用extern关键字从链接器脚本中获取变量:
// 定义一些全局变量,用于存放从链接器脚本获得的BSS段和栈顶的地址
extern char __bss[], __bss_end[], __stack_top[];单独的 __bss 表示 “.bss 段第 0 字节的值” 而不是 “.bss 段的起始地址”。因此,需要添加 [] 以确保 __bss 返回一个地址同时防止任何不小心的错误(毕竟单独一个8位整数可能装不下地址值)
全局栈初始化后,便可以执行拥有完整函数体的C函数了:
"mv sp, %[stack_top]\n"
"bl kernel_main\n"
void* memset(
void *buffer, char c, size_t n
) {
uint8_t* p = (uint8_t*)buffer;
while(n--) {
*p++ = c; // 填充字符c到目标缓冲区buffer中,直到n个字节被填充
};
return buffer;
};
void kernel_main(void) {
memset(
__bss, 0x00, (size_t)__bss_end - (size_t)__bss
); // 将BSS段清零
for(;;); // 无限循环,用于测试
};使用自行实现的memset对BSS段(Block Started by Symbol)进行清零操作。BSS段用于存储一些全局变量,如果不对其中的全局变量进行置零操作,那么系统真正运行时会因为全局变量的值未初始化而出现无法预测的行为。最后,kernel_main函数进入一个无限循环,内核终止。
运行内核
编译新的内核
新的链接器脚本
#!/bin/bash
set -xue
QEMU=qemu-system-riscv32
# clang 路径和编译器标志
CC=/opt/homebrew/opt/llvm/bin/clang # Ubuntu 用户:使用 CC=clang
CFLAGS="-std=c11 -O2 -g3 -Wall -Wextra --target=riscv32-unknown-elf -fno-stack-protector -ffreestanding -nostdlib"
# 构建内核
$CC $CFLAGS -Wl,-Tkernel.ld -Wl,-Map=kernel.map -o kernel.elf \
kernel.c
# 启动 QEMU
$QEMU -machine virt -bios default -nographic -serial mon:stdio --no-reboot \
-kernel kernel.elf所使用的clang参数如下:
| 选项 | 描述 |
|---|---|
-std=c11 | 使用 C11。 |
-O2 | 启用优化以生成高效的机器代码。 |
-g3 | 生成最大量的调试信息。 |
-Wall | 启用主要警告。 |
-Wextra | 启用额外警告。 |
--target=riscv32-unknown-elf | 编译为 32 位 RISC-V。 |
-fno-stack-protector | 禁用栈保护功能(#31 参考) |
-ffreestanding | 不使用主机环境(你的开发环境)的标准库。 |
-nostdlib | 不链接标准库。 |
-Wl,-Tkernel.ld | 指定链接器脚本。 |
-Wl,-Map=kernel.map | 输出映射文件(链接器分配结果)。 |
-Wl,表示将选项传递给链接器而不是 C 编译器。clang命令执行 C 编译并在内部执行链接器。
第一次内核调试
由于源码里的那个for(;;);,内核进入了无限循环,现在是内核调试time!
输入info registers查看寄存器状态:
(qemu) info registers
CPU#0
V = 0
pc 8020000a -> PC程序计数器,当前所执行的指令的地址
x0/zero 00000000 x1/ra 8000a084 x2/sp 80032f30 x3/gp 00000000 -> 寄存器值
x4/tp 80033000 x5/t0 00000001 x6/t1 00000002 x7/t2 00000000
x8/s0 80032f50 x9/s1 00000001 x10/a0 00000000 x11/a1 87e00000
x12/a2 00000007 x13/a3 00000000 x14/a4 00000001 x15/a5 00000001
x16/a6 00000001 x17/a7 00000005 x18/s2 80200000 x19/s3 00000000
x20/s4 87e00000 x21/s5 00000000 x22/s6 80006800 x23/s7 8001c020
x24/s8 00002000 x25/s9 8002b4e4 x26/s10 00000000 x27/s11 00000000
x28/t3 616d6569 x29/t4 8001a5a1 x30/t5 00000018 x31/t6 00000000提示
└─# ./run.sh
+ QEMU=qemu-system-riscv32
+ CC=clang
+ CFLAGS='-std=c11 -O2 -g3 -Wall -Wextra --target=riscv32-unknown-elf -fno-stack-protector -ffreestanding -nostdlib'
+ clang -std=c11 -O2 -g3 -Wall -Wextra --target=riscv32-unknown-elf -fno-stack-protector -ffreestanding -nostdlib -Wl,-Tkernel.ld -Wl,-Map=kernel.map -o kernel.elf kernel.c
clang: error: unable to execute command: Executable "ld.lld" doesn't exist!
clang: error: ld.lld command failed with exit code 1 (use -v to see invocation)Clang作为LLVM编译器,默认使用lld作为链接编译器
如果出现上面的报错,可能是因为lld一开始没有装上,重新装上就好了
apt install lldpc 8020000apc寄存器的值即当前正在执行的指令的地址
使用objdump(官方教程里来的是llvm-objdump,具体使用的反编译器版本因系统而异)反编译kernel.elf文件确定到底是哪条指令被执行:
└─# llvm-objdump-19 -d kernel.elf
kernel.elf: file format elf32-littleriscv
Disassembly of section .text:
80200000 <memset>:
80200000: ca11 beqz a2, 0x80200014 <memset+0x14>
80200002: 962a add a2, a2, a0
80200004: 86aa mv a3, a0
80200006: 00168713 addi a4, a3, 0x1
8020000a: 00b68023 sb a1, 0x0(a3)
8020000e: 86ba mv a3, a4
80200010: fec71be3 bne a4, a2, 0x80200006 <memset+0x6>
80200014: 8082 ret
80200016 <kernel_main>:
80200016: 802005b7 lui a1, 0x80200
8020001a: 04c58593 addi a1, a1, 0x4c
8020001e: 80200537 lui a0, 0x80200
80200022: 04c50513 addi a0, a0, 0x4c
80200026: 40b50633 sub a2, a0, a1
8020002a: ca01 beqz a2, 0x8020003a <kernel_main+0x24>
8020002c: 00158613 addi a2, a1, 0x1
80200030: 00058023 sb zero, 0x0(a1)
80200034: 85b2 mv a1, a2
80200036: fea61be3 bne a2, a0, 0x8020002c <kernel_main+0x16>
8020003a: a001 j 0x8020003a <kernel_main+0x24>
8020003c <boot>:
8020003c: 80220537 lui a0, 0x80220
80200040: 04c50513 addi a0, a0, 0x4c
80200044: 812a mv sp, a0
80200046: fd1ff06f j 0x80200016 <kernel_main>
8020004a: 8082 ret出问题了
看起来结果不太一样,我的PC值显示内核好像卡在了memset的函数序言里:


停在*p = c那一段:
void* memset(
void *buffer, char c, size_t n
) {
uint8_t* p = (uint8_t*)buffer;
while(n--) {
*p++ = c; // 填充字符c到目标缓冲区buffer中,直到n个字节被填充
// *p = c 卡这里了
};
return buffer;
};void kernel_main(void) {
memset(
__bss, 0x00, (size_t)__bss_end - (size_t)__bss
); // 将BSS段清零
for(;;); // 无限循环,用于测试
};理论上来说memset跑完就该到for的
一开始以为是__bss大小错误配置,但是不论是反编译代码还是直接查看.map文件,结果都表明__bss和__bss_end大小相等,程序直接都进不到memset的循环里
└─# grep __bss kernel.map
8020004c 8020004c 0 1 __bss = .
8020004c 8020004c 0 1 __bss_end = .
(看前六条指令)
但qemu控制台又显示内核停在了memset函数体里,也就是说还是进入到了memset的循环里并且退不出来
现在让我们回顾寄存器值列表:
mhartid 00000000
mstatus 80006180
mstatush 00000000
hstatus 00000000
vsstatus 00000000
mip 00000000
mie 00000008
mideleg 00001666
hideleg 00000000
medeleg 00f0b509
hedeleg 00000000
mtvec 80000530
stvec 80200000
vstvec 00000000
mepc 80200000
sepc 8020000a
vsepc 00000000
mcause 00000007
scause 00000007
...注意下面的两个Cause Register:
mcause 00000007
scause 00000007提示
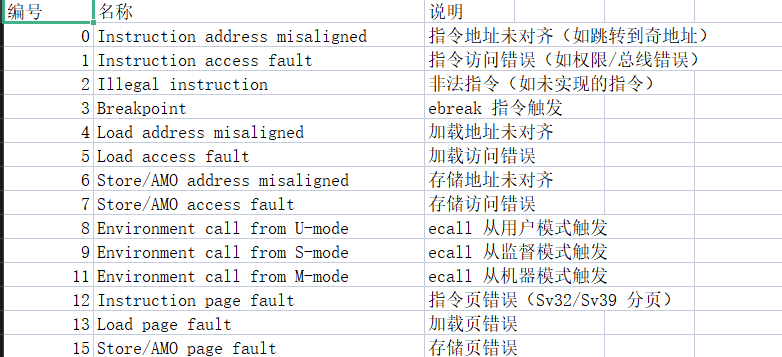
在 RISC-V 架构中,mcause 和 scause 是两个非常关键的 异常/中断原因寄存器(Cause Registers),它们分别属于:
mcause→ Machine Mode(机器模式)scause→ Supervisor Mode(监督模式)
二者共享的错误码如下:
两个寄存器的值均为7,也就是存储访问错误
CPU在监督模式发生异常时会去stvec寻找处理异常/中断的指令地址;而在机器模式出现异常时去找mtvec寻找处理异常的指令地址;两者都会在跳转中断时设置spec或mpec寄存器的值: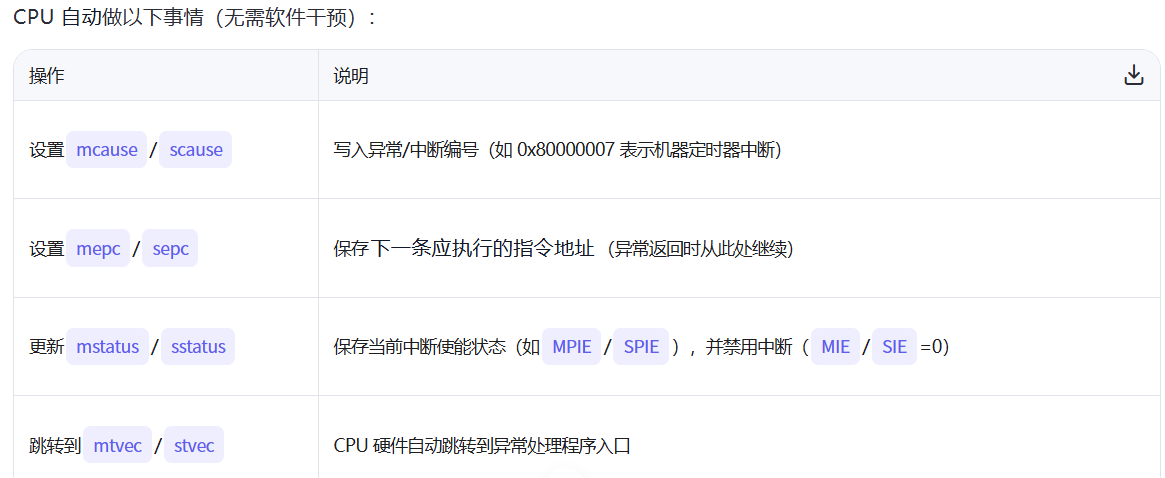
而在这里,我的stvec的值为:
mtvec 80000530
stvec 80200000嗯,0x80200000,这玩意是……我的.text.boot段地址!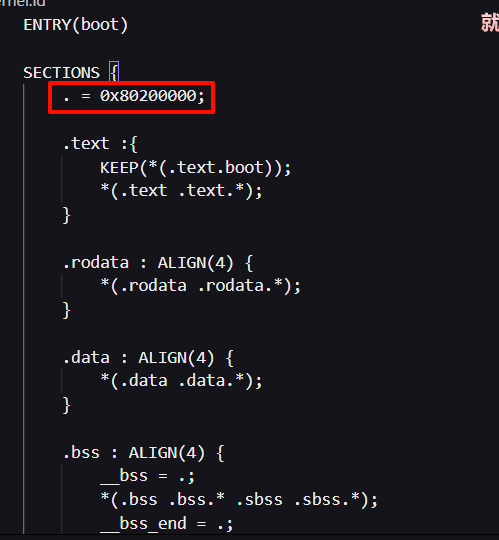
换句话说,内核执行到*p = c也就是8020000a: 23 80 b6 00 sb a1, 0(a3)这一字节存储操作时,发生了存储访问错误,CPU于是从stvec获得处理异常中断的指令地址,也就是text段,然后又从头开始执行栈初始化和memset函数,又发生异常,又跳回text段头……
那么a1和a3现在是什么情况呢?
x11/a1 87e00000
x12/a2 00000007
x13/a3 00000000CPU正试图向内存地址 0x0 写入数据。这是一个受保护的地址,任何写入操作都会立即导致一次“访问错误”异常——这完美地对应了scause为7的错误!
