Subdomain GUI 项目规划
项目依赖
- Flask + Jinja2 Web服务器
- Plotly 创建交互式图表
- SQLite和SQLAlchemu 持久化数据
- Pandas 从数据库中读取数据并进行格式化
- loguru 更快的日志库
- Pyyaml 加载YAML配置
- Pendulum 更友好的时间处理库
- gettext 国际化支持
项目规划
希望达成的目标
- 为Github上常用的子域名爆破项目提供Web集成的、数据可视化的UI
- 整合子域名爆破方案,提供封装好的扫描模式
- 定时进行子域名挖掘,如果出现了新的子域名需要高亮显示,必要时可以向指定邮箱发送邮件
- 提供从文件中获取目标 和 从前端获取目标列表 等模式,拓展子域名挖掘工具的功能
- 整合Google Dorking技巧以精准寻找目标
- 整合httpx用于批量探活
- 整合
UsedJS和403Bypasser用于前端漏洞挖掘 - 整合
Nuclei用于基础漏洞挖掘 - 国际化支持
项目架构规划(AI生成)
项目总览:自动化渗透测试与资产监控平台
- 核心原则: 数据驱动、异步任务、模块化、可扩展、高可靠性。
- 技术架构: 三位一体模型:调度器 (APScheduler) + 工作者 (Celery/Multiprocessing) + 前端 (Streamlit),通过数据库 (SQLite/SQLAlchemy) 进行解耦通信。
功能与特点清单
1. 核心功能:自动化扫描流水线
- 功能描述: 根据用户配置,自动或手动地执行一条由多个阶段组成的扫描流水线(子域名发现 -> 资产探活 -> 漏洞扫描)。
- 技术考量:
- API契约: 整个流水线由多个处理步骤组成,每个步骤的函数/方法都遵循
function(context, input_df, **options) -> output_df的范式,接收并返回标准数据格式的DataFrame。 - 链式调用: 流水线的执行通过Pandas DataFrame的传递来完成,前一阶段的输出是后一阶段的输入。
- 实现细节:
- 不直接使用
Protocol,因为流水线步骤的逻辑差异较大。 - 必须使用
Context类,将数据库会话和日志记录器统一传递给每个处理步骤。 - 可以考虑为流水线的启动和结束(如记录总耗时)编写一个装饰器。
- 不直接使用
- API契约: 整个流水线由多个处理步骤组成,每个步骤的函数/方法都遵循
2. 功能模块:多工具集成与封装
- 功能描述: 集成并封装多个外部CLI工具(如Subfinder, ksubdomain, httpx, Nuclei),提供统一的Python接口。
- 技术考量:
- 统一接口: 每个工具的封装类(Wrapper)都必须提供一个统一的方法,例如
scan()。 - 标准化输出: 每个
scan()方法的返回值必须是标准数据格式的DataFrame。 - 实现细节:
- 强烈推荐使用
Protocol(ScannerProtocol) 来定义所有封装类的行为契约。这能确保每个封装类都有scan()方法和name属性,保证了系统的可替换性和一致性。 - Wrapper内部的复杂实现(如构建命令行)应封装在私有方法 (
_private_method) 中。 - 不需要直接在
scan()方法中传递Context,因为底层的进程调用通常不直接与数据库交互。
- 强烈推荐使用
- 统一接口: 每个工具的封装类(Wrapper)都必须提供一个统一的方法,例如
3. 核心架构:异步任务调度与执行
- 功能描述: 系统包含独立的调度器和工作者进程。调度器根据时间创建任务,工作者获取并执行任务。前端UI与任务执行完全解耦。
- 技术考量:
- 数据库即队列:
tasks表是实现解耦的核心。调度器是生产者,工作者是消费者。 - 状态管理: 任务的生命周期(
pending,running,completed,failed)和进度都在数据库中进行管理。 - 实现细节:
- 这是架构层面的设计,不直接涉及
Protocol或Context。 - Worker的任务执行循环 是应用层边界,必须实现顶层异常捕获和日志归档。
- 这是架构层面的设计,不直接涉及
- 数据库即队列:
4. 前端交互:Web UI与全局监控
