Aoc Kotlin个人解题记录(二)
Day 3
Part 1:最大后缀
题目描述
You descend a short staircase, enter the surprisingly vast lobby, and are quickly cleared by the security checkpoint. When you get to the main elevators, however, you discover that each one has a red light above it: they're all offline.
"Sorry about that," an Elf apologizes as she tinkers with a nearby control panel. "Some kind of electrical surge seems to have fried them. I'll try to get them online soon."
You explain your need to get further underground. "Well, you could at least take the escalator down to the printing department, not that you'd get much further than that without the elevators working. That is, you could if the escalator weren't also offline."
"But, don't worry! It's not fried; it just needs power. Maybe you can get it running while I keep working on the elevators."
There are batteries nearby that can supply emergency power to the escalator for just such an occasion. The batteries are each labeled with their joltage rating, a value from 1 to 9. You make a note of their joltage ratings (your puzzle input). For example:
987654321111111
811111111111119
234234234234278
818181911112111The batteries are arranged into banks; each line of digits in your input corresponds to a single bank of batteries. Within each bank, you need to turn on exactly two batteries; the joltage that the bank produces is equal to the number formed by the digits on the batteries you've turned on. For example, if you have a bank like 12345 and you turn on batteries 2 and 4, the bank would produce 24 jolts. (You cannot rearrange batteries.)
You'll need to find the largest possible joltage each bank can produce. In the above example:
- In
_98_7654321111111, you can make the largest joltage possible,98, by turning on the first two batteries. - In
_8_1111111111111_9_, you can make the largest joltage possible by turning on the batteries labeled8and9, producing89jolts. - In
2342342342342_78_, you can make78by turning on the last two batteries (marked7and8). - In
818181_9_1111_2_111, the largest joltage you can produce is92.
The total output joltage is the sum of the maximum joltage from each bank, so in this example, the total output joltage is 98 + 89 + 78 + 92 = _357_.
There are many batteries in front of you. Find the maximum joltage possible from each bank; what is the total output joltage?
题目大意是在一个数字字符串里找两个数字,满足相加之和最大;选择的第二个数字必须在第一个数字右边,不能调换顺序
与Gemini老师的思路探讨
- Q:一个十进制数字,它本身的数值大小和它每个位的数字之和大小有相关性吗?或者说它本身很大,它每个位上的数字之和也应该很大吗
A:
解题代码
| 计算思路 | 输出 | 备注 |
|---|---|---|
| 【贪心算法】 字符串逐位转 Int,构造List<Int>先调用一次 max()拿到第一大的数,并调用indexOf拿到它的索引然后调用 drop抛弃第一大的数及其左边的所有元素在剩下的字符串中再次调用 max寻找第二大的元素 | NoSuchElementException | 当第一大的数在末尾时, 切割子列表会切出空列表 这时再调用 max会抛出NoSuchElementException因为迭代器没有 Next元素 |
| 【动态规划】 倒序遍历 List<Int>,构建从列表元素到其对应的另一个最大值的Map,之后对Map进行键值对遍历,找到两数之和最大的键值对即可 遍历 List构造Map时需要忽略列表末尾的元素 | 17408 | 实际实现时针对序列末尾 进行了分支情况剪枝 |
| 计算思路 | 关键计算代码 |
|---|---|
字符串逐位转Int,构造List<Int>先调用一次 max()拿到第一大的数,并调用indexOf拿到它的索引然后调用 drop抛弃第一大的数及其左边的所有元素在剩下的字符串中再次调用 max寻找第二大的元素 | infix fun findBatteriesFromString(input: String): Int? { println("processing $input") val digits = buildList { for (numChar in input) { // 数字字符转对应的数值 add(numChar.digitToInt()) } } if (digits.count() == 0) {return null} val firstMax = digits.max().also { println("found 1st max number $it in $input") } val firstMaxIndex = digits.indexOf(firstMax) // 丢弃最大元素及其左边的元素, 在剩下的子元素里找第二大的元素 val secondMax = digits.drop(firstMaxIndex + 1).max().also { println("found 2nd max number $it in $input") } // 换一个扩展函数, 跟max函数差不多, 只是会跳过给定索引及其之前的元素 // val secondMax = digits.secondMax(firstMaxIndex) // 无法忽略第一个最大的数 return secondMax?.let { secondMax + firstMax * 10 } } |
| 【动态规划】 倒序遍历 List<Int>,构建从列表元素到其对应的另一个最大值的Map,之后对Map进行键值对遍历,找到两数之和最大的键值对即可 遍历 List构造Map时需要忽略列表末尾的元素 | infix fun findBatteriesFromString(input: String): Int? { // println("processing $input") val digits = input.map { it.digitToInt() } if (digits.size <= 1) {return null} // 使用 动态规划/最大后缀值算法 // 一步到位计算当前值(作为十位)与最大后缀(作为个位)的构造值 val dSize = digits.size val maxBatteriesCouple = IntArray(dSize) maxBatteriesCouple [dSize - 1] = -1 // 对应数值序列末尾的数字 maxBatteriesCouple [dSize - 2] = digits[dSize - 1] + 10*digits[dSize - 2] var currPostfixMax = maxOf( digits[dSize - 1], digits[dSize - 2]) // 略过末位 for (i in (digits.size - 3) downTo 0) { currPostfixMax = maxOf(currPostfixMax, digits[i + 1]) // 跟当前数值的前一个数比较 maxBatteriesCouple[i] = currPostfixMax + 10*``digits[i] } return maxBatteriesCouple.max().also { batteries.add(it) } } |
class Day3 {
val password: Int
get() = batteries.sum()
private var batteries: MutableList<Int> = mutableListOf()
fun reset() {
batteries = mutableListOf()
}
infix fun findBatteriesFromString(input: String): Int? {
// println("processing $input")
val digits = input.map { it.digitToInt() }
if (digits.size <= 1) {return null}
// 使用 动态规划/最大后缀值算法
// 一步到位计算当前值(作为十位)与最大后缀(作为个位)的构造值
val dSize = digits.size
val maxBatteriesCouple = IntArray(dSize)
maxBatteriesCouple[dSize - 1] = -1 // 对应数值序列末尾的