提示
添加异常处理代码,并且显式设置stvec寄存器的值,然后重新运行,观察寄存器,特别是pc和异常处理链寄存器的值:
V = 0
pc 80200000
mtvec 80000530
stvec 80200000
vstvec 00000000
mepc 80200000
sepc 00000000
vsepc 00000000
mcause 00000003
scause 00000000scause变成了0,但mcause被设置为了3,即非法指令:
(Qwen给的,好像对不太上)
总之
- 这意味着,CPU在M-Mode下,尝试执行一条它不认识或者不允许的指令。
- 再看scause (Supervisor Cause Register),它的值是0。这说明S-Mode下没有任何异常发生
而
mepc 80200000
sepc 00000000- mepc 是 Machine Exception Program Counter。它记录了导致M-Mode异常的那条指令的地址。
- 地址80200000正是内核代码的起始地址,也就是
handle_trap函数
那……为啥handle_trap在前面呢?在kernel.ld中,下面的代码:
ENTRY(boot)
SECTIONS {
. = 0x80200000;
.text :{
KEEP(*(.text.boot));
*(.text .text.*);
}
}本应将boot函数放在text.text汇编指令段之前,但现在居然是handle_trap在前面。更进一步地,之前的反编译结果中,boot函数也从来没有置于段首过\
问题确认
至此,问题已经明晰
病因:链接器布局错误
- 由于C文件中函数的物理顺序,链接器没有遵守KEEP(*(.text.boot))的指示,把memset(或者handle_trap)放在了二进制文件的最开头,也就是0x80200000这个地址。
- boot函数被错误地放在了后面。
直接后果:CPU从错误的地方开始
- OpenSBI完成了它的工作,然后忠实地跳转到它被告知的内核入口地址:0x80200000。
- CPU满心以为这里是boot代码,但它看到的却是memset的第一条指令。
症状:立即崩溃
- CPU(此时仍在M-Mode)尝试执行memset的代码。但此时的环境是完全错误的:
- 权限模式不对(应该是S-Mode)。
- 栈指针sp没有被boot函数设置,指向一个无效或未知的地方。
- a0, a1, a2等参数寄存器里是OpenSBI留下的“垃圾”,对memset来说毫无意义。
- 这一切导致CPU在执行memset的第一条或第二条指令时就立即触发了非法指令或访问错误异常。
- CPU(此时仍在M-Mode)尝试执行memset的代码。但此时的环境是完全错误的:
我们观察到的现象
- 我们用调试器暂停,看到的就是这次崩溃的“遗骸”:mepc指向memset的开头,mcause记录着崩溃的原因。
解决方法
为了解决这一问题,我们需要手动将boot函数以及其__attribute__属性,必要的变量声明都移到文件开头(在8086架构的汇编程序编辑中已有这种操作,将段物理意义上地放置在不同地方来改变段的起始地址)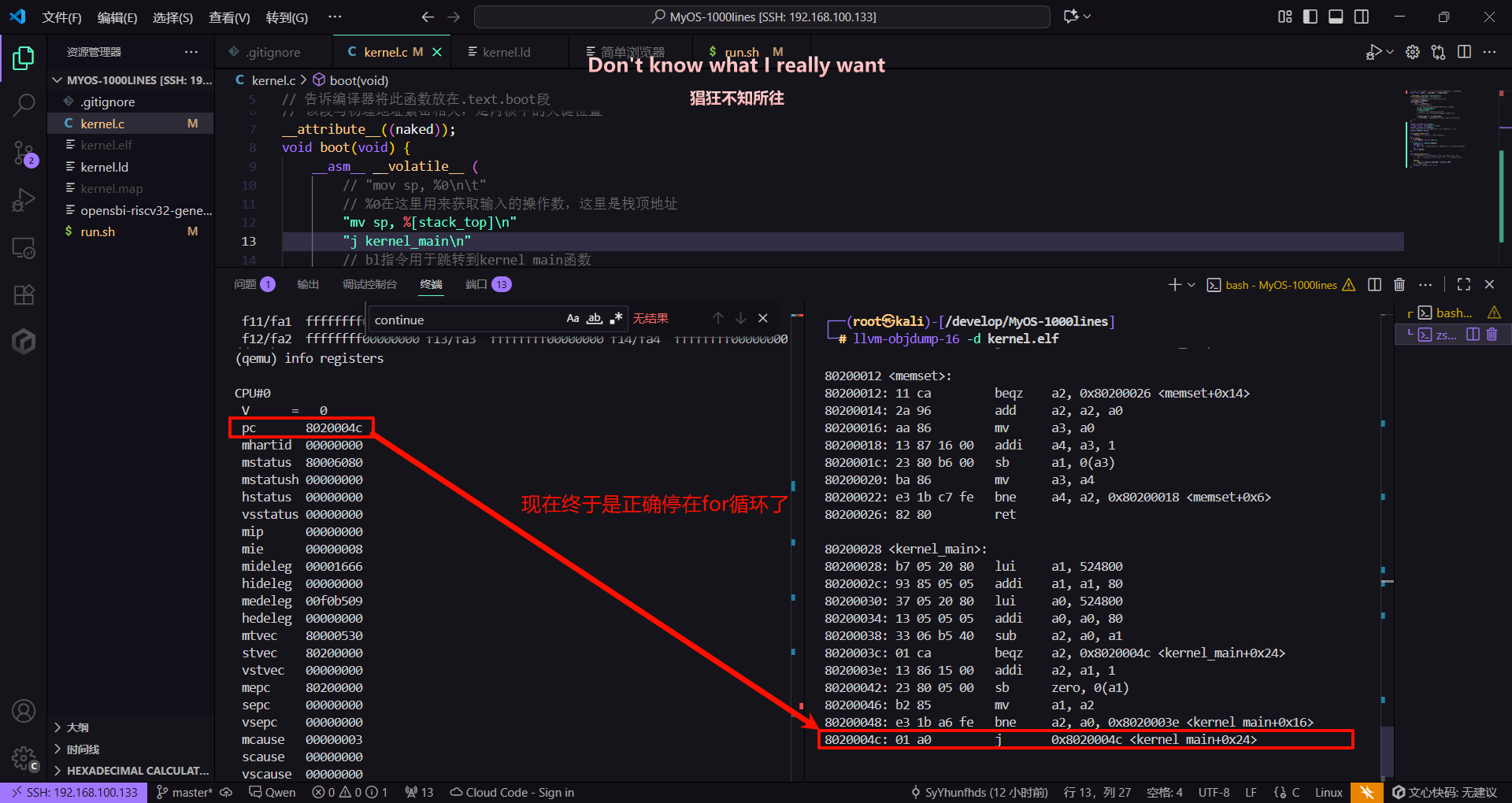
现在的kernel.c如下:
// 定义一些全局变量,用于存放从链接器脚本获得的BSS段和栈顶的地址
extern char __bss[], __bss_end[], __stack_top[];
__attribute__((section(".text.boot")));
// 告诉编译器将此函数放在.text.boot段
// 该段与物理地址紧密相关,是内核中的关键位置
__attribute__((naked));
void boot(void) {
__asm__ __volatile__ (
// "mov sp, %0\n\t"
// %0在这里用来获取输入的操作数,这里是栈顶地址
"mv sp, %[stack_top]\n"
"j kernel_main\n"
// bl指令用于跳转到kernel_main函数
// bl本身用于跳转,并保存返回地址到链接寄存器LR中
:
: [stack_top] "r" (__stack_top)
// 将栈顶地址加载到寄存器sp中,并跳转到kernel_main函数
);
};
typedef unsigned char uint8_t;
// 字符类型就是一个无符号的8位比特数据
typedef unsigned int uint32_t;
// 目标架构是32位,所以基础整型大小为32位,指针大小也为32位
typedef uint32_t size_t;
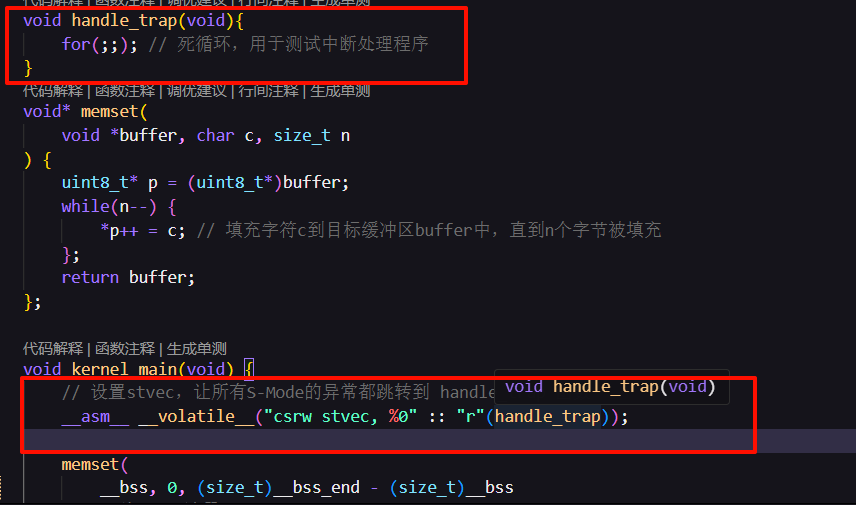
void handle_trap(void){
for(;;); // 死循环,用于测试中断处理程序
}
void* memset(
void *buffer, char c, size_t n
) {
uint8_t* p = (uint8_t*)buffer;
while(n--) {
*p++ = c; // 填充字符c到目标缓冲区buffer中,直到n个字节被填充
};
return buffer;
};
void kernel_main(void) {
// 设置stvec,让所有S-Mode的异常都跳转到 handle_trap 函数
// __asm__ __volatile__("csrw stvec, %0" :: "r"(handle_trap));
memset(
__bss, 0, (size_t)__bss_end - (size_t)__bss
); // 将BSS段清零
for(;;); // 无限循环,用于测试
};提示
QEMU的virt虚拟平台和它搭载的OpenSBI固件非常“友好”,它在跳转到0x80200000之前,会自动替我们完成从M-Mode到S-Mode的切换,无需使用mret等指令进行手动切换。
下面是一个更完善更有鲁棒性的boot函数体:
void boot(void) {
__asm__ __volatile__ (
// 1. 关闭分页,设置前一个权限级别为S-Mode
"li t0, (1 << 11) | (1 << 7)\n\t"
"csrw mstatus, t0\n\t"
// 2. 设置 mret 指令执行后要跳转到的地址 (kernel_main)
"la t0, kernel_main\n\t"
"csrw mepc, t0\n\t"
// 3. 设置S-Mode的栈指针
"mv sp, %[stack_top]\n\t"
// 4. 使用 mret 指令,CPU会自动切换到S-Mode并跳转到 mepc 指定的地址
"mret\n\t"
:
: [stack_top] "r" (__stack_top)
);
}提示
此时mcause值仍然为3,这可能是之前的残留值,不用理会
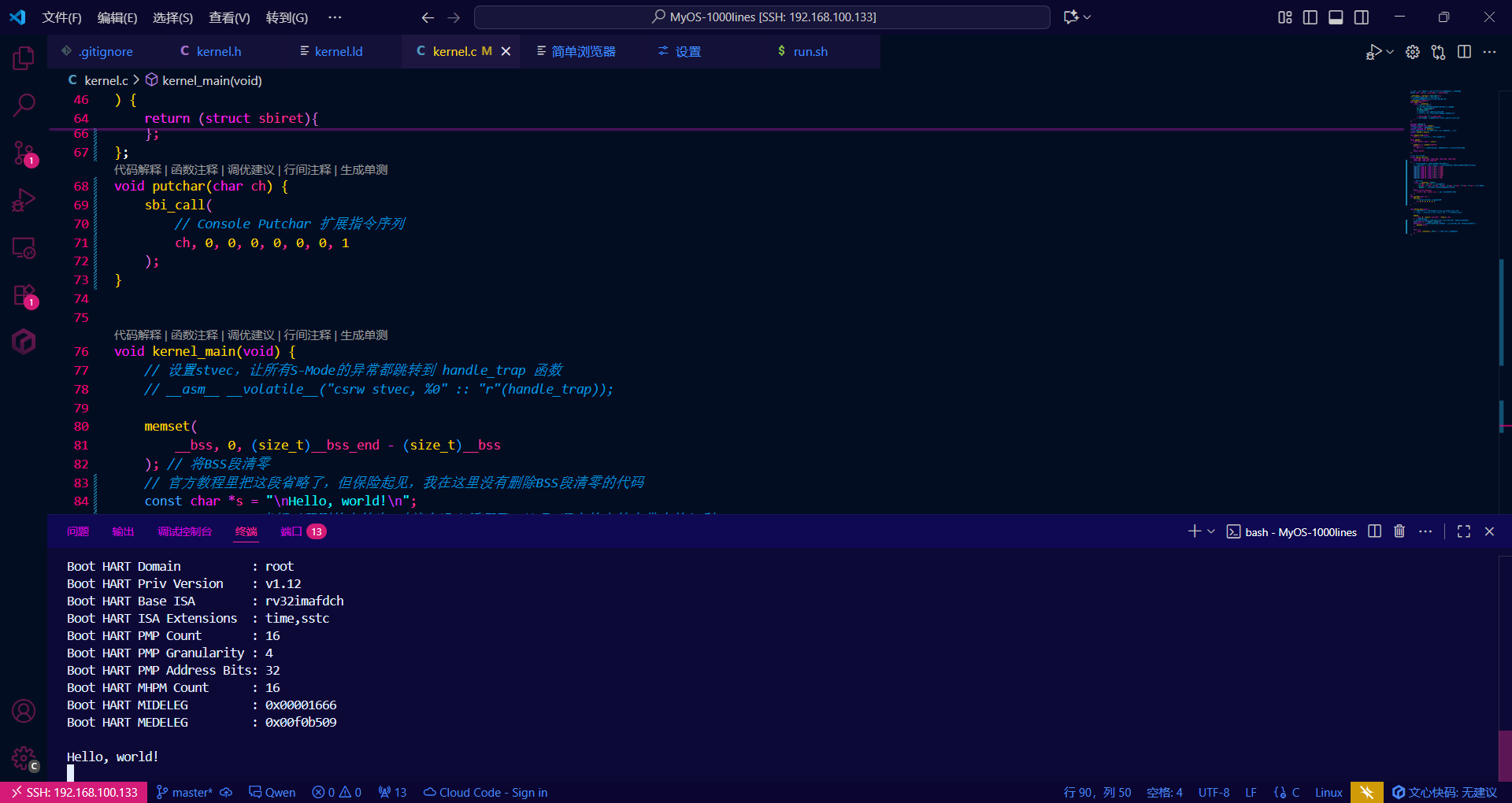
Hello World
在终于把内核跑起来后,我们终于可以摸摸系统API了
在上一章中,我们了解到SBI是一个针对操作系统的API
提示
监管者二进制接口(Supervisor Binary Interface,SBI)是一个面向操作系统内核的 API,它定义了固件(OpenSBI)向操作系统提供的功能。
一个著名的 SBI 实现是 OpenSBI。在 QEMU 中,默认启动 OpenSBI,执行特定硬件的初始化,然后引导内核。
要调用 SBI 使用其功能,我们使用
ecall指令
(运行效果)
// kernel.c
// 定义一些全局变量,用于存放从链接器脚本获得的BSS段和栈顶的地址
extern char __bss[], __bss_end[], __stack_top[];
__attribute__((section(".text.boot")));
// 告诉编译器将此函数放在.text.boot段
// 该段与物理地址紧密相关,是内核中的关键位置
__attribute__((naked));
void boot(void) {
__asm__ __volatile__ (
// "mov sp, %0\n\t"
// %0在这里用来获取输入的操作数,这里是栈顶地址
"mv sp, %[stack_top]\n"
"j kernel_main\n"
// bl指令用于跳转到kernel_main函数
// bl本身用于跳转,并保存返回地址到链接寄存器LR中
:
: [stack_top] "r" (__stack_top)
// 将栈顶地址加载到寄存器sp中,并跳转到kernel_main函数
);
};
#include "kernel.h"
/*
// kernel.h的内容放在这
#pragma once
// 指示编译器仅包含一次该头文件
struct sbiret
{
// data
long error;
long value;
};
*/
typedef unsigned char uint8_t;
// 字符类型就是一个无符号的8位比特数据
typedef unsigned int uint32_t;
// 目标架构是32位,所以基础整型大小为32位,指针大小也为32位
typedef uint32_t size_t;
void* memset(
void *buffer, char c, size_t n
) {
uint8_t* p = (uint8_t*)buffer;
while(n--) {
*p++ = c; // 填充字符c到目标缓冲区buffer中,直到n个字节被填充
};
return buffer;
};
// 更多仿C标准函数
struct sbiret sbi_call(
long arg0, long arg1, long arg2, long arg3, long arg4,
long arg5, long eid, long fid
) {
// register指令建议编译器将变量放置在寄存器中
// 而register + __asm__("value") = value_的写法将使编译器将变量与寄存器强制绑定
register long a0 __asm__("a0") = arg0;
register long a1 __asm__("a1") = arg1;
register long a2 __asm__("a2") = arg2;
register long a3 __asm__("a3") = arg3;
register long a4 __asm__("a4") = arg4;
register long a5 __asm__("a5") = arg5;
register long a6 __asm__("a6") = eid;
register long a7 __asm__("a7") = fid;
// 调用ecall
__asm__ __volatile__("ecall"
: "=r"(a0), "=r"(a1) // 输入的寄存器
: "r"(a0), "r"(a1), "r"(a2), "r"(a3), "r"(a4), "r"(a5), "r"(a6), "r"(a7) // 输出寄存器
: "memory" // 告诉编译器,这条汇编指令会修改内存
);
return (struct sbiret){
.error = a0, .value = a1, // C语言的结构体赋值写法
};
};
void putchar(char ch) {
sbi_call(
// Console Putchar 扩展指令序列
ch, 0, 0, 0, 0, 0, 0, 1
);
}
void kernel_main(void) {
// 设置stvec,让所有S-Mode的异常都跳转到 handle_trap 函数
// __asm__ __volatile__("csrw stvec, %0" :: "r"(handle_trap));
memset(
__bss, 0, (size_t)__bss_end - (size_t)__bss
); // 将BSS段清零
// 官方教程里把这段省略了,但保险起见,我在这里没有删除BSS段清零的代码
const char *s = "\nHello, world!\n";
while(*s) { // 当解引用到的字符为0时就会退出循环了,这是C语言的字符串带来的便利
putchar(*s++);
};
for(;;) {
__asm __volatile__("wfi"); // 等待中断,进入休眠状态
};
};新添加了一个sbi_call函数
struct sbiret sbi_call(
long arg0, long arg1, long arg2, long arg3, long arg4,
long arg5, long fid, long eid
) {
// register指令建议编译器将变量放置在寄存器中
// 而register + __asm__("value") = value_的写法将使编译器将变量与寄存器强制绑定
register long a0 __asm__("a0") = arg0;
register long a1 __asm__("a1") = arg1;
register long a2 __asm__("a2") = arg2;
register long a3 __asm__("a3") = arg3;
register long a4 __asm__("a4") = arg4;
register long a5 __asm__("a5") = arg5;
register long a6 __asm__("a6") = fid;
register long a7 __asm__("a7") = eid;
// 调用ecall
__asm__ __volatile__("ecall"
: "=r"(a0), "=r"(a1) // 输入的寄存器
: "r"(a0), "r"(a1), "r"(a2), "r"(a3), "r"(a4), "r"(a5), "r"(a6), "r"(a7) // 输出寄存器
: "memory" // 告诉编译器,这条汇编指令会修改内存
);
return (struct sbiret){
.error = a0, .value = a1, // C语言的结构体赋值写法
