Subdomain-GUI 开发随笔
技术探索
Streamlit + Pandas构建交互式Web页面
(Streamlit默认监听端口为8501)
# Hello World
# uber_pickup.py
import streamlit as st
import pandas as pd
import numpy as np
# 添加标题
st.title('Uber pickups in NYC')写好入口文件之后运行:
streamlit run uber_pickup.py提示
streamlit也支持拉取远程页面源代码并运行:
streamlit run https://raw.githubusercontent.com/streamlit/demo-uber-nyc-pickups/master/streamlit_app.pyFlask-boostrap + Jinja2 构建响应式页面
创建数据库并绑定Migrate实例
模块构建
数据库服务封装
任务创建模块
2025年8月10日 03:57:02版本:
def create_single_task(target,
scan_type: Literal[
"subdomain-scan", "alive-scan", "vuln-scan", "advanced-recon"
] = "subdomain-scan",
context: AppContext = AppContext):
# 如果插入失败, 则抛出异常
# 如果插入成功, 则返回数据对象
# _ = context._
_ = text_extractor
# 创建待扫描目标记录
with context.db.session() as session:
try:
new_target = Targets(target=target)
session.add(new_target)
session.commit()
context.logger.debug(_("Created target record for {target} successfully").format(
target=target
))
except Exception as e:
session.rollback()
raise TargetCreationError(
_("Error creating target record for {target}: {error}").format(
target=target, error=str(e)
)
)
new_task = None
try:
new_task = Tasks(target_id=new_target.target_id, type=scan_type)
session.add(new_task)
session.commit()
except Exception as e:
session.rollback()
# 回滚前面加入的目标记录
try:
session.delete(new_target)
session.commit()
except:
session.rollback()