- 功能描述: 提供一个Streamlit Web界面,用于手动触发任务、实时监控所有任务的进度和状态、以及可视化展示扫描结果。
- 技术考量:
- 只读为主: 前端的主要职责是从数据库读取状态和结果并展示。
- 写操作轻量: 前端的写操作仅限于向
tasks表中插入一条新任务,不直接执行任何耗时操作。 - 实现细节:
- 不直接使用
Protocol。 - 必须使用
Context来管理数据库会话,以便于从数据库读取数据或写入新任务。可以使用**@with_db_session装饰器**来简化页面函数中的会话管理。
- 不直接使用
5. 数据管理:统一数据模型与持久化
- 功能描述: 所有工具的扫描结果都将被格式化为统一的数据模型,并存储在SQLite数据库中。提供周期性的数据比对功能(如发现新资产)。
- 技术考量:
- 标准数据格式: 定义一个包含
source,target,result_type,result_value,timestamp,details等核心字段的Pandas DataFrame格式。 - 数据库模型: 使用SQLAlchemy ORM定义与标准数据格式相匹配的数据表。
- 实现细节:
- 数据比对等数据处理模块应遵循
function(context, input_df, **options)的范式。 - 必须使用
Context来传递数据库会话。 - 可以考虑为需要原子操作的数据处理函数编写一个管理数据库事务的装饰器。
- 数据比对等数据处理模块应遵循
- 标准数据格式: 定义一个包含
6. 系统健壮性:分层异常处理与日志
- 功能描述: 系统能优雅地处理可预见的业务错误和意外的系统错误,并将详细信息记录到日志文件中,同时在数据库和UI中显示对用户友好的信息。
- 技术考量:
- 自定义异常: 建立一个继承自
PentestAppBaseException的自定义异常体系。 - 分层处理: 底层模块(如Scanner Wrappers)精准抛出自定义异常;顶层应用边界(Worker的任务执行循环)统一捕获、分类处理并归档日志。
- 实现细节:
- 这是贯穿整个项目的编程范式,不专属于某个功能。
- 在顶层捕获逻辑中,必须使用
Context中的logger对象来记录日志。
- 自定义异常: 建立一个继承自
实现细节决策矩阵
| 功能/模块 | 是否使用Protocol | 是否使用Context传递 | 是否使用装饰器 | 核心实现要点 |
|---|---|---|---|---|
| 扫描流水线 (Logic) | 否 | 是 (必须) | 可选 (用于日志或计时) | 接收和返回标准DataFrame,实现链式调用。 |
| 工具封装 (Wrappers) | 是 (强烈推荐) | 否 | 否 | 实现ScannerProtocol,返回标准DataFrame。 |
| 异步任务执行 (Worker) | 否 | 否 (在循环顶层创建) | 否 | 顶层异常捕获,从数据库取任务,更新状态。 |
| 前端UI (Streamlit Pages) | 否 | 是 (必须) | 推荐 (@with_db_session) | 只读DB状态,只写新任务到DB。 |
| 数据处理/比对 | 否 | 是 (必须) | 可选 (用于事务) | 接收标准DataFrame,与DB数据交互。 |
| 异常处理体系 | N/A | 在捕获处使用 | N/A | 自定义异常类,底层抛出,顶层捕获。 |
项目结构规划
文件结构 (第三版 - SRC目录)
[list2dt]
pentest_dashboard/ (项目根目录)
src/
pentest_dashboard/ (这是你的Python包)
init.py (可以保持应用工厂函数,或保持为空)
web/ (★ 原app目录,重命名为web,清晰表示其职责)
- init.py
- blueprints/
- static/ (★ 静态文件随web包移动)
- css/style.css
- js/main.js
- img/logo.png
- templates/ (★ 模板文件随web包移动)
- _layouts/base.html
- _includes/pagination.html
- assets/index.html