};
};这个函数设计用于按照 SBI 规范调用 OpenSBI:
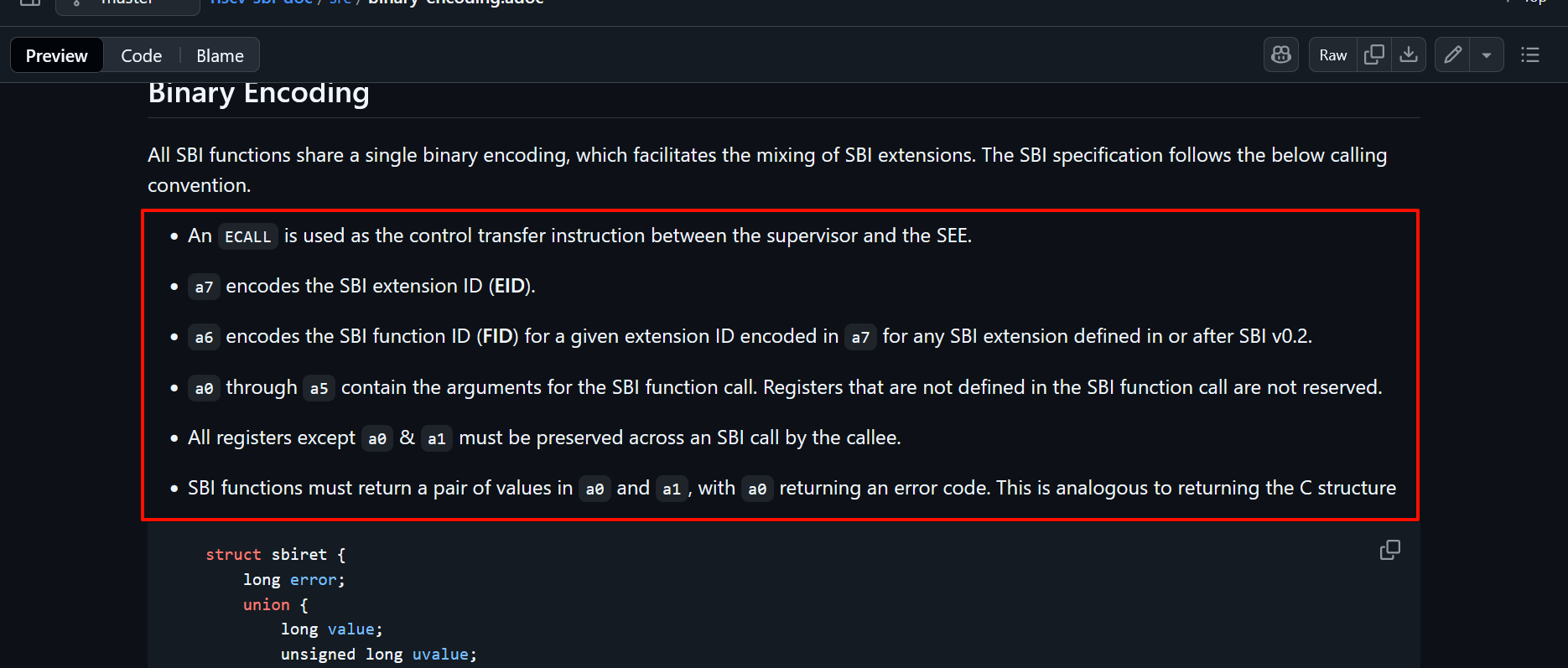
SBI调用约定
所有 SBI 函数共享一个统一的二进制编码,这便于混合使用 SBI 扩展。SBI 规范遵循以下调用约定:
- 使用
ECALL作为管理模式和 SEE 之间的控制转移指令。 a7编码 SBI 扩展 ID(EID)- 对于在 SBI v0.2 中或之后定义的任何 SBI 扩展,
a6编码给定扩展 ID 的 SBI 功能 ID(FID) - 除了
a0和a1外,所有寄存器必须在被调用方的 SBI 调用过程中保持不变。 - SBI 函数必须在
a0和a1中返回一对值,其中a0返回错误代码。这类似于返回 C 结构体
struct sbiret {
long error;
long value;
};提示
_"除了
a0和a1外,所有寄存器必须在被调用方的 SBI 调用过程中保持不变"意味着被调用方(OpenSBI 端)不得更改___除了**a0和a1之外的寄存器值。换句话说,从内核的角度来看,可以保证调用后寄存器(a2到a7)将保持不变。
一点小发现
注意到sbi_call使用了两个通用寄存器作为输出数,八个寄存器作为输入数——
根据RISC-V 整数调用规范所示,寄存器a0-a7将被用于存储参数,其中,最开始的两个寄存器a0-a1被用于返回值,因此,在sbi_call中,a0和a1不仅是ecall的参数,亦应该是其返回值
sbi_call函数是对ecall指令的通用封装,sbi_call不仅仅要被putchar所使用,因此,sbi_call必须在C语言层面帮忙传递ecall可能用到的任何参数。这是sbi_call函数能够“接收”到8个参数的底层原因。
ecall 指令是软件向更底层环境(在这里是S-Mode内核向M-Mode的OpenSBI固件)请求服务的“门铃”。
但光按门铃不够,您还需要提交一张“服务申请表”,告诉固件您具体想要什么服务。
RISC-V SBI规范就是这张“服务申请表”的格式标准。
因此,官方教程里的sbi_call函数应该是这样设计的:
- 设计目标:创建一个通用的C函数,使其能够调用任何SBI服务,而不仅仅是
sbi_console_putchar。 - 遵守C的规则:为了成为一个合法的C函数,它必须能接收C语言传递过来的参数。根据RISC-V调用约定,最多可以方便地通过寄存器传递8个参数
(a0到a7)。因此,函数签名被设计为sbi_call(arg0, arg1, ..., arg7)。 - 遵守SBI的规则:这个函数的核心任务是执行
ecall。SBI规范恰好使用a0到a7这同一批寄存器来定义其服务。 - 完美的桥梁:
sbi_call的实现成了一个绝妙的“桥梁”。它的汇编代码几乎什么都不用做!编译器已经根据C调用约定把8个C参数放到了a0-a7中。而这8个寄存器恰好就是SBI规范用来定义服务的寄存器。sbi_call的汇编代码只需要执行一条ecall指令即可。
现在,让我们看到putchar函数实际用到的EID和FID,规范来说应该分别设置为SBI_CONSOLE_PUTCHAR和SBI_LEGACY_CONSOLE_PUTCHAR(都是1),但官方教程里的话FID是0,EID是1
putchar函数在OpenSBI层面的行为(规范版本)
- 固件检查 a7 (是1) 和 a6 (是1),确认服务是sbi_console_putchar。
- 根据sbi_console_putchar的内部定义,它只需要一个参数,该参数从a0读取。
- 固件读取a0的值('A'),并将其输出到终端。
- 固件完全忽略 a1 至 a5 寄存器的内容。
这又是为什么呢?
根据RISC-V EID历史遗留规范,EID=1对应Console Putchar功能,该功能接受int ch参数,成功则返回long类型的0,或者未实现错误码
Write data present in ch to debug console.
Unlikesbi_console_getchar(), this SBI call will block if there remain any pending characters to be transmitted or if the receiving terminal is not yet ready to receive the byte. However, if the console doesn’t exist at all, then the character is thrown away.
This SBI call returns 0 upon success or an implementation specific negative error code.
因此,官方教程的putchar使用历史遗留的EID规范调用了RISC-V的Console PutcharSBI接口
SBI EID 过去VS现在
| Function Name | SBI Version | FID | EID | Replacement EID | EID含义 |
|---|---|---|---|---|---|
| sbi_set_timer | 0.1 | 0 | 0x00 | 0x54494D45 | TIME |
| sbi_console_putchar | 0.1 | 0 | 0x01 | 0x4442434E | DBCN |
| sbi_console_getchar | 0.1 | 0 | 0x02 | 0x4442434E | DBCN |
| sbi_clear_ipi | 0.1 | 0 | 0x03 | N/A | |
| sbi_send_ipi | 0.1 | 0 | 0x04 | 0x735049 | sPI |
| sbi_remote_fence_i | 0.1 | 0 | 0x05 | 0x52464E43 | RFNC |
| sbi_remote_sfence_vma | 0.1 | 0 | 0x06 | 0x52464E43 | RFNC |
| sbi_remote_sfence_vma_asid | 0.1 | 0 | 0x07 | 0x52464E43 | RFNC |
| sbi_shutdown | 0.1 | 0 | 0x08 | 0x53525354 | SRST |
| RESERVED | 0x09-0x0F |
回到正题
函数体开头的寄存器初始化,使用的
register和__asm__("register name")要求编译器将值放在指定的寄存器中。
这在系统调用调用过程中是一个常见用法(例如,Linux 系统调用调用过程)
准备好参数后,在内联汇编中执行ecall指令。当这个指令被调用时,CPU 的执行模式从内核模式(S-Mode)切换到 OpenSBI 模式(M-Mode),并调用 OpenSBI 的处理程序。完成后,它切回内核模式,并在ecall指令之后继续执行。
当应用程序调用内核(系统调用)时也使用ecall指令。这个指令的行为类似于对更高权限 CPU 模式的函数调用。
选自官方教程
Hello World 的生命周期:
当调用 SBI 时,字符将按以下方式显示:
- 内核执行
ecall指令。CPU 跳转到 M 模式陷阱处理程序(mtvec寄存器),这是由 OpenSBI 在启动期间设置的。 - 保存寄存器后,调用用 C 编写的陷阱处理程序。
- 根据
eid,调用相应的 SBI 处理函数。 - 设备驱动程序(用于 8250 UART(Wikipedia))将字符发送到 QEMU。
- QEMU 的 8250 UART 模拟实现接收字符并将其发送到标准输出。
- 终端模拟器显示字符。
也就是说,调用Console Putchar函数根本不是魔法 - 它只是使用了在 OpenSBI 中实现的设备驱动程序!
printf函数
这里跟随官方教程,只实现打印字符串参数、打印十进制、打印十六进制三个功能
// common.h
#pragma once
// 只是把Clang提供的内置变量重命名一下
#define va_list __builtin_va_list // 可变参数列表
#define va_start __builtin_va_start
// 初始化 va_list,使其指向第一个可变参数
// 必须在访问任何可变参数前调用。它根据最后一个固定参数的位置计算出第一个可变参数的地址
#define va_end __builtin_va_end
// 清空va_list对象,以便它可以被重新初始化以指向另一个参数列表
#define va_arg __builtin_va_arg
// 返回当前参数的值,并将内部指针移动到下一个参数的位置
// va_arg(args, type) // 传入的参数必须与声明的类型兼容,否则会出现未定义行为
// 下面是AI自动出来的,想来运行起来也没为什么问题,就不打算删了
#define va_copy __builtin_va_copy
// 函数定义在这里,实现在common.c那边
void printf(const char *format, ...);// common.c
#include "common.h"
void putchar(char ch); // 声明在这里,实现的话在kernel.c里
void printf(const char *format, ...) {
va_list va_args; // 定义一个可变参数列表
va_start (va_args, format); // 初始化可变参数列表, 使其指向format字符数组的第一个参数
while (*format != '\0') {
if (*format == '%') {
// 这里只实现%d %x %s三种参数格式
format++; // 跳过%占位符
switch (*format) {
case 'd':
// 逐位计算数字
int value = va_arg(va_args, int); // 获取下一个参数
unsigned int absolute_v = value < 0 ? -value : value;
// 这里官方教程给出的是magnitude,意为“大小”,这里用的是"绝对值"
if (value < 0){
putchar('-'); // 打印负号
}
// 计算最高位大小
unsigned divisor = 1;
while(absolute_v / divisor >= 10) {
divisor *= 10;
}
// 逐位求出余数
while (divisor > 0){
putchar((absolute_v / divisor) + '0');
absolute_v %= divisor; // 舍去最高位,进入下一个循环
divisor /= 10;
}
break;
case 'x':
unsigned int value = va_arg(va_args, unsigned int); // 获取下一个参数
for (int i = 28; i >= 0; i -= 4) {
unsigned int digit = (value >> i) & 0xF; // 取四位中的一位,并转为十六进制字符
if(digit < 10){
putchar('0' + digit);
}
else{
putchar('a' + digit - 10);
}
}
break;
case 's':
const char *string = va_arg(va_args, const char *); // 获取下一个参数
while(*string){
putchar(*string++);
}
// 这里AI给出了递归调用printf的版本,但AI没有考虑到参数里也有%占位符的情况
// printf(va_arg(va_args, const char *));
break;
// 另外两种情况
case '%': // 处理连续的%%占位符,即打印'%'字符本身
putchar('%');
break; // 跳出占位符处理分支,继续外层循环
case '\0':
putchar('%'); // 打印占位符本身
goto end;
}
}
else {
putchar(*format); // 不是占位符,直接打印出来
}
format++; // 遍历下一个字符
}
end:
va_end(va_args); // 清理可变参数列表
};// kernel.c部分
void kernel_main(void) {
memset(
__bss, 0, (size_t)__bss_end - (size_t)__bss
); // 将BSS段清零
// 官方教程里把这段省略了,但保险起见,我在这里没有删除BSS段清零的代码
printf("Hello, world!\n");
printf("1 + 2 = %d\n%x", 1 + 2, 0x1234abcd);
};
printf函数的实现细节已在代码注释中给出(我的实现与官方实现有些许出入,请以自身情况为准)。官方教程亦有解释,这里不多做赘述
va_list和相关宏在 C 标准库的<stdarg.h>中定义。在本书中,我们直接使用编译器内置功能,而不依赖标准库。
#pragma once
#define va_list __builtin_va_list // 可变参数列表
#define va_start __builtin_va_start
// 初始化 va_list,使其指向第一个可变参数
// 必须在访问任何可变参数前调用。它根据最后一个固定参数的位置计算出第一个可变参数的地址
#define va_end __builtin_va_end
// 清空va_list对象,以便它可以被重新初始化以指向另一个参数列表
#define va_arg __builtin_va_arg
// 返回当前参数的值,并将内部指针移动到下一个参数的位置
// va_arg(args, type) // 传入的参数必须与声明的类型兼容,否则会出现未定义行为相关信息
但是给编译器内置变量改一个名也是stdarg.h的一种经典实现
官方教程这里选用的宏重命名va_list、va_end等和stdarg.h的一致
提示
可变参数的实现高度依赖于平台 ABI(应用程序二进制接口):
- 参数是通过栈传递还是寄存器?
- 寄存器用完后如何回退到栈?
- 对齐要求是什么?
- 如何处理浮点/整数混合参数?