raise TaskCreationError(
_("Error creating task record for {target}: {error}").format(
target=target, error=str(e)
)
)
return new_target, new_task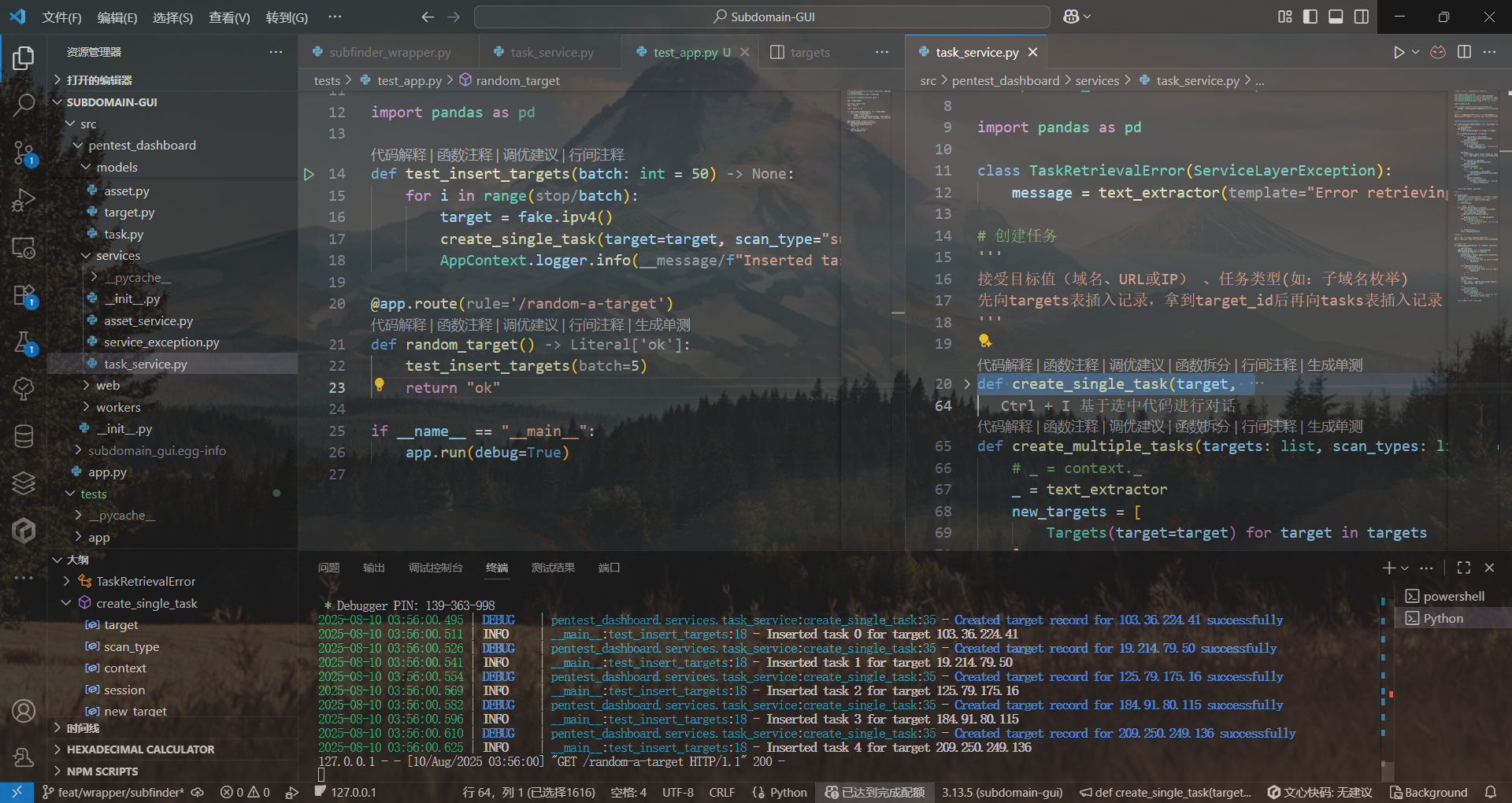
人麻了,要日志有日志,要调试有调试,怎么就是创建不了记录呢??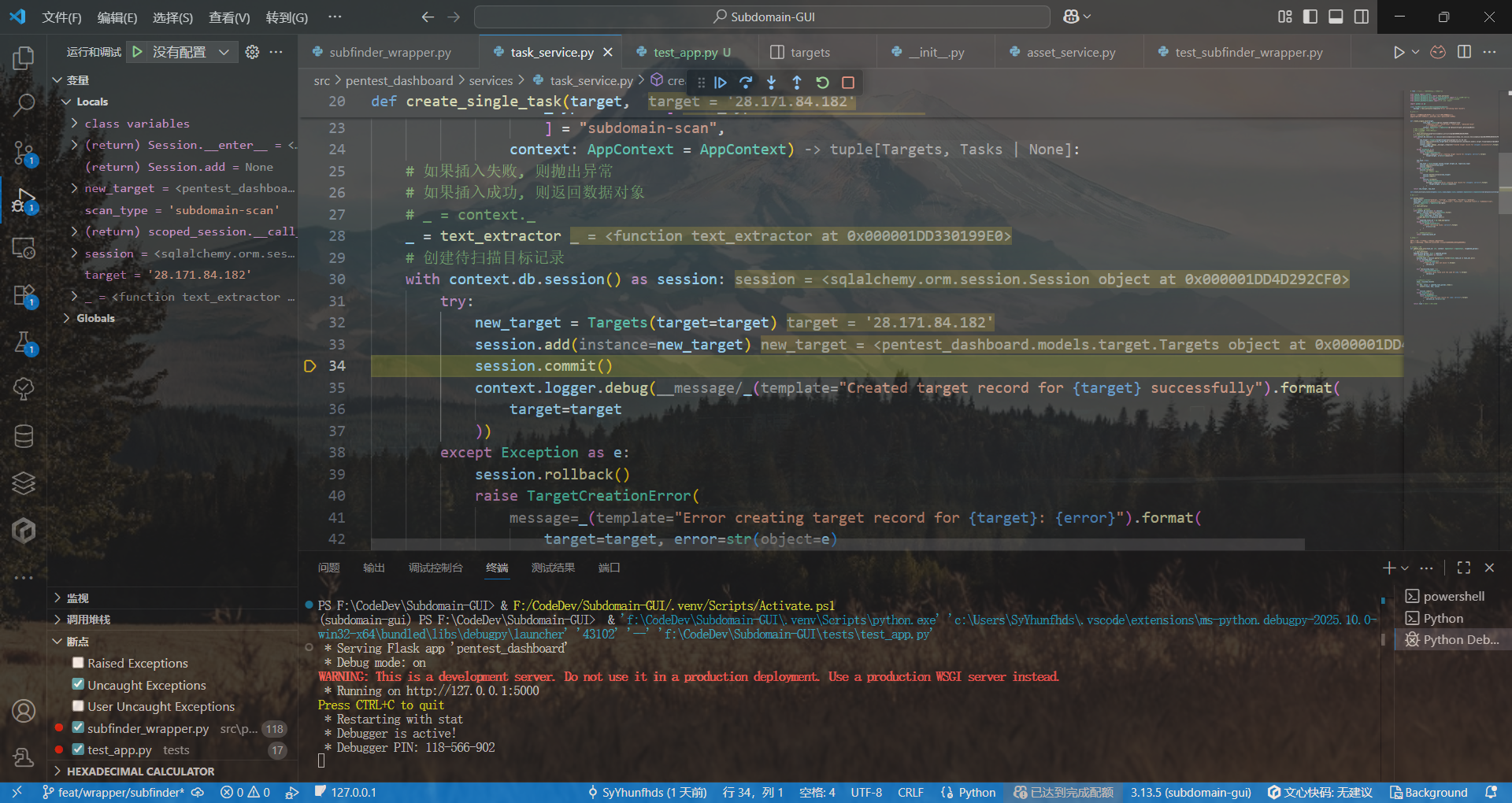
数据实例也能创建,但好像提交不了事务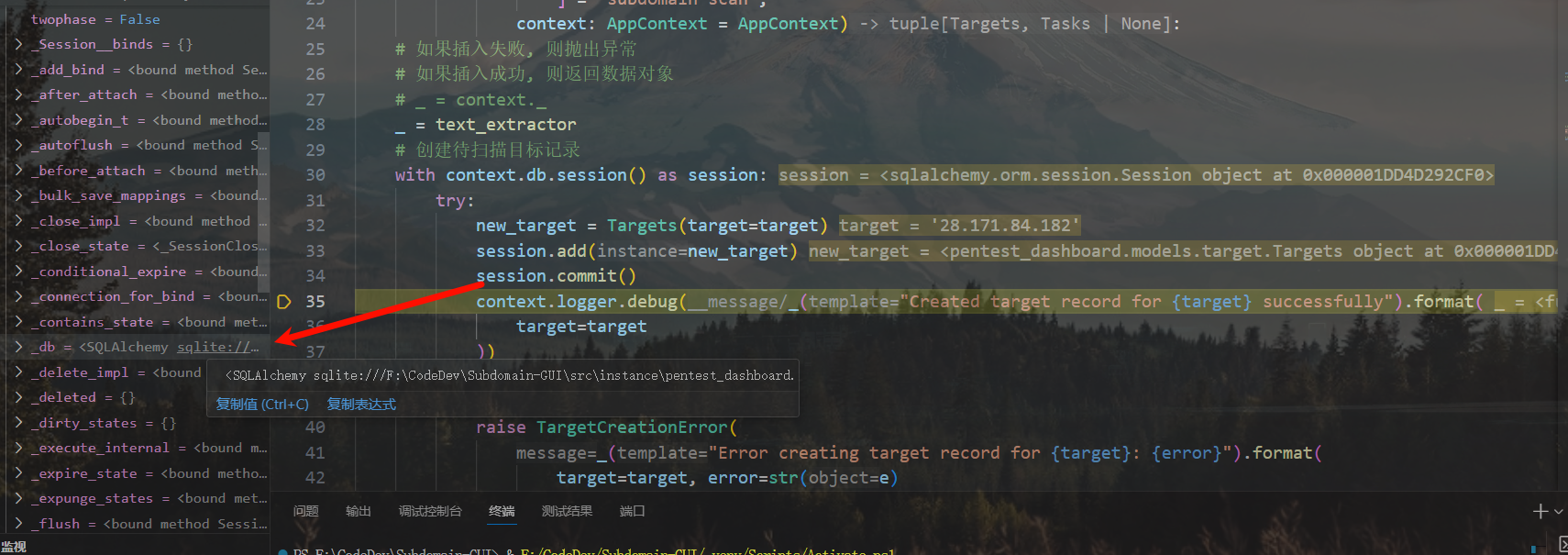
绷不住了,这不是有事务的嘛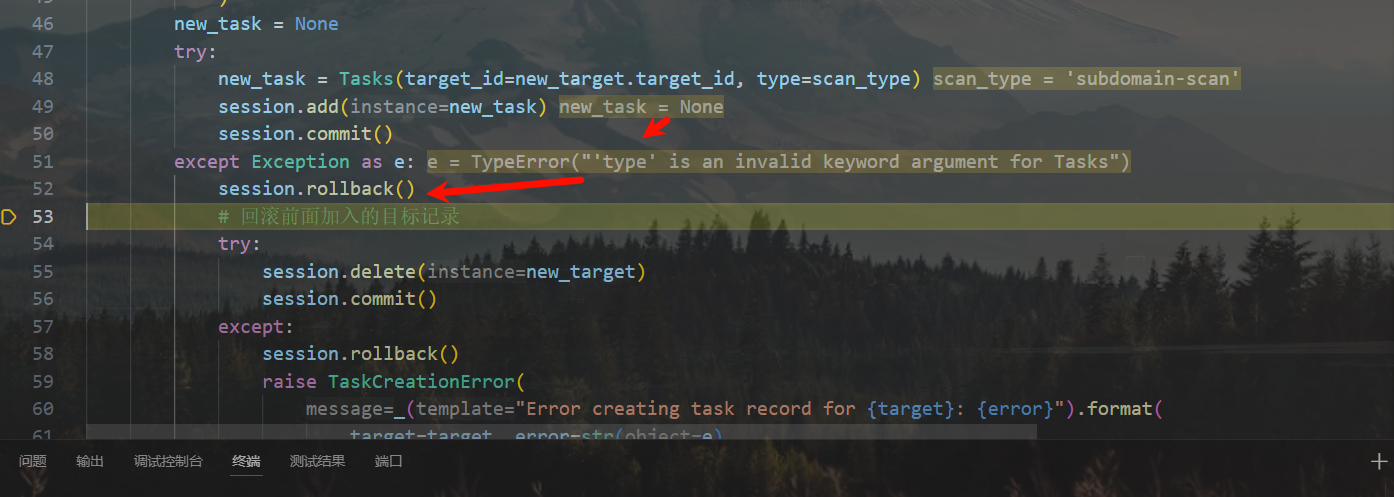
原来是因为给错类型了,导致Task没创建出来,然后回滚了前面的目标添加记录
subfinder Python封装器
命令构造不成问题,问题是如何调用和跟踪任务ID?