- tasks/index.html
- dashboard/index.html
- 404.html
- 500.html
core/ (★ 提升为顶级共享模块)
models/ (★ 提升为顶级共享模块)
services/ (★ 提升为顶级共享模块)
- init.py
- asset_service.py
- task_service.py
workers/ (★ 原background_worker目录,重命名并移入)
- init.py
- worker_process.py (★ 重命名worker.py以避免冲突)
- scheduler_process.py (★ 重命名scheduler.py以避免冲突)
- scanners/
- subfinder_wrapper.py
- httpx_wrapper.py
- processing/
- data_comparator.py
scripts/ (★ 新增:用于存放非包内的启动脚本)
- run_web.py (★ 原run.py,现在只负责启动Web应用)
- run_worker.py (★ 新增:启动Worker进程的脚本)
- run_scheduler.py (★ 新增:启动Scheduler进程的脚本)
tests/ (保持不变)
- test_web/ (建议创建子目录以匹配结构)
- test_blueprints.py
- test_models.py
- test_services.py
- test_web/ (建议创建子目录以匹配结构)
config.yml (保持不变)
pyproject.toml (★ 需要更新配置)
README.md (保持不变)
引入
src/pentest_dashboard/结构:- 变化: 所有Python源代码,无论是Web应用还是后台任务,都统一移入了这个目录下。
- 理由: 创建了一个单一的、可安装的Python包
pentest_dashboard。这是解决导入问题和实现代码共享的根本。
app/重命名为web/:- 变化: 原来的
app/目录现在是src/pentest_dashboard/web/。 - 理由:
app是一个比较通用的名字。web更能清晰地表明这个子包的职责是处理所有与Web服务(Flask)相关的功能。
- 变化: 原来的
static/和templates/目录移动:- 变化: 这两个目录被移入到
web/包内部。 - 理由: 它们是Web应用的专属资源,理应与Web应用的代码放在一起。在Flask中,你需要稍微调整一下应用工厂的配置,来告诉Flask从新的位置加载它们。
- 变化: 这两个目录被移入到
core/,models/,services/提升为顶级模块:- 变化: 这些目录现在直接位于
src/pentest_dashboard/之下。 - 理由: 它们是整个项目(包括Web应用和后台Worker)都需要共享的核心业务逻辑和数据模型,因此必须放在所有模块都能访问到的顶级位置。
- 变化: 这些目录现在直接位于
background_worker/合并并重命名为workers/:- 变化: 原来的独立目录被合并到
src/pentest_dashboard/workers/。内部的worker.py和scheduler.py也被重命名,以避免与Python内置的模块名潜在冲突。 - 理由: 后台任务的逻辑也是你应用源代码的一部分,理应被统一管理。现在,
workers模块可以像web模块一样,直接使用from pentest_dashboard.core import ...来导入共享配置。
- 变化: 原来的独立目录被合并到
新增
scripts/目录:- 变化: 所有用于启动进程的入口脚本(如原
run.py)都被移到了这个新的顶层目录。 - 理由: 这实现了“代码”和“执行”的分离。
src目录里是纯粹的、可被导入的Python模块(库),而scripts目录里是使用这些库来启动特定服务的脚本。
- 变化: 所有用于启动进程的入口脚本(如原
接下来要做的事情
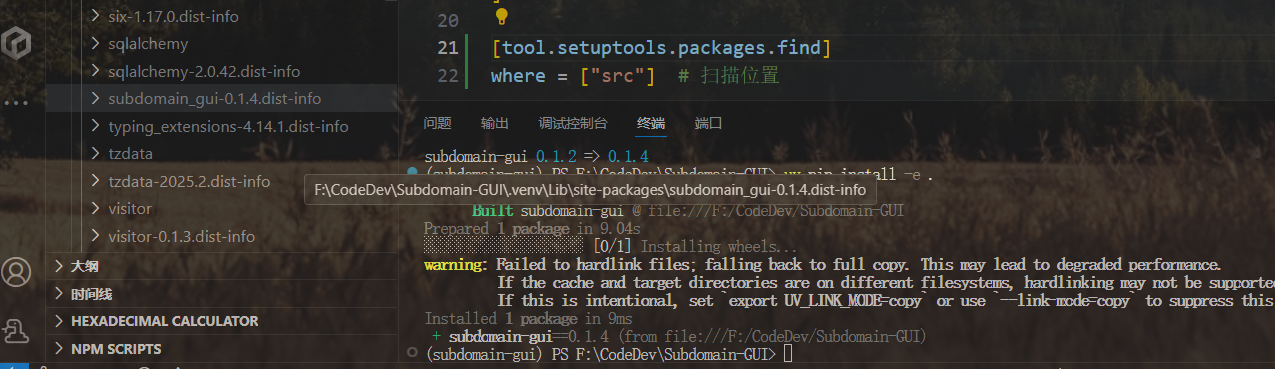
修改
pyproject.toml:[tool.setuptools.packages.find] where = ["src"] # 明确告诉构建工具源代码在src目录下同时,需要确保Flask能找到