这些细节无法用纯 C 实现,必须由编译器在知道目标平台的情况下生成特定代码。因此,编译器提供__builtin_va_*作为“魔法原语”,标准库<stdarg.h>再用宏包装成标准接口。
在实现了printf后,我们还需要修改编译脚本run.sh,将common.c也加入编译目标
...
# 构建内核
$CC $CFLAGS -Wl,-Tkernel.ld -Wl,-Map=kernel.map -o kernel.elf \
kernel.c common.c # 编译目标
...现在让我们试试……唉?
└─# ./run.sh
+ QEMU=qemu-system-riscv32
+ CC=clang
+ CFLAGS='-std=c11 -O2 -g3 -Wall -Wextra --target=riscv32-unknown-elf -fno-stack-protector -ffreestanding -nostdlib'
+ clang -std=c11 -O2 -g3 -Wall -Wextra --target=riscv32-unknown-elf -fno-stack-protector -ffreestanding -nostdlib -Wl,-Tkernel.ld -Wl,-Map=kernel.map -o kernel.elf kernel.c common.c
common.c:16:21: warning: label followed by a declaration is a C23 extension [-Wc23-extensions]
16 | int value = va_arg(va_args, int); // 获取下一个参数
| ^
common.c:36:34: error: redefinition of 'value' with a different type: 'unsigned int' vs 'int'
36 | unsigned int value = va_arg(va_args, unsigned int); // 获取下一个参数
| ^
common.c:16:25: note: previous definition is here
16 | int value = va_arg(va_args, int); // 获取下一个参数
| ^
common.c:36:21: warning: label followed by a declaration is a C23 extension [-Wc23-extensions]
36 | unsigned int value = va_arg(va_args, unsigned int); // 获取下一个参数
| ^
common.c:48:21: warning: label followed by a declaration is a C23 extension [-Wc23-extensions]
48 | const char *string = va_arg(va_args, const char *); // 获取下一个参数
| ^
3 warnings and 1 error generated.噢,原来是因为case分支的多行代码需要用大括号包起来
现在可以了
玩点花活
有色输出
鉴于编译脚本中的mon:stdio参数会将shell的标准输入输出接入到QEMU虚拟机中,因此QEMU会忠实地输出内核和程序产生的文本——这是一个系统无关的操作,给它什么就输出什么,所以理论上来说,给内核写入ANSI序列,QEMU会完整地输出原始ANSI序列,shell渲染ANSI序列,大功告成
绝大多数用于设置样式的序列都遵循以下格式,即 CSI (Control Sequence Introducer):\x1b[ + 参数 + 命令
\x1b: 这是 ESC 字符在 C 语言中的标准表示方法(ASCII 码 27,十六进制 1B)。这是所有序列的“唤醒”信号。[: 这是控制序列的引导符,紧跟在ESC之后。参数: 这是一个或多个由分号 ; 分隔的数字字符串。这些数字决定了具体要设置什么样式。如果省略,通常默认为0或1。命令: 一个字母,决定了这次操作的类型。对于设置文本样式,这个命令永远是m。
这个\x1b[...m序列在官方文档中被称为SGR (Select Graphic Rendition)。
基于CSI设计的ANSI 转义序列 (ANSI Escape Sequences) 是一套标准的、跨平台的指令集,用于控制终端的光标、颜色和其他显示选项。这些指令不是普通的可见字符,而是一些以 ESC (Escape) 字符开头的特殊字符串。当宿主机的终端程序(如 QEMU 连接的终端)接收到这些序列时,它不会把它们显示出来,而是会把它们解释为命令来改变后续文本的显示方式
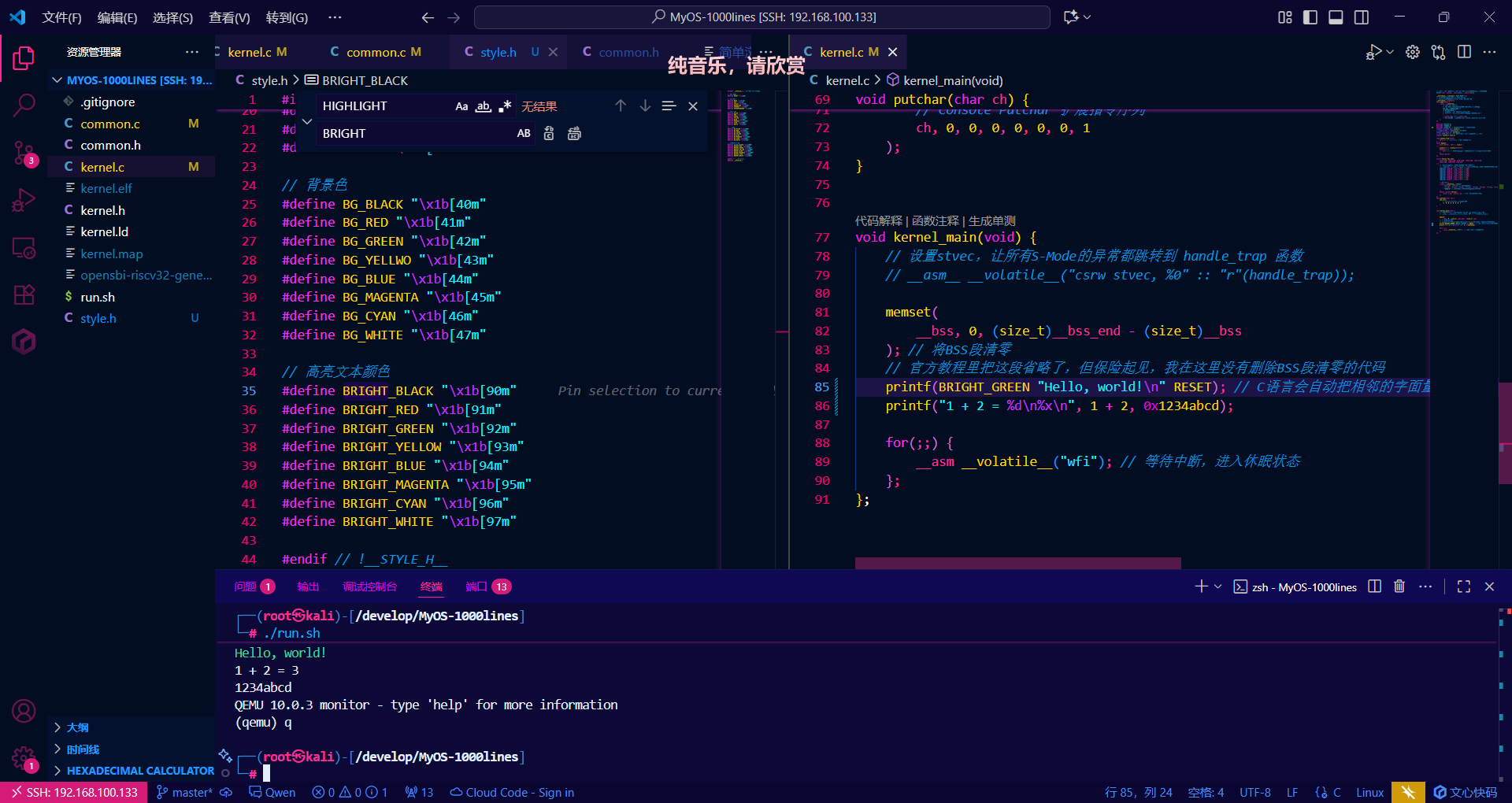
效果符合预期
#ifndef __STYLE_H__ // 防止重复包含头文件
// 样式重置
#define RESET "\x1b[0m"
// 文本样式
#define BOLD "\x1b[1m"
#define DIM "\x1b[2m"
#define ITALIC "\x1b[3m"
#define UNDERLINE "\x1b[4m"
#define INVERSE "\x1b[7m"
#define STRIKETHROUGH "\x1b[9m"
// 文本颜色
#define BLACK "\x1b[30m"
#define RED "\x1b[31m"
#define GREEN "\x1b[32m"
#define YELLOW "\x1b[33m"
#define BLUE "\x1b[34m"
#define MAGENTA "\x1b[35m"
#define CYAN "\x1b[36m"
#define WHITE "\x1b[37m"
// 背景色
#define BG_BLACK "\x1b[40m"
#define BG_RED "\x1b[41m"
#define BG_GREEN "\x1b[42m"
#define BG_YELLWO "\x1b[43m"
#define BG_BLUE "\x1b[44m"
#define BG_MAGENTA "\x1b[45m"
#define BG_CYAN "\x1b[46m"
#define BG_WHITE "\x1b[47m"
// 高亮文本颜色
#define BRIGHT_BLACK "\x1b[90m"
#define BRIGHT_RED "\x1b[91m"
#define BRIGHT_GREEN "\x1b[92m"
#define BRIGHT_YELLOW "\x1b[93m"
#define BRIGHT_BLUE "\x1b[94m"
#define BRIGHT_MAGENTA "\x1b[95m"
#define BRIGHT_CYAN "\x1b[96m"
#define BRIGHT_WHITE "\x1b[97m"
// 其他样式
// 闪烁等
#define FLASH "\x1b[5m" // 闪烁 // 终端不一定支持
#define CONCEALED "\x1b[8m" // 隐藏
#define CROSSED_OUT "\x1b[9m" // 删除线
#define FRAMED "\x1b[51m" // 边框
#define ENCIRCLED "\x1b[52m" // 圆圈
#define OVERLINED "\x1b[53m" // 覆盖线
#define FRAMED_ENCIRCLED "\x1b[54m" // 边框圆圈
#define OVERLINED_ENCIRCLED "\x1b[55m" // 覆盖线圆圈
#define BOLD_OVERLINED "\x1b[56m"
#define BOLD_ENCIRCLED "\x1b[57m"
#define BOLD_ENCIRCLED_OVERLINED "\x1b[58m"
#define BOLD_FRAMED "\x1b[59m"
#define BOLD_FRAMED_ENCIRCLED "\x1b[60m"
#define BOLD_OVERLINED_ENCIRCLED "\x1b[61m"
#define BOLD_FRAMED_ENCIRCLED_OVERLINED "\x1b[62m"
#define CIRCLE "\x1b[63m" // 圆圈
#define DOUBLE_FRAMED "\x1b[64m" // 双边框
#define INVERSED "\x1b[73m" // 反转前景色和背景色
#endif // !__STYLE_H__
#define __STYLE_H__C标准库
这一章继续用C语言实现C函数
首先扩充common.c的内容中,封装Clang编译器提供的内置变量和(另外的)一些基本类型
(注意绿线部分)
// common.h
// 一些基本类型
typedef int bool;
typedef unsigned char uint8_t;
typedef unsigned short uint16_t;
typedef unsigned int uint32_t;
typedef unsigned long uint64_t;
typedef uint32_t size_t; // 指针值大小
typedef uint32_t paddr_t; // 物理地址大小
typedef uint32_t vaddr_t; // 虚拟地址大小
// 一些便捷变量
#define true 1
#define false 0
#define NULL ((void *)0)
// Clang提供的魔法原语
#define align_up(value, align) __builtin_align_up(value, align) // 向上对齐到align的倍数
#define is_aligned(value, align) __builtin_is_aligned(value, align) // 检查value是否对齐到align的倍数
#define offsetof(type, member) __builtin_offsetof(type, member) // 获取成员的偏移量
// 函数定义在这里,实现在common.c那边
void* memset(void *dest, int c, size_t n);
void* memcpy(void *dest, const void *src, size_t n);
char* strcpy_s(char *dest, size_t destsz, const char *src);
// 不提供strcpy(官方教程里的是strcpy,我直接一步到位了)
int strcmp(const char *s1, const char *s2);内存操作
首先实现以下内存操作函数:
void* memcpy(void* dest, const void* src, size_t n) {
uint8_t* ptr = (uint8_t*)dest;
const uint8_t* srcptr = (const uint8_t*)src;
for (size_t i = 0; i < n; ++i) {
ptr[i] = srcptr[i]; // 赋值
}
return dest;
}
memcpy函数将n字节从src复制到dst
void* memset(void* dest, char c, size_t n) {
uint8_t* ptr = (uint8_t*)dest; // 强制转换类型
// size_t i 的原因是因为直接写int i,编译器会检查出类型隐式转换并抛出warning
for (size_t i = 0; i < n; ++i) {
ptr[i] = c; // 赋值
}
// 这里没有使用官方教程里的“惯用语”,即将指针递增和解引用写在同一行
// 我觉得这样写更便于我自己理解代码