一开始的想法是外部向函数内传入线程池,扫描器内直接向线程池提交任务,但这样的话一来没办法追踪任务,二来定时轮询会卡住主线程
如何提交和跟踪任务
旧方法:本地线程池与同步轮询
劣势总结
缺乏身份与追踪: 提交到线程池中的任务是匿名的,没有唯一的标识符(Key)。这使得上层调用者无法区分和追踪多个并发执行的任务,如同发射后不管的石子。
状态不可见: 任务的执行状态(如“正在运行”、“已完成”、“失败”)被封装在后台线程内部,对系统的其他部分是不可见的。无法构建一个全局的任务监控仪表盘。
阻塞式的伪异步: 调用方虽然没有被函数直接阻塞,但为了获取结果,它必须自己实现一个循环去“同步地”轮询一个本地的结果队列或Future对象。这仍然占用了调用方的资源和逻辑,没有实现真正的解耦。
脆弱的通信: 如果需要传递进度,只能通过复杂的、内存中的回调函数或队列实现。如果主进程或调用方崩溃,所有与后台任务的通信都会中断,任务状态会永久丢失。
不可扩展性: 这种模式完全局限于单个进程。当需要将任务分发到不同的机器或更多的Worker进程时,整个架构需要被完全推翻。
资源浪费: 调用方需要花费CPU周期去执行轮询逻辑,而不是专注于自己的核心职责。
新方法:持久化状态机与分布式任务
优势总结
任务拥有唯一身份: 每个任务在创建时就被赋予一个全局唯一的task_id,并记录在持久化的数据库中。这个ID是它在整个系统生命周期中的“GPS追踪器”。
状态持久化与可观测性: 任务的完整生命周期(pending, running, completed, failed)和详细进度都被记录在中央数据库中。这使得任何有权访问数据库的模块(如Web前端)都可以随时查询任何任务的实时状态。
真正的异步与解耦: 调用者(Worker)的职责被简化为“派发任务”。它将task_id传递给执行器后,它的工作就完成了,可以立即处理下一个任务。它不关心任务何时完成,也不等待返回值。
健壮的通信机制: 系统各部分(调度器、工作者、前端)通过读写数据库这一“指挥中心”来进行通信。这是一种极其健壮、可靠的异步通信方式,即使部分组件重启或崩溃,系统的状态信息也不会丢失。
高可扩展性: 整个架构天然支持分布式。当任务量增加时,只需简单地增加更多的Worker进程(甚至可以在不同的机器上),它们都会从同一个数据库任务队列中获取任务,系统性能可以水平扩展。
职责单一清晰: Worker只管派发,Scanner只管执行并汇报状态,Frontend只管读取状态并展示。每个组件的职责都高度内聚,使得系统极易维护和理解。
类似于下面这样:
# src/pentest_dashboard/workers/scanners/subfinder_wrapper.py
from pentest_dashboard.core.context import AppContext # 我们需要它来更新数据库
import subprocess
import pandas as pd
class SubfinderWrapper:
name: str = "Subfinder"
def scan(self, context: AppContext, task_id: int, target: str, **kwargs) -> None:
"""
执行Subfinder扫描,并将过程和结果直接与数据库交互。
这个函数不再返回DataFrame,它的职责是完成一个被追踪的任务。
"""
# 1. ★ 任务开始:更新指挥中心的状态
context.logger.info(f"[Task ID: {task_id}] 开始使用 {self.name} 扫描 {target}...")
try:
# 更新数据库,告诉所有人这个任务已经开始运行了
update_task_status(context.db.session, task_id, 'running',
details=f"Executing {self.name}...")
# 2. ★ 执行耗时操作
# 使用Popen来避免阻塞,并实时捕获输出
process = subprocess.Popen(
["subfinder", "-d", target, "-silent"],
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
text=True
)
# 你可以在这里读取stdout来更新更详细的进度,如果工具支持的话
# for line in process.stdout:
# update_task_details(..., f"Found: {line.strip()}")
# 等待进程结束
stdout, stderr = process.communicate(timeout=kwargs.get("timeout", 300))
if process.returncode != 0:
raise ToolExecutionError(self.name, "Process failed", stderr=stderr)
# 3. ★ 处理结果:将结果直接写入数据库
subdomains = stdout.strip().split('\n')
results_df = pd.DataFrame(subdomains, columns=['asset_value'])
# 将这个DataFrame转换并持久化到数据库
# 这个函数内部会处理数据比对和写入`资产表`的逻辑
persist_scan_results(context, task_id, target, results_df)
# 4. ★ 任务结束:再次更新指挥中心的状态
update_task_status(context.db.session, task_id, 'completed',
details="Scan finished successfully.")