static和templates文件夹,可以在创建Flask实例时指定路径:# 在 __init__.py 的应用工厂中 app = Flask(__name__, instance_relative_config=True, template_folder='web/templates', static_folder='web/static')安装为可编辑模式:
在项目根目录运行pip install -e .。更新所有
import语句:
这是最大但最必要的工作。将项目中所有的相对导入 (from ..core import ...) 修改为从包根开始的绝对导入 (from pentest_dashboard.core import ...)。更新
scripts/中的启动脚本:
这些脚本现在需要从安装好的包中导入应用实例或函数。# scripts/run_web.py from pentest_dashboard import create_app # 假设应用工厂在主__init__.py app = create_app() if __name__ == '__main__': app.run(debug=True)
项目数据表规划 (第二版)
需要让每个表的职责变得极其单一,并通过清晰的外键关系将它们连接起来。
核心思想:
Targets 表: 只负责管理用户提交的根目标实体。它是所有数据的顶层“所有者”。
Tasks 表: 只负责记录一个待执行或已执行的操作。它是连接“目标”和“结果”的桥梁。
Assets 表: 只负责存储扫描发现的具体资产。它是操作的产物。
以下是优化后的表结构设计
1. targets 表 (待扫描目标表)
- 职责: 管理根目标。
- target_id: INTEGER (主键)
- target_name: TEXT (唯一, 非空, 例如 'example.com')
- description: TEXT (可选)
- is_active: BOOLEAN (是否对该目标启用周期性任务)
- created_at: DATETIME
变化: 移除了所有与“任务”相关的字段(如scan_schedule)。这个表现在非常纯粹,只关心“有哪些根目标”。
2. tasks 表 (任务表)
- 职责: 记录一个操作的意图、状态和元数据。
- task_id: INTEGER (主键)
- target_id: INTEGER (非空, 外键关联到targets.target_id)
- 这明确地表示:“这个任务是针对哪个根目标的?”
- task_type: TEXT (非空, 例如 'subdomain_scan', 'liveness_check')
- 这明确地表示:“这个任务要做什么类型的操作?”
- status: TEXT (非空, 'pending', 'running', 'completed', 'failed')
- progress: REAL
- details: TEXT
- created_at: DATETIME
- started_at: DATETIME
- completed_at: DATETIME
- source_type: TEXT (可选, 'manual', 'scheduled')
- 新增字段,用于区分是用户手动创建的任务还是调度器自动创建的。
变化:
- 不再存储任何目标的值,只存储target_id作为外键引用。这解决了数据冗余。
- scan_schedule这样的调度信息不应该存在这里,它属于调度器本身的逻辑或一个单独的schedules表,而不是单个任务的属性。
3. assets 表 (资产表)
- 职责: 存储所有发现的具体产物
- asset_id: INTEGER (主键)
- target_id: INTEGER (非空, 外键关联到targets.target_id)
- 这明确地表示:“这个资产最终属于哪个根目标?” 这对于后续按根目标展示所有资产至关重要。
- source_task_id: INTEGER (非空, 外键关联到tasks.task_id)
- 这明确地表示:“这个资产是在哪一次具体的任务执行中被发现的?”