return dest;
};
/* 官方写法
void *memset(void *buf, char c, size_t n) {
uint8_t *p = (uint8_t *) buf;
while (n--)
*p++ = c;
return buf;
}
memset函数用c填充buf的前n个字节
字符串操作
然后实现字符串操作
strcpy函数将字符串从src复制到dest:(这里我写的是strcpy_s)
char* strcpy_s(char *dest, size_t dest_len, const char *src) {
char *dest_ptr = dest;
while (*src != '\0' && dest_len-- > 0) {
*dest_ptr++ = *src++; // 赋值并移动指针
}
*dest_ptr = '\0'; // 在字符串末尾添加空字符,确保是C风格字符串
return dest;
}复制超出超出目标字符串缓冲区长度时会结束字符串复制
strcmp函数比较s1和s2并返回:
| 条件 | 结果 |
|---|---|
s1 == s2 | 0 |
s1 > s2 | 正值 |
s1 < s2 | 负值 |
// 这里和官方写法差不多,没改多少
int strcmp(const char *s1, const char *s2) {
while(*s1 != '\0' && *s2 != '\0') {
if (*s1 != *s2)
break;
s1++;
s2++;
}
return *(const unsigned char*)s1 - *(const unsigned char*)s2;
}from 官方
在比较时转换为 unsigned char * 是为了符合 POSIX 规范
内核恐慌
相关信息
内核恐慌(kernel panic)发生在内核遇到不可恢复的错误时,类似于 Go 或 Rust 中的 panic 概念。
以下是PANIC宏的实现:(可以使用更现代的static inline)
// kernel.h
#define PANIC(fmt, ...) \
do { \
printf("PANIC: %s:%d: " fmt "\n", __FILE__, __LINE__, ##__VA_ARGS__); \
while (1) {} \
} while (0)它打印出恐慌发生的位置,然后进入一个无限循环来停止处理。我们在这里将其定义为宏。这样做的原因是为了正确显示源文件名(
__FILE__)和行号(__LINE__)。如果我们将其定义为函数,__FILE__和__LINE__将显示PANIC被定义的文件名和行号,而不是它被调用的位置。
这个宏还使用了两个惯用语:
第一个惯用语是
do-while语句。由于它是while (0),这个循环只执行一次。这是定义由多个语句组成的宏的常见方式。简单地用{ ...}封装可能会在与if等语句组合时导致意外的行为(参见这个清晰的例子)。另外,注意每行末尾的反斜杠(\)。虽然宏是在多行上定义的,但在展开时换行符会被忽略。
第二个惯用语是
##__VA_ARGS__。这是一个用于定义接受可变数量参数的宏的有用编译器扩展(参考:GCC 文档)。当可变参数为空时,##会删除前面的,。这使得即使只有一个参数,如PANIC("booted!"),编译也能成功。
试试看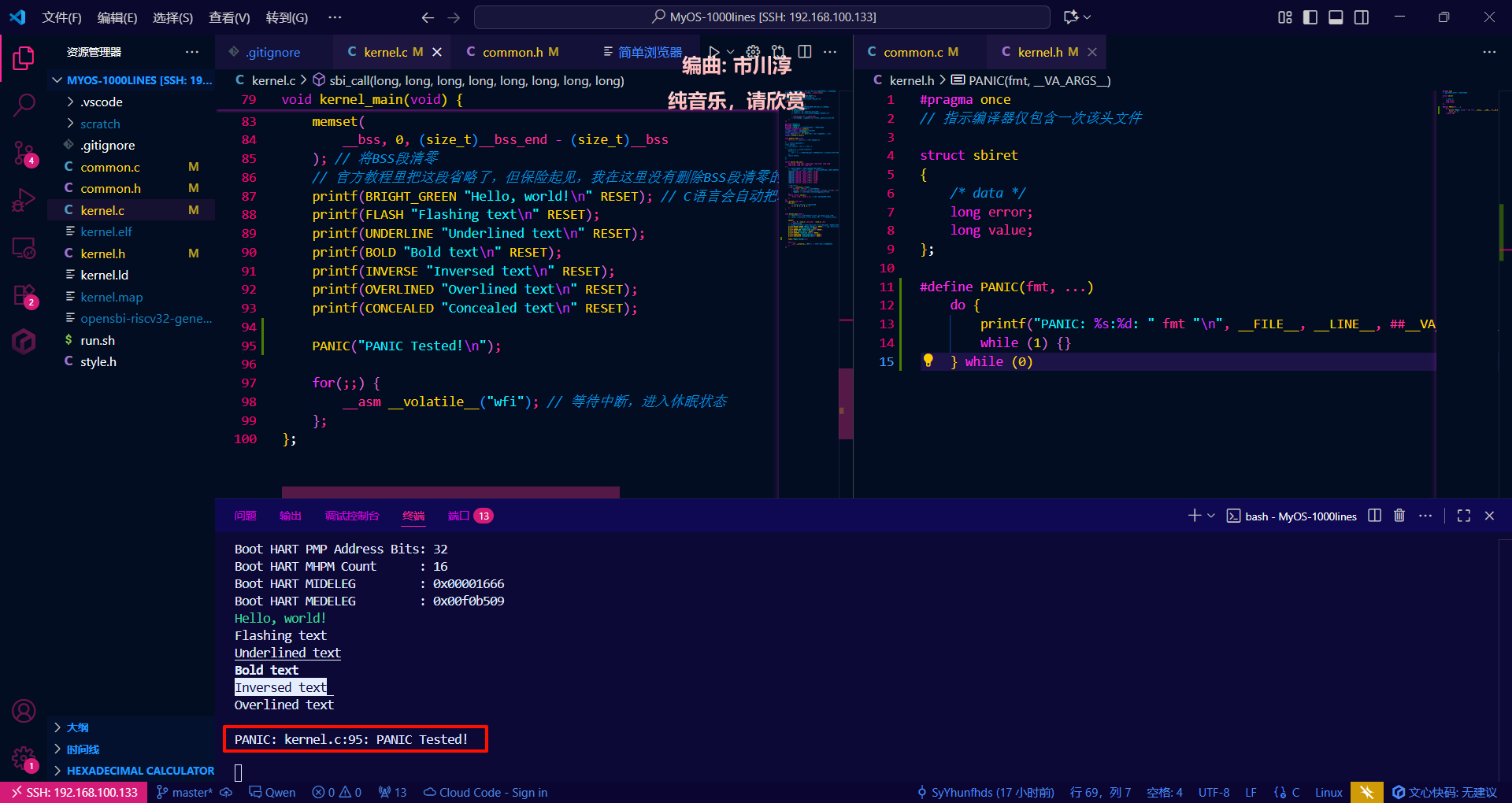
确实正确地打印出了文件名和行号
(PANIC之后程序不会执行后面的行,图上忘记体现出来了)
写一个简单的完善的日志系统
只是打印出__FILE__和__LINE__不能满足我的小心思,我还希望打印内核发生恐慌时的时间,乃至是有色打印
C语言提供了两个可以与“时间”相关的字符串字面量:
__DATE__: 一个字符串字面量,表示源文件被编译的日期,格式为 "Mmm dd yyyy" (例如 "Sep 18 2025")。__TIME__: 一个字符串字面量,表示源文件被编译的时间,格式为 "hh:mm:ss" (例如 "15:30:00")。
但问题是这两个宏都是在编译时就已经确定的(本意是用来追踪版本的),不会随着程序运行时间而改变,用在日志系统中并不合适
幸而,对于教程所使用的RISC-V架构,RISC-V提供了一个标准的、非常易于访问的硬件时钟——RISC-V 时钟寄存器 (time CSR)
相关信息
RISC-V规范定义了一个名为 time 的控制与状态寄存器 (Control and Status Register, CSR)。
- 它是一个64位的计数器。
- 它在系统上电后从0开始,以一个固定的频率持续不断地增加。
- 在S-Mode(内核模式)下,可以通过汇编指令
rdtime直接只读访问它。
下面是封装了rdtime指令的static inline函数,返回一个long整型,或uint_64无符号64位整型:
#include <stdint.h>
static inline uint64_t get_cycles(void) {
uint64_t cycles;
__asm__ __volatile__("rdtime %0" : "=r"(cycles));
return cycles;
}get_cycles返回的是系统自上电以来的时间周期数,要把它变成我们熟悉的秒或毫秒,我们需要知道它的频率。对于QEMU的-machine virt虚拟平台,这个时钟频率是固定的,通常是 10 MHz (即每秒跳动 10,000,000 次)。
(aclint-mtimer @ 10000000Hz,10Mhz)
那么可得:
- 秒:
get_cycles() / 10,000,000 - 毫秒:
get_cycles() / 10,000 - 微秒:
get_cycles() / 10
(考虑到内核启动和运行是毫秒级的,只考虑毫秒应该足够了,不够的后面再细化)
时间搞定后就可以开始编写日志系统了
logging宏
首先公式化地开一个头文件logging.h:
#pragma once
#include "common.h" // 使用uint64_t等类型
#include "style.h" // 引入ANSI序列宏
// 比率
#define TIMESTAMP_US_RATE 10
#define TIMESTAMP_MS_RATE 10000
#define TIMESTAMP_S_RATE 10000000
// 获取当前时间戳,单位为微秒
static inline uint64_t get_cycles(void) {
uint64_t cycles;
// 使用 rdtime 指令将 time CSR 的值读入 cycles 变量
__asm__ __volatile__("rdtime %0" : "=r"(cycles));
return cycles;
}
/* // 位于logging.c中
const char* LOG_LEVEL_INFO = BRIGHT_GREEN "[INFO]" RESET;
const char* LOG_LEVEL_WARN = BRIGHT_RED "[WARNING]" RESET;
const char* LOG_LEVEL_ERROR = BRIGHT_YELLOW "[ERROR]" RESET;
const char* LOG_LEVEL_DEBUG = BRIGHT_BLUE "[DEBUG]" RESET;
*/
extern const char* LOG_LEVEL_INFO;
extern const char* LOG_LEVEL_WARN;
extern const char* LOG_LEVEL_ERROR;
extern const char* LOG_LEVEL_DEBUG;
// 定义一个宏,自动传入 __FILE__ 和 __LINE__
#define log(level, format, ...) \
log_internal(level, __FILE__, __LINE__, format, ##__VA_ARGS__)
// 编译器会在引用宏的地方展开宏,确保__FILE__和__LINE__是真正跟随文件而变的
// 官方教程也提到了为什么不用函数封装的原因,和这里类似
// 声明一下函数,实现在logging.c里
void log_internal(const char* level, const char *file, int line, const char *format, ...);战败CG
找不到了
思考C语言链接器错误之“符号重复”
/* // 位于logging.c中
const char* LOG_LEVEL_INFO = BRIGHT_GREEN "[INFO]" RESET;
const char* LOG_LEVEL_WARN = BRIGHT_RED "[WARNING]" RESET;
const char* LOG_LEVEL_ERROR = BRIGHT_YELLOW "[ERROR]" RESET;
const char* LOG_LEVEL_DEBUG = BRIGHT_BLUE "[DEBUG]" RESET;
*/
extern const char* LOG_LEVEL_INFO;
extern const char* LOG_LEVEL_WARN;
extern const char* LOG_LEVEL_ERROR;
extern const char* LOG_LEVEL_DEBUG;这里不要在.h头文件里写全局变量,否则会在编译时触发duplicate symbol错误
要理解这个错误,首先要明白C语言从源码到可执行文件的两个核心阶段:
- 编译 (Compilation):
- 执行者: 编译器 (如
clang,gcc)。 - 输入: 单个 .c 源文件(例如
kernel.c,logging.c)。 - 工作: 将C代码翻译成包含机器码和元数据的
目标文件 (Object File),通常是.o文件。 - 关键点: 编译器是“管中窥豹”的。在编译
kernel.c时,它完全不知道logging.c的存在。它只相信你在 .h 头文件中给它的“承诺”。每一个.c文件就是一个独立的翻译单元 (Translation Unit)。
- 执行者: 编译器 (如
- 链接 (Linking):
- 执行者: 链接器 (如
ld.lld,ld)。 - 输入: 所有编译好的 .o 目标文件(
kernel.o,common.o,logging.o...)。 - 工作: 像一个项目经理,把所有独立的模块(
.o文件)组装成一个最终的、完整的可执行文件 (kernel.elf)。 - 核心任务: 解析符号 (Resolve Symbols)。它会制作一张巨大的“地址簿”,记录程序中所有全局函数和全局变量的名字(这些就是符号)以及它们最终的内存地址。
那么,什么是符号?
在链接器的世界里,“符号”就是一个名字。全局变量名和全局函数名都是符号。
链接器在它的地址簿里,对每个符号只认两件事:
- 执行者: 链接器 (如
- 符号的定义 (Definition): “这个叫
LOG_LEVEL_INFO的东西,它的‘家’在这里,占了这么多内存。” - 符号的引用 (Reference): “我需要找一个叫
LOG_LEVEL_INFO的东西,谁能告诉我它家在哪?”
链接器工作时,必须遵守一条铁律,被称为一次定义原则 (One Definition Rule, ODR):
在一个最终的可执行程序中,每一个拥有外部链接属性的符号,都必须有且仅有一个定义。
“符号重复”错误,就是链接器在整理地址簿时,发现有两个或更多的模块都声称“LOG_LEVEL_INFO的家在我这里!”,链接器就懵了,因为它不知道哪个才是真正的“家”。
而在头文件中错误声明了全局变量(比如我注释起来的代码)后:
const char* LOG_LEVEL_INFO = BRIGHT_GREEN "[INFO]" RESET;
const char* LOG_LEVEL_WARN = BRIGHT_RED "[WARNING]" RESET;