context.logger.success(f"[Task ID: {task_id}] 扫描成功完成。")
except Exception as e:
# 5. ★ 异常处理:如果出错了,也要报告给指挥中心
context.logger.error(f"[Task ID: {task_id}] 扫描失败: {e}")
update_task_status(context.db.session, task_id, 'failed',
details=str(e))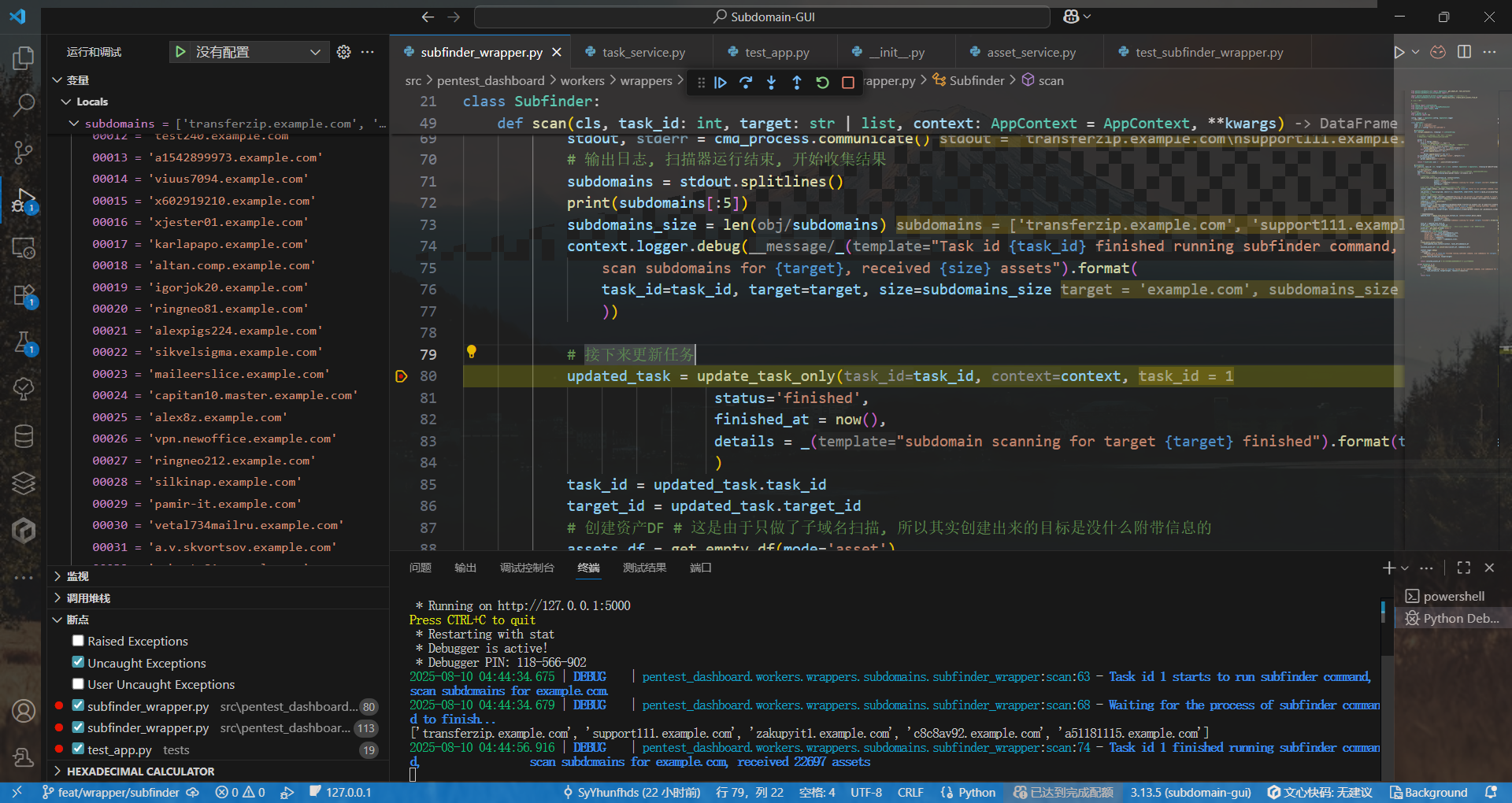
差一点……没法进一步更新任务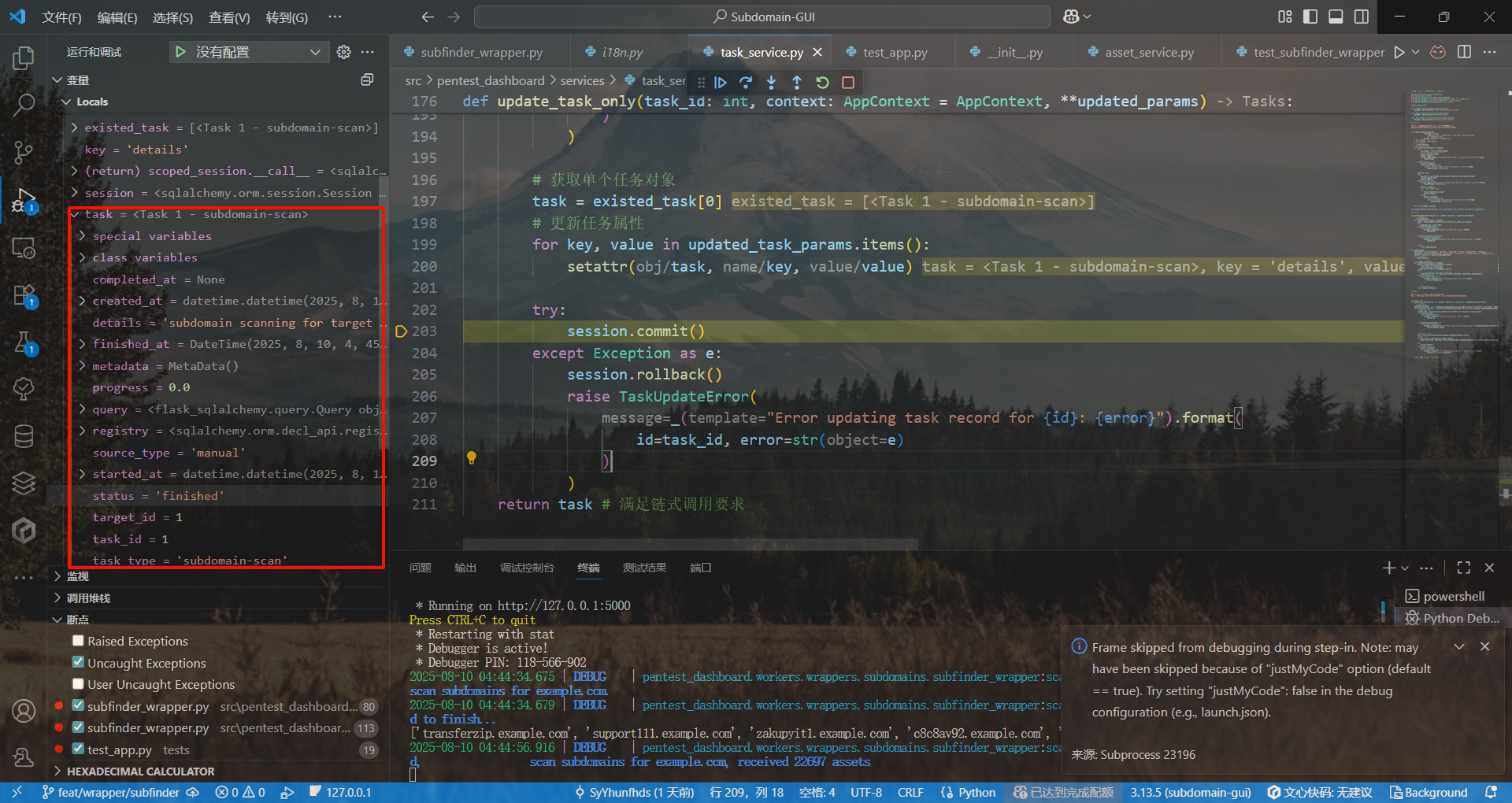