- asset_type: TEXT (非空, 'subdomain', 'live_url', 'vulnerability')
- asset_value: TEXT (非空)
- source_tool: TEXT (发现此资产的具体工具, 例如 'subfinder', 'httpx')
- details: TEXT (JSON字符串)
- first_seen_at: DATETIME
- last_seen_at: DATETIME
变化:
- 现在它有两个外键,同时关联到targets和tasks,关系变得非常清晰。
- 将source重命名为source_tool以避免与source_task_id混淆。
异常消息表
- error_id: INTEGER (主键, 自增)
- task_id: INTEGER (关联到“任务表”,表示此异常是在执行哪个任务时发生的)
- timestamp: DATETIME (异常发生的时间, ISO 8601 格式)
- error_level: TEXT (日志级别, 'WARNING' 或 'ERROR')
- exception_type: TEXT (Python异常类的名称, 例如 'ToolExecutionError', 'requests.exceptions.ConnectionError')
- error_message: TEXT (对用户友好的、或者说经过处理的错误消息)
- stack_trace: TEXT (完整的Python堆栈跟踪信息, 仅在 error_level 为 'ERROR' 时记录)
- tool_name: TEXT (如果适用,是哪个外部工具或模块抛出的异常, 例如 'subfinder', 'nuclei')
项目DataFrame结构规划
1. 规范化资产格式
这是整个系统最重要、最核心的数据格式。所有工具的扫描结果,无论其原始形态如何,最终都必须被转换成这个统一的格式。它是数据流水线中流动的标准“货币”。
用途:
- 作为所有扫描器wrapper的统一输出标准。
- 作为数据处理和比对模块的统一输入标准。
- 作为向数据库
资产表写入数据前的最终形态。
| 字段 (Column) | 数据类型 (Data Type) | 描述与示例 |
|---|---|---|
source | str | 数据来源的工具或模块名。 示例: 'subfinder', 'httpx', 'nuclei' |
asset_type | str | 资产的分类。 示例: 'subdomain', 'live_url', 'vulnerability', 'ip_address' |
asset_value | str | 资产的核心值。 示例: 'api.example.com', 'https://api.example.com:443', 'CVE-2021-44228' |
timestamp | pd.Timestamp | 发现此资产的时间戳(必须带时区信息,推荐UTC)。 示例: pd.Timestamp('2023-10-27T10:00:00Z') |
details | dict | 包含此资产所有附加信息的字典。 示例: {'status_code': 200, 'title': 'Login Page', 'severity': 'high'} |
2. 工具中间格式
这些是在各个Wrapper内部,从工具原始输出到“规范化资产格式”之间的临时形态。
a) 子域名扫描器 (如 Subfinder) 中间格式
用途: 解析Subfinder的纯文本输出。
| 字段 (Column) | 数据类型 (Data Type) | 描述与示例 |
|---|---|---|
subdomain | str | 从工具输出中直接读取的子域名。 示例: 'test.example.com' |
转换到规范化格式的逻辑:
- 将
subdomain列重命名为asset_value。 - 添加
source列,值为'subfinder'。 - 添加
asset_type列,值为'subdomain'。 - 添加
timestamp列,值为当前时间。 - 添加
details列,值为一个空的字典{}。
b) 资产探活工具 (如 HTTPX) 中间格式
用途: 解析HTTPX的JSON输出。通常使用 pd.read_json(..., lines=True) 直接生成。
| 字段 (Column) | 数据类型 (Data Type) | 描述与示例 |
|---|---|---|
url | str | 探活成功的URL。 示例: 'https://api.example.com:443' |
status-code | int | HTTP状态码。 示例: 200 |
title | str | 页面的标题。 示例: 'Example Corp Login' |