const char* LOG_LEVEL_ERROR = BRIGHT_YELLOW "[ERROR]" RESET;
const char* LOG_LEVEL_DEBUG = BRIGHT_BLUE "[DEBUG]" RESET;编译器的编译链接流程如下:
- 编译
kernel.c:#include "logging.h"导致LOG_LEVEL_INFO的定义被复制进kernel.c。- 编译器生成
kernel.o,并在其符号表 (Symbol Table) 中记录:“我这里有一个已定义的全局符号LOG_LEVEL_INFO。”
- 编译
logging.c:#include "logging.h"再次导致LOG_LEVEL_INFO的定义被复制进logging.c。- 编译器生成
logging.o,并在其符号表中记录:“我这里也有一个已定义的全局符号LOG_LEVEL_INFO。”
- 链接
kernel.o和logging.o:- 链接器开始构建最终的地址簿。
- 它从
kernel.o拿到了LOG_LEVEL_INFO的定义。 - 然后它又从
logging.o拿到了LOG_LEVEL_INFO的定义。 - 冲突! 链接器发现 ODR 被违反,于是罢工并报告:“
错误:符号 LOG_LEVEL_INFO 重复定义了。”
最佳解决方案是只把.h文件用于声明函数或变量,而在同名.c文件中定义变量和实现函数:
- 在头文件 .h 中使用 extern 进行(变量)声明: 这相当于告诉编译器:“有一个叫
my_var的变量,你先别管它在哪,链接器会找到的。” 这只是一个“引用”,不分配内存。// logging.h extern const char* LOG_LEVEL_INFO; // 只声明函数 // 这里只是演示 int add(int a, int b); - 在对应的 .c 文件中进行定义: 在一个且仅一个
.c文件中(如logging.c),提供这个变量的真正定义。// logging.c #include "logging.h" const char* LOG_LEVEL_INFO = BRIGHT_GREEN "[INFO]" RESET; // 实现对应函数 int add(int a, int b) { return a+b; }
如果在.h里写上了完整的函数实现,在编译时也会因为包含了同一头文件的多份链接文件产生了相同的符号而报错
有时候也可以用static关键字修饰.h文件中的全局变量来快速解决问题
// logging.h
static const char* LOG_LEVEL_INFO = "...";static 关键字用在全局作用域时,会改变符号的链接属性 (Linkage),从外部链接 (External Linkage) 变为内部链接 (Internal Linkage)。这意味着,这个符号只在它所在的翻译单元(.o 文件)内部可见,链接器在合并时不会把它当作全局符号。这样做可以解决链接错误,但它引入了一个更隐蔽的问题:每一个包含了 logging.h 的 .c 文件,都会拥有一个它自己私有的、独立的 LOG_LEVEL_INFO 变量的拷贝。
- 这会浪费内存。
- 如果试图修改这个变量,在一个文件中修改了,另一个文件却不会变,导致状态不一致
因此,static不是解决“共享全局变量”问题的正确工具。它适用于创建文件作用域内的私有变量/函数。
实现logging.c标准日志功能
#include "common.h" // 使用uint64_t等类型和printf等函数
#include "logging.h" // 引入一些内联函数
#include "style.h" // 引入ANSI序列封装
// 写在这边,编译器才能正确分配内存
// 写在头文件里的话会因为多次包含而出现重复定义
const char* LOG_LEVEL_INFO = BRIGHT_GREEN "[INFO]" RESET;
const char* LOG_LEVEL_WARN = BRIGHT_RED "[WARNING]" RESET;
const char* LOG_LEVEL_ERROR = BRIGHT_YELLOW "[ERROR]" RESET;
const char* LOG_LEVEL_DEBUG = BRIGHT_BLUE "[DEBUG]" RESET;
void log_internal(const char* level, const char *file, int line, const char *format, ...) {
// 这个函数中会用到专门处理可变参数列表的vprintf
// 写起来很简单,只需要把printf里处理va_list的部分抽出去就可以了
uint64_t timestamp_ms = get_cycles() / TIMESTAMP_MS_RATE;
// 打印时间戳和日志级别
// 因为还不支持字段宽度定长输出和unsigned int格式化,所以这里只能先用%d代替,而不是%u
printf("[%d ms] %s ", (int)timestamp_ms, level); // level自带中括号包裹,这里不另加
// 打印文件名和行号
printf("|%s:%d| ", file, line);
va_list args;
va_start(args, format);
vprintf(format, args); // 打印格式化字符串和参数
va_end(args);
printf("\n");
}试试这个宏怎么样
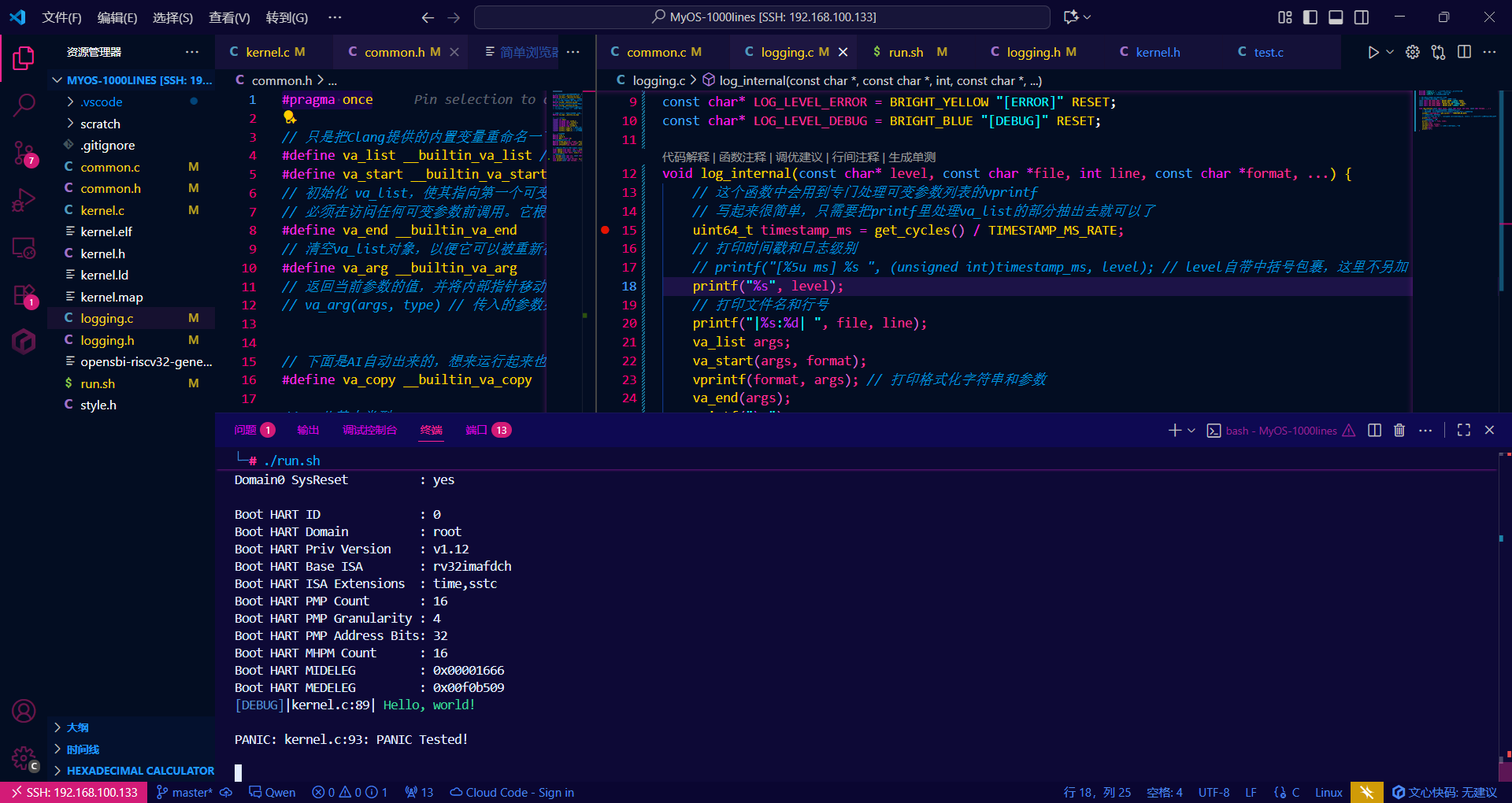
运行符合预期,但程序还不能处理时间戳,因为时间戳格式化涉及对unsigned int的格式化,而官方教程没有涉及这一点,我不能依赖官方教程实现
暂时先换成%d应付应付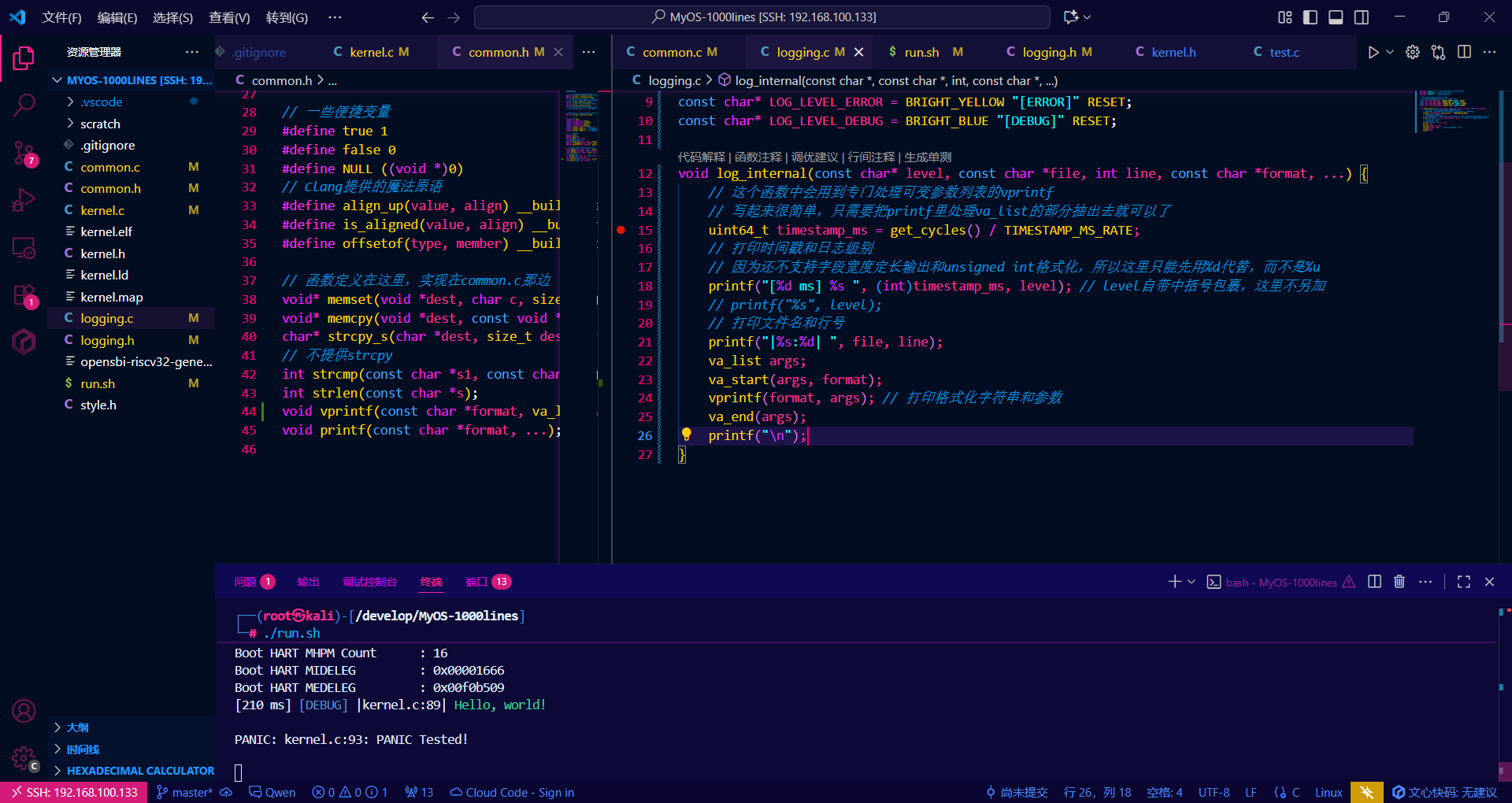
日志简单封装
完善的日志系统需要实现自定义日志级别,DEBUG、INFO、WARNING都有各自的日志级别,选了INFO,DEBUG就不会打印出来
现在的纯字符字面量不适于简单实现日志级别判断,需要替换为整型,再增加一个函数用于替换生成字符串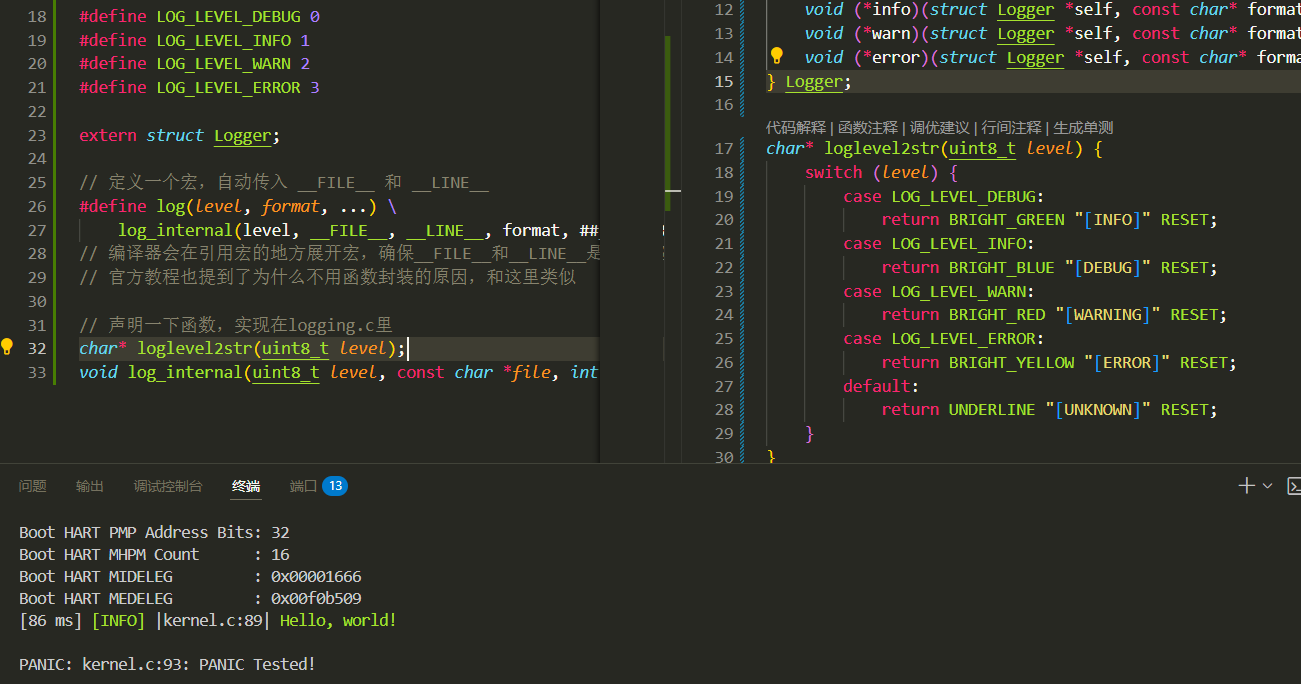
枚举类型是编译时常量,这对我来说有点超纲了……所以就拿switch写了
尝试使用结构体+函数指针模拟OOP,但是C语言不能自动传递实例,即使使用宏也仍然会很繁琐,因此还是改为使用宏+函数封装了
// logging.h
#pragma once
#include "common.h" // 使用uint64_t等类型
#include "style.h" // 引入ANSI序列宏
#define TIMESTAMP_US_RATE 10
#define TIMESTAMP_MS_RATE 10000
#define TIMESTAMP_S_RATE 10000000
// 获取当前时间戳,单位为微秒
static inline uint64_t get_cycles(void) {
uint64_t cycles;
// 使用 rdtime 指令将 time CSR 的值读入 cycles 变量
__asm__ __volatile__("rdtime %0" : "=r"(cycles));
return cycles;
}
#define LOG_LEVEL_DEBUG 0
#define LOG_LEVEL_INFO 1
#define LOG_LEVEL_WARN 2
#define LOG_LEVEL_ERROR 3
// 定义一个宏,自动传入 __FILE__ 和 __LINE__
#define log(level, format, ...) \
log_internal(level, __FILE__, __LINE__, format, ##__VA_ARGS__)
// 声明一下函数,实现在logging.c里
char* loglevel2str(int level);
void vlog_internal(
int level,
const char *file,
int line,
const char *format,
va_list args
);
void log_internal(int level, const char *file, int line, const char *format, ...);
#define log_info(format, ...) \
log_internal(LOG_LEVEL_INFO, __FILE__, __LINE__, format, ##__VA_ARGS__)
#define log_debug(format, ...) \
log_internal(LOG_LEVEL_DEBUG, __FILE__, __LINE__, format, ##__VA_ARGS__)
#define log_warn(format, ...) \
log_internal(LOG_LEVEL_WARN, __FILE__, __LINE__, format, ##__VA_ARGS__)
#define log_error(format, ...) \
log_internal(LOG_LEVEL_ERROR, __FILE__, __LINE__, format, ##__VA_ARGS__)//logging.c
#include "common.h" // 使用uint64_t等类型和printf等函数
#include "logging.h" // 引入一些内联函数
#include "style.h" // 引入ANSI序列封装
char* loglevel2str(int level) {
switch (level) {
case LOG_LEVEL_DEBUG:
return BRIGHT_GREEN "[INFO]" RESET;
case LOG_LEVEL_INFO:
return BRIGHT_BLUE "[DEBUG]" RESET;
case LOG_LEVEL_WARN:
return BRIGHT_RED "[WARNING]" RESET;
case LOG_LEVEL_ERROR:
return BRIGHT_YELLOW "[ERROR]" RESET;
default:
return UNDERLINE "[UNKNOWN]" RESET;
}
}
void vlog_internal(
int level,
const char *file,
int line,
const char *format,
va_list args
) {
uint64_t timestamp_ms = get_cycles() / TIMESTAMP_MS_RATE;
printf("[%d ms] %s ", (int)timestamp_ms, loglevel2str(level));
// 打印文件名和行号
printf("|%s:%d| ", file, line);
vprintf(format, args); // 打印格式化字符串和参数
printf("\n");
}
void log_internal(int level, const char *file, int line, const char *format, ...) {
va_list args;
va_start(args, format);
vlog_internal(level, file, line, format, args);
va_end(args);
}异常
异常是什么
异常(Exception) 是一个 CPU 功能,允许内核处理各种事件,如无效内存访问(也就是页面错误)、非法指令和系统调用。
Exception 类似于 C++ 或 Java 中的硬件辅助
try-catch机制。在 CPU 遇到需要内核干预的情况之前,它会继续执行程序。与try-catch的主要区别在于,内核可以从发生异常的地方恢复执行,就像什么都没发生过一样。这听起来是不是很酷的 CPU 功能?