Task实例的属性已经得到了更改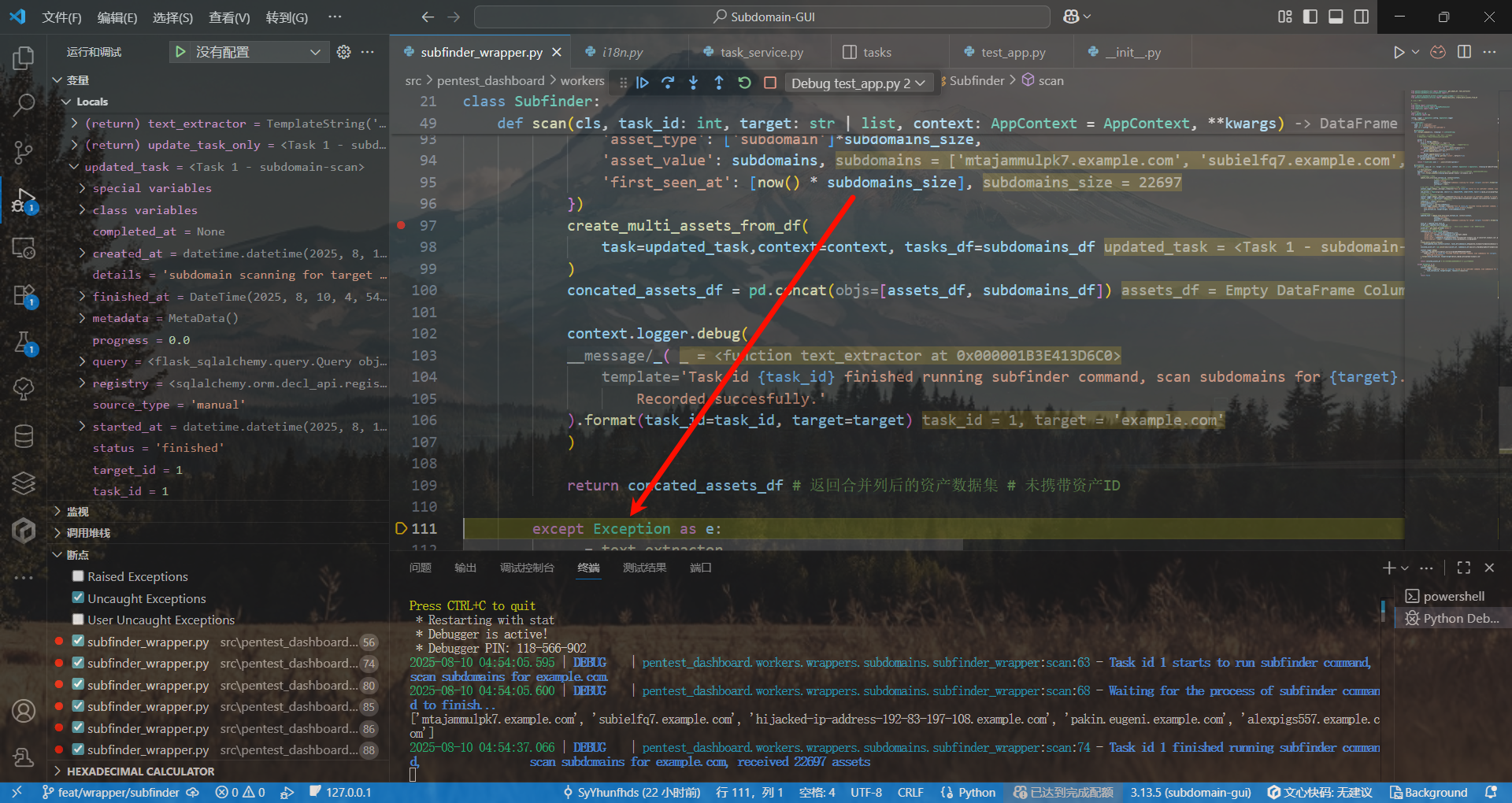
好像是因为20000多次求值直接干出溢出了……
不是因为太多次求值,而是因为在db上下文之外进行了查询……
麻痹终于测出来了
完事了call AI出来擦屁股