content-length | int | 响应内容的长度。 示例: 1024 |
| (...其他HTTPX输出的字段) | ... | ... |
转换到规范化格式的逻辑:
- 添加
source列,值为'httpx'。 - 添加
asset_type列,值为'live_url'。 - 将
url列的值赋给新的asset_value列。 - 添加
timestamp列,值为当前时间或HTTPX输出中的时间。 - 创建一个新的
details列,其值为一个字典,该字典包含了status-code,title,content-length等所有其他列的信息。
c) 漏洞扫描器 (如 Nuclei) 中间格式
用途: 解析Nuclei丰富的JSON输出。通常会使用 pd.json_normalize 来处理嵌套的JSON。
| 字段 (Column) | 数据类型 (Data Type) | 描述与示例 |
|---|---|---|
template-id | str | 命中的Nuclei模板ID。 示例: 'cve-2021-44228-log4j-rce' |
host | str | 存在漏洞的主机。 示例: 'http://vulnerable.example.com' |
info.name | str | 漏洞名称。 示例: 'Apache Log4j RCE' |
info.severity | str | 漏洞严重等级。 示例: 'critical' |
matched-at | str | 命中的具体URL或位置。 示例: 'http://vulnerable.example.com/login.do' |
| (...其他Nuclei输出的字段) | ... | ... |
转换到规范化格式的逻辑:
- 添加
source列,值为'nuclei'。 - 添加
asset_type列,值为'vulnerability'。 - 将
info.name列的值赋给新的asset_value列。 - 将Nuclei输出的
timestamp列转换为pd.Timestamp并赋给新的timestamp列。 - 创建一个新的
details列,其值为一个字典,包含了template-id,host,info.severity,matched-at等所有相关信息。
3. 数据比对差异格式
用途: 在数据处理模块中,用于识别和高亮新发现的资产。它是在“规范化资产格式”的基础上扩展而来的。
| 字段 (Column) | 数据类型 (Data Type) | 描述与示例 |
|---|---|---|
source | str | (同规范化格式) |
asset_type | str | (同规范化格式) |
asset_value | str | (同规范化格式) |
timestamp | pd.Timestamp | (同规范化格式) |
details | dict | (同规范化格式) |
is_new | bool | 标记此资产是否为新发现。 True 表示新资产,False 表示已知资产。 |
4. 任务监控前端格式
用途: 在Streamlit前端展示任务队列。这个格式是数据库 任务表 在内存中的直接体现。
| 字段 (Column) | 数据类型 (Data Type) | 描述与示例 |
|---|---|---|
task_id | int | 任务的唯一ID。 |
target_name | str | 关联的目标名称(通过JOIN查询获得)。 示例: 'example.com' |
task_type | str | 任务类型。 示例: 'vulnerability_scan' |
status | str | 当前状态。 示例: 'running' |
progress | float | 0.0 到 1.0 的进度。 |
details | str | 人类可读的状态描述。 示例: 'Running Nuclei on 125 live URLs...' |
created_at | pd.Timestamp | 任务创建时间。 |
API规划
程序规划
分区规划
- 任务浏览分区:查看、提交和管理任务
- 资产分区:查看扫描完成的目标,查看哪些目标等待进一步Recon扫描;高亮显示新资产和可能存在subdomain takeover的域名
- 进一步Recon扫描指的是隐藏JS文件发现(UsedJS工具)、403Bypass+目录扫描发现、隐藏HTTP参数发现(Arjun工具)和页面框架识别(httpx工具)
- 某一域名下的子域名会聚合在一起
- 这里会展示目标的页面框架,但不展示进一步的扫描结果
- 扫描分区:
- 平铺展示所有有进一步Recon结果(不包括框架指纹)的资产
基础规划
用户驱动 + 定时执行 的扫描任务
一、 任务提交与创建流程 (前端驱动)