Exception 也可以在内核模式下触发,它们大多是致命的内核错误。如果 QEMU 意外重置或内核无法按预期工作,很可能是发生了异常。
异常的生命周期
在 RISC-V 中,异常将按以下方式处理:
- CPU 检查
medeleg寄存器以确定哪个操作模式应该处理异常。在我们的情况下,OpenSBI 已经配置为在 S-Mode 的处理程序中处理 U-Mode/S-mode 异常。 - CPU 将其状态(寄存器)保存到各种 CSR 中(见下文)。
stvec寄存器的值被设置为程序计数器,跳转到内核的异常处理程序。- 异常处理程序保存通用寄存器(即程序状态),并处理异常。
- 完成后,异常处理程序恢复保存的执行状态并调用
sret指令,从发生异常的地方恢复执行。
步骤 2 中更新的 CSR 主要如下。内核的异常根据 CSR 确定必要的操作:
| 寄存器名称 | 内容 |
|---|---|
scause | 异常类型。内核读取此项以识别异常类型。 |
stval | 关于异常的附加信息(例如,导致异常的内存地址)。取决于异常类型。 |
sepc | 发生异常时的程序计数器。 |
sstatus | 发生异常时的操作模式(U-Mode/S-Mode)。 |
异常的处理程序
__attribute__((naked)) // 不要生成完整的函数体
__attribute__((aligned(4))) // 对齐到4字节边界
void kernel_entry(void) { // 在stvec寄存器中注册的异常程序入口点
__asm__ __volatile__(
"csrw sscratch, sp\n"
"addi sp, sp, -4 * 31\n" // 栈大小设置为4*31共124字节,预留4字节给ecall指令使用
"sw ra, 4 * 0(sp)\n" // sw指令的用途是将寄存器的内容存储到内存中
"sw gp, 4 * 1(sp)\n" // 因此这里是将所有寄存器的值都保存到栈中
"sw tp, 4 * 2(sp)\n"
"sw t0, 4 * 3(sp)\n"
"sw t1, 4 * 4(sp)\n"
"sw t2, 4 * 5(sp)\n"
"sw t3, 4 * 6(sp)\n"
"sw t4, 4 * 7(sp)\n"
"sw t5, 4 * 8(sp)\n"
"sw t6, 4 * 9(sp)\n"
"sw a0, 4 * 10(sp)\n"
"sw a1, 4 * 11(sp)\n"
"sw a2, 4 * 12(sp)\n"
"sw a3, 4 * 13(sp)\n"
"sw a4, 4 * 14(sp)\n"
"sw a5, 4 * 15(sp)\n"
"sw a6, 4 * 16(sp)\n"
"sw a7, 4 * 17(sp)\n"
"sw s0, 4 * 18(sp)\n"
"sw s1, 4 * 19(sp)\n"
"sw s2, 4 * 20(sp)\n"
"sw s3, 4 * 21(sp)\n"
"sw s4, 4 * 22(sp)\n"
"sw s5, 4 * 23(sp)\n"
"sw s6, 4 * 24(sp)\n"
"sw s7, 4 * 25(sp)\n"
"sw s8, 4 * 26(sp)\n"
"sw s9, 4 * 27(sp)\n"
"sw s10, 4 * 28(sp)\n"
"sw s11, 4 * 29(sp)\n"
"csrr a0, sscratch\n"
// 读取sscratch寄存器的值到a0寄存器中 // sscratch寄存器本身用于保存异常发生时的sp寄存器的值
"sw a0, 4 * 30(sp)\n"
"mv a0, sp\n"
"call handle_trap\n"
"lw ra, 4 * 0(sp)\n"
// load word指令
// 在调用handle_trap函数后,需要将寄存器的值恢复到原来的状态
"lw gp, 4 * 1(sp)\n"
"lw tp, 4 * 2(sp)\n"
"lw t0, 4 * 3(sp)\n"
"lw t1, 4 * 4(sp)\n"
"lw t2, 4 * 5(sp)\n"
"lw t3, 4 * 6(sp)\n"
"lw t4, 4 * 7(sp)\n"
"lw t5, 4 * 8(sp)\n"
"lw t6, 4 * 9(sp)\n"
"lw a0, 4 * 10(sp)\n"
"lw a1, 4 * 11(sp)\n"
"lw a2, 4 * 12(sp)\n"
"lw a3, 4 * 13(sp)\n"
"lw a4, 4 * 14(sp)\n"
"lw a5, 4 * 15(sp)\n"
"lw a6, 4 * 16(sp)\n"
"lw a7, 4 * 17(sp)\n"
"lw s0, 4 * 18(sp)\n"
"lw s1, 4 * 19(sp)\n"
"lw s2, 4 * 20(sp)\n"
"lw s3, 4 * 21(sp)\n"
"lw s4, 4 * 22(sp)\n"
"lw s5, 4 * 23(sp)\n"
"lw s6, 4 * 24(sp)\n"
"lw s7, 4 * 25(sp)\n"
"lw s8, 4 * 26(sp)\n"
"lw s9, 4 * 27(sp)\n"
"lw s10, 4 * 28(sp)\n"
"lw s11, 4 * 29(sp)\n"
"lw sp, 4 * 30(sp)\n"
"sret\n"
);
};这里摘抄和补充一些关键点:
相关信息
sscratch寄存器用作临时存储,用于保存异常发生时的堆栈指针,后续会恢复。- 浮点寄存器(
f0-f31)在内核中不使用,因此这里不需要保存它们。通常,它们在线程切换期间保存和恢复。 - 堆栈指针被设置在
a0寄存器中,并调用handle_trap函数。此时,堆栈指针指向的地址包含按照后面描述的trap_frame结构存储的寄存器值。 - 添加
__attribute__((aligned(4)))将函数的起始地址对齐到 4 字节边界。这是因为stvec寄存器不仅保存异常处理程序的地址,而且在其低 2 位中有表示模式的标志。
注意
异常处理程序的入口点是内核中最关键和最容易出错的部分之一。而官方在源代码中,将所有通用寄存器的值都保存到了堆栈中,甚至使用了 sscratch 保存 sp
尝试捕获一下中断:
// kernel.c
void handle_trap(struct trap_frame *f) {
uint32_t scause = READ_CSR(scause);
uint32_t stval = READ_CSR(stval);
uint32_t user_pc = READ_CSR(sepc);
PANIC("unexpected trap scause=%x, stval=%x, sepc=%x\n", scause, stval, user_pc);
}以及用到的结构体声明和宏:
// kernel.h
#include "common.h"
struct trap_frame {
uint32_t ra;
uint32_t gp;
uint32_t tp;
uint32_t t0;
uint32_t t1;
uint32_t t2;
uint32_t t3;
uint32_t t4;
uint32_t t5;
uint32_t t6;
uint32_t a0;
uint32_t a1;
uint32_t a2;
uint32_t a3;
uint32_t a4;
uint32_t a5;
uint32_t a6;
uint32_t a7;
uint32_t s0;
uint32_t s1;
uint32_t s2;
uint32_t s3;
uint32_t s4;
uint32_t s5;
uint32_t s6;
uint32_t s7;
uint32_t s8;
uint32_t s9;
uint32_t s10;
uint32_t s11;
uint32_t sp;
} __attribute__((packed));
#define READ_CSR(reg) \
({ \
unsigned long __tmp; \
__asm__ __volatile__("csrr %0, " #reg : "=r"(__tmp)); \
__tmp; \
})
#define WRITE_CSR(reg, value) \
do { \
uint32_t __tmp = (value); \
__asm__ __volatile__("csrw " #reg ", %0" ::"r"(__tmp)); \
} while (0)
trap_frame结构体表示在kernel_entry中保存的程序状态。READ_CSR和WRITE_CSR宏是用于读写 CSR 寄存器的便捷宏。
最后需要告诉 CPU 异常处理程序的位置。这是通过在kernel_main函数中设置stvec寄存器来完成的:
// kernel.c
void kernel_main(void) {
memset(__bss, 0, (size_t) __bss_end - (size_t) __bss);
WRITE_CSR(stvec, (uint32_t) kernel_entry); // 新增
__asm__ __volatile__("unimp"); // 新增除了设置
stvec寄存器外,它还执行unimp指令。这是一个会触发非法指令异常的伪指令。
(stvec寄存器为异常处理程序入口,这里设置为上面自定义的kernel_entry函数的入口地址)
相关信息
unimp 是一个"伪"指令。
根据 RISC-V Assembly Programmer's Manual,汇编器将 unimp 转换为以下指令:
csrrw x0, cycle, x0这会将 cycle 寄存器读取并写入 x0。由于 cycle 是只读寄存器,CPU 判断该指令无效并触发非法指令异常。
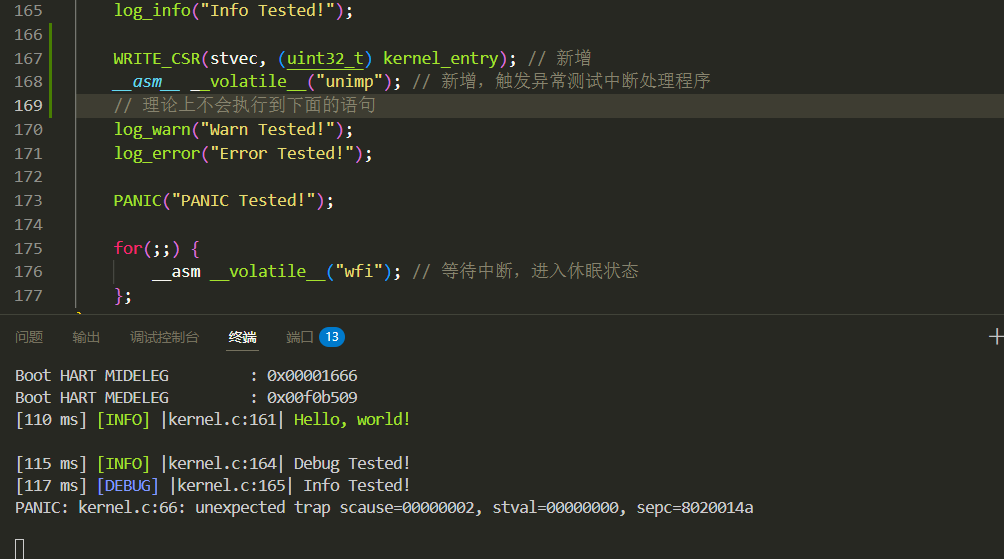
执行起来测试一下,可以看到unimp指令后面的logging测试语句无法被执行
PANIC: kernel.c:66: unexpected trap scause=00000002, stval=00000000, sepc=8020014a当
scause的值为 2 时,表示“非法指令”,意味着程序试图执行无效指令。这正是unimp指令的预期行为!
顺便检查一下sepc的值指向哪里。如果它指向调用unimp指令的行,那么一切都如预期:
apt install llvm-addr2line && llvm-addr2line -e kernel.elf 8020014a
/develop/MyOS-1000lines/kernel.c:168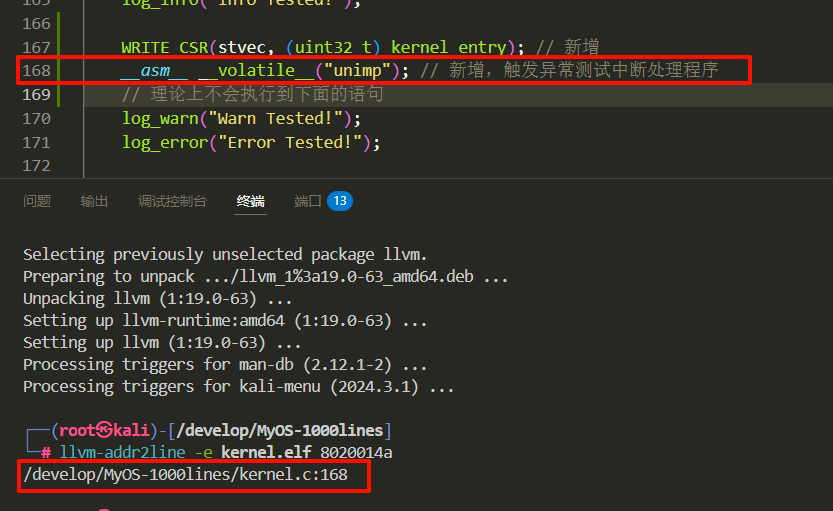
内存分配
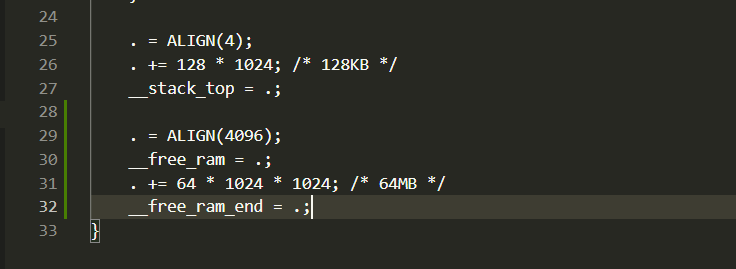
. = ALIGN(4096);
__free_ram = .;
. += 64 * 1024 * 1024; /* 64MB */
__free_ram_end = .;在实现内存分配器之前,我们需要定义要由分配器管理的内存区域(如上)
这添加了两个新符号:
__free_ram和__free_ram_end。它定义了栈空间之后的内存区域。空间大小(64MB)是一个任意值,而. = ALIGN(4096)确保它与 4KB 边界对齐。
通过在链接器脚本中定义而不是硬编码地址,链接器可以确定位置以避免与内核的静态数据重叠。
一个简单的内存分配算法
// kernel.c
extern char __free_ram[], __free_ram_end[];
paddr_t alloc_pages(uint32_t num_pages) {
static paddr_t next_free_page = (paddr_t)__free_ram; // 这里会提示“整数转换导致截断”
paddr_t paddr = next_free_page;
next_free_page += num_pages * PAGE_SIZE;
if (next_free_page > (paddr_t)__free_ram_end) {
PANIC("out of memory");
}