- 用户界面 (Streamlit)
- 用户在UI上完成所有目标的配置(包括任务类型、导入方式等)。
- 当用户点击“提交”按钮时,UI将所有配置信息打包成一个标准化的数据结构(例如,一个字典列表)。
- UI调用一个单一的、原子性的后端API函数,例如 tasks.create_from_submission(submission_data),并将打包好的数据作为唯一参数传入。
- API函数调用后,UI立即向用户显示成功消息(如“任务已创建成功,请前往任务中心查看进度”),不等待任何实际的扫描或处理结果。
- 后端API (由UI调用)
- tasks.create_from_submission() 函数接收到数据后,启动一个数据库事务。
- 在事务内部,遍历传入的数据:
- 对于每个目标,首先查询待扫描目标表,如果目标不存在,则创建新记录;如果存在,则获取其target_id。
- 使用获取到的target_id,在任务表中为该目标创建一条或多条记录,状态均设为 'pending'。
- 整个循环成功完成后,提交事务。若中途发生任何错误,则回滚事务,确保数据一致性。
- 函数执行完毕并返回。
核心优化点: 前端与后端的交互被简化为一次“即发即忘”(Fire and Forget)的API调用。复杂的数据库操作被封装在后端一个原子性的事务中,大大增强了系统的健壮性和UI的响应速度。
二、 任务执行与数据处理流程 (后台独立运行)
- 任务获取 (由独立的 Worker 进程执行)
- Worker进程以固定的时间间隔(例如,每5秒)轮询任务表,查询状态为'pending'的任务。
- 当发现一个或多个pending任务时,Worker以原子方式获取其中一个(例如,使用SELECT ... FOR UPDATE SKIP LOCKED,或简单地按时间顺序取第一个),并立即将其状态更新为'running'。
- 获取到任务对象后,Worker将该对象传递给“扫描路由”进行处理。
- 任务执行 (由扫描路由模块处理)
- “扫描路由”接收到一个单一的任务对象作为输入。
- 路由根据任务对象的 task_type 字段,选择并执行相应的数据处理流水线。
- 示例 - subdomain_scan 流水线:
- 调用所有子域名扫描器Wrappers。
- 将所有扫描结果合并、去重,生成一个规范化资产格式的DataFrame。
- 将此DataFrame作为输入,继续调用资产探活模块(HTTPX Wrapper)。
- 将探活后的结果DataFrame(包含live_url等)传递给最终的数据持久化模块。
- 示例 - liveness_check 流水线:
- 直接调用资产探活模块...
- 示例 - subdomain_scan 流水线:
- 流水线执行完毕后,返回最终的结果DataFrame和执行状态(成功/失败)。
- 数据持久化与比对 (由数据处理模块执行)
- 该模块接收到来自流水线的结果DataFrame。
- 从资产表中查询该目标所有已存在的资产。
- 在内存中(使用Pandas)将新旧数据进行比对:
- 标记出“新资产” (is_new = True)。
- 标记出本次扫描依然存在的“活跃资产”。
- 识别出旧的有但本次没有的“不活跃资产”(可以选择更新其状态或保留原样)。
- 将所有新资产批量INSERT到资产表中。
- 将所有已存在的活跃资产批量UPDATE其last_seen_at等字段。
- 任务状态更新
- 在整个任务执行流程的顶层,使用一个try...except块包裹。
- 无论成功或失败,都在流程的最后一步,根据执行结果,将任务表中对应任务的status更新为'completed'或'failed',并记录完成时间和相关日志。
核心优化点: 取消了复杂的“任务队列”和“信号”机制,采用更简单、更可靠的数据库轮询模式。明确了Worker(获取任务)和Router(执行任务)的单一职责。将数据比对逻辑统一放在数据持久化之前,形成清晰的处理步骤。
三、 数据展示流程 (前端独立运行)
- 任务状态展示
- “任务浏览”分区定期(例如,每10秒)向后端发起请求,查询任务表中的最新数据。
- 后端直接返回查询结果,前端负责将不同状态的任务分类并渲染到UI上。
- 资产数据展示
- 当用户浏览资产数据并进行翻页时,Streamlit前端根据页码和每页数量计算出limit和offset值。
- 前端调用后端API,并将limit和offset作为参数传入。
- 后端SQLAlchemy模块执行带有limit和offset的数据库查询,实现在数据库层面进行分页。
- 后端将查询到的单页数据返回给前端。
- 前端Pandas模块接收到这批数据后,进行必要的聚合、排序,然后交由Streamlit渲染成图表和表格。
核心优化点: 明确了分页操作必须在数据库层面完成,避免了读取全部数据到内存的性能瓶颈,确保了即使在海量数据下UI依然能流畅响应。