memset((void *)paddr, 0, num_pages * PAGE_SIZE);
return paddr;
}上面实现了一个最简单的内存分配算法,使用线性内存分配逻辑,并且无法回收内存。
这种分配器通常被称为" bump allocator 凹凸分配器 "或" stack allocator 栈分配器",适合操作系统启动初期的简单内存管理需求,但不适合需要频繁分配释放的通用场景。
PAGE_SIZE定义在common.h中
// 内存分页管理
#define PAGE_SIZE 4096转载自官方课程
其中,你会发现:
next_paddr被定义为static变量。这意味着,与局部变量不同,它的值在函数调用之间保持不变。也就是说,它的行为像全局变量。next_paddr指向“下一个要分配区域”(空闲区域)的起始地址。在分配时,next_paddr前进分配大小的距离。next_paddr最初保存__free_ram的地址。这意味着内存从__free_ram开始顺序分配。- 由于链接器脚本中的
ALIGN(4096),__free_ram被放置在 4KB 边界上。因此,alloc_pages函数总是返回与 4KB 对齐的地址。 - 如果它试图分配超出
__free_ram_end的内存,换句话说,如果内存耗尽,就会发生内核恐慌。 memset函数确保分配的内存区域总是用零填充。这是为了避免未初始化内存导致的难以调试的问题。
试试内存分配
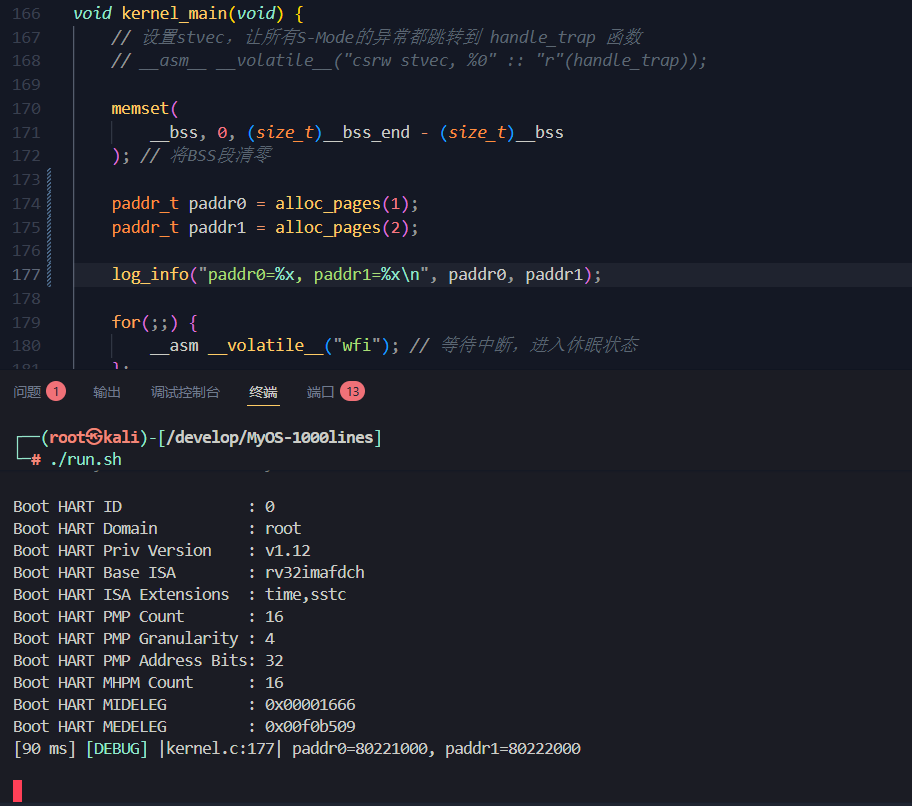
[90 ms] [DEBUG] |kernel.c:177| paddr0=80221000, paddr1=80222000相差0x1000,或4KB字节,正好是一页内存的大小
进程
进程是应用程序的一个实例。每个进程都有其独立的执行上下文和资源,如虚拟地址空间。
注
实际的操作系统将执行上下文作为一个称为线程的独立概念提供。这里为简单起见,将每个进程都视为只有一个线程
进程控制块
如下定义一个Process Control Block
// kernel.c
#define PROCS_MAX 8 // 最大进程数
#define PROC_UNUSED 0 // 未使用的进程控制结构
#define PROC_RUNNABLE 1 // 可运行的进程
struct process {
int pid; // 进程ID
int state; // 进程状态 0未使用 1可运行
vaddr_t sp; // 栈顶指针
uint8_t stack[8192]; //内核栈=8192
};内核栈包含保存的 CPU 寄存器、返回地址(从何处调用)和局部变量。通过为每个进程准备一个内核栈,我们可以通过保存和恢复 CPU 寄存器并切换栈指针来实现上下文切换。
上下文切换
__attribute__((naked)) void switch_context(uint32_t *prev_sp,
uint32_t *next_sp) {
__asm__ __volatile__(
// 将被调用者保存寄存器保存到当前进程的栈上
"addi sp, sp, -13 * 4\n" // 为13个4字节寄存器分配栈空间
"sw ra, 0 * 4(sp)\n" // 仅保存被调用者保存的寄存器
"sw s0, 1 * 4(sp)\n"
"sw s1, 2 * 4(sp)\n"
"sw s2, 3 * 4(sp)\n"
"sw s3, 4 * 4(sp)\n"
"sw s4, 5 * 4(sp)\n"
"sw s5, 6 * 4(sp)\n"
"sw s6, 7 * 4(sp)\n"
"sw s7, 8 * 4(sp)\n"
"sw s8, 9 * 4(sp)\n"
"sw s9, 10 * 4(sp)\n"
"sw s10, 11 * 4(sp)\n"
"sw s11, 12 * 4(sp)\n"
// 切换栈指针
"sw sp, (a0)\n" // *prev_sp = sp;
"lw sp, (a1)\n" // 在这里切换栈指针(sp)
// 从下一个进程的栈中恢复被调用者保存的寄存器
"lw ra, 0 * 4(sp)\n" // 仅恢复被调用者保存的寄存器
"lw s0, 1 * 4(sp)\n"
"lw s1, 2 * 4(sp)\n"
"lw s2, 3 * 4(sp)\n"
"lw s3, 4 * 4(sp)\n"
"lw s4, 5 * 4(sp)\n"
"lw s5, 6 * 4(sp)\n"
"lw s6, 7 * 4(sp)\n"
"lw s7, 8 * 4(sp)\n"
"lw s8, 9 * 4(sp)\n"
"lw s9, 10 * 4(sp)\n"
"lw s10, 11 * 4(sp)\n"
"lw s11, 12 * 4(sp)\n"
"addi sp, sp, 13 * 4\n" // 我们已从栈中弹出13个4字节寄存器
"ret\n"
);
}
switch_context将被调用者保存的寄存器保存到栈上,切换栈指针,然后从栈中恢复被调用者保存的寄存器。换句话说,执行上下文作为临时局部变量存储在栈上。
被调用者保存的寄存器是被调用函数在返回前必须恢复的寄存器。在 RISC-V 中,s0到s11是被调用者保存的寄存器。其他像a0这样的寄存器是调用者保存的寄存器,已经由调用者保存在栈上。这就是为什么switch_context只处理部分寄存器。
有了进程上下文切换之后,我们还需要一个创建进程的函数,它以入口点为参数,并返回指向创建的process结构的指针:
struct process procs[PROCS_MAX]; // 进程控制结构
struct process *create_process(uint32_t pc) {
// 查找未使用的进程控制结构
struct process *proc = NULL;
int i;
for (i = 0; i < PROCS_MAX; i++) {
if (procs[i].state == PROC_UNUSED) {
proc = &procs[i]; // 线性遍历未使用的进程块
break;
}
}
if (proc == NULL) {
PANIC("no more process slot\n");
}
uint32_t *sp = (uint32_t*) &proc->stack[sizeof(proc->stack)];
*--sp = 0; // s11
*--sp = 0; // s10
*--sp = 0; // s9
*--sp = 0; // s8
*--sp = 0; // s7
*--sp = 0; // s6
*--sp = 0; // s5
*--sp = 0; // s4
*--sp = 0; // s3
*--sp = 0; // s2
*--sp = 0; // s1
*--sp = 0; // s0
*--sp = (uint32_t) pc; // ra
// ra寄存器保存用户程序返回地址 // 这里保存的是用户程序入口地址
// 初始化字段
proc->pid = i + 1;
proc->state = PROC_RUNNABLE;
proc->sp = (vaddr_t) sp;
return proc;
}测试上下文切换
创建两个进程用于测试
// kernel.c
void delay(void) {
for (int i = 0; i < 1000000; i++)
__asm__ __volatile__("nop"); // 让CPU空转一个周期
}
struct process *proc_a;
struct process *proc_b;
void proc_a_entry(void) {
log_info("proc_a_entry: pid=%d is running\n", proc_a->pid);
while (1) {
putchar('A');
switch_context(&proc_a->sp, &proc_b->sp); // 切换到进程块B
delay();
}
}
void proc_b_entry(void) {
log_info("proc_b_entry: pid=%d is running\n", proc_b->pid);
while (1) {
putchar('B');
switch_context(&proc_b->sp, &proc_a->sp); // 切换到进程块A
delay();
}
}
proc_a_entry函数和proc_b_entry函数分别是进程 A 和进程 B 的入口点。使用putchar函数显示单个字符后,它们使用switch_context函数切换到另一个进程。delay函数实现了一个忙等待,以防止字符输出过快导致终端无响应。nop指令是一个“什么都不做”的指令。添加它是为了防止编译器优化删除循环。
调度器
在前面的实验中,我们直接调用
switch_context函数来指定“下一个要执行的进程”。然而,随着进程数量的增加,这种方法在确定下一个要切换的进程时会变得复杂。为了解决这个问题,让我们实现一个*“调度器”*,一个决定下一个进程的内核程序。
struct process *current_proc; // 当前进程控制结构
struct process *idle_proc; // 空闲进程
void yield(void) {
// 搜索可运行的进程
struct process *next_proc = idle_proc;
for (int i = 0; i < PROCS_MAX; i++) {
struct process *proc = &procs[(current_proc->pid + 1) % PROCS_MAX];
if (proc->state == PROC_RUNNABLE && proc->pid > 0) {
next_proc = proc;
break;
}
}
// 如果除了当前进程外没有可运行的进程,就返回void并继续处理
if (next_proc == current_proc) {
return;
}
// 上下文切换
struct process *prev_proc = current_proc;
current_proc = next_proc;
switch_context(&prev_proc->sp, &next_proc->sp);
}这里引入了两个全局变量。
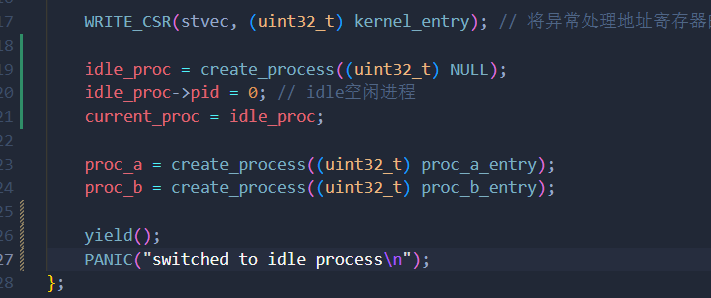
current_proc指向当前运行的进程。idle_proc指向空闲进程,即“当没有可运行进程时要运行的进程”。idle_proc在启动时创建为进程 ID 为0的进程
这个初始化过程的关键点是current_proc = idle_proc。这确保了引导进程的执行上下文被保存并作为空闲进程的上下文恢复。在第一次调用yield函数期间,它从空闲进程切换到进程 A,当切换回空闲进程时,它的行为就像从这个yield函数调用返回一样。
最后,修改
proc_a_entry和proc_b_entry如下,调用yield函数而不是直接调用switch_context函数
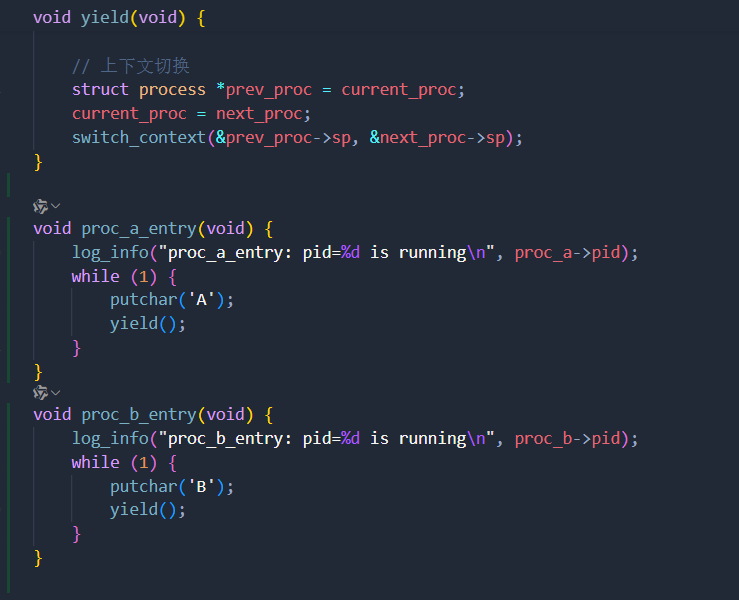
异常处理程序的变更
在异常处理程序中,它将执行状态保存到栈上。然而,由于我们现在为每个进程使用独立的内核栈,我们需要稍微更新它。
首先,在进程切换期间在
sscratch寄存器中设置当前执行进程的内核栈的初始值。
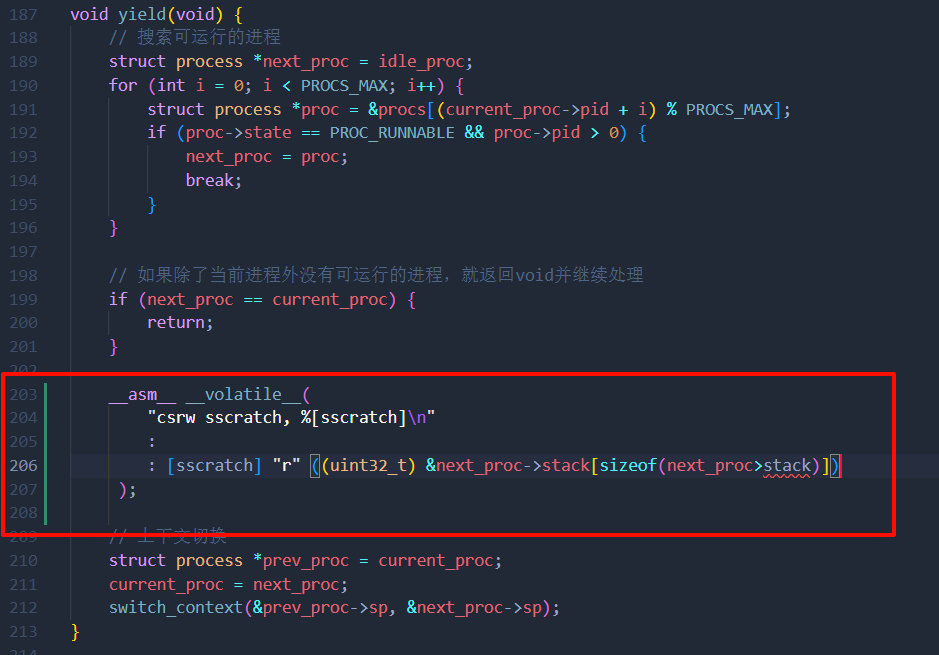
这里语法报错是因为IDE识别不出来上下文,不关我的事
由于栈指针向低地址延伸,我们将地址设置在
sizeof(next->stack)字节处作为内核栈的初始值。
对异常处理程序的修改如下:
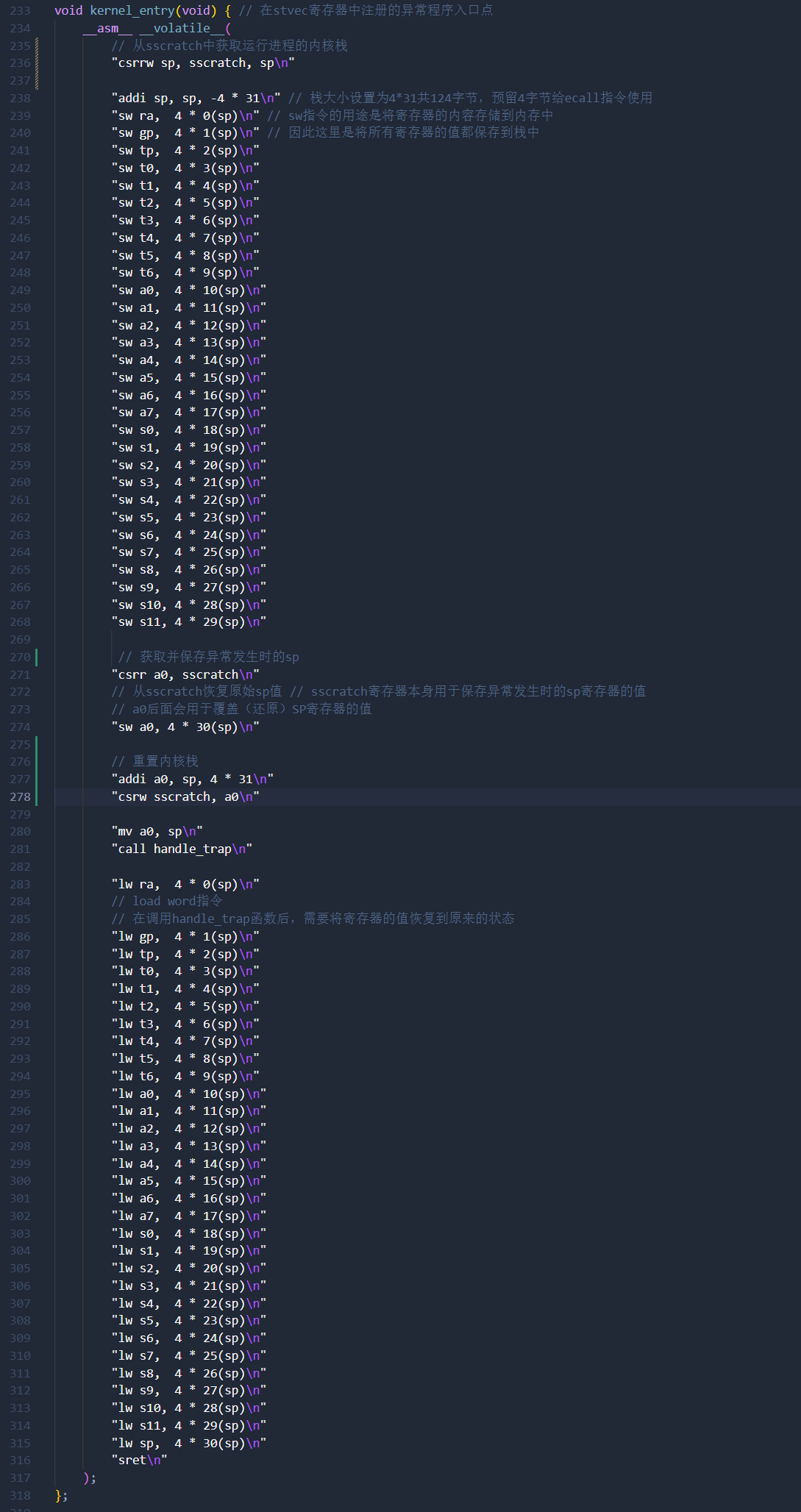
现在
sp指向当前运行进程的内核(不是用户) 栈。此外,sscratch现在保存异常发生时原始的sp值(用户栈)。
在将其他寄存器保存到内核栈之后,我们从sscratch恢复原始的sp值并保存到内核栈上。然后,计算sscratch的初始值并恢复它。
这里的关键点是每个进程都有自己独立的内核栈。通过在上下文切换期间切换sscratch的内容,我们可以从进程被中断的点恢复执行,就像什么都没发生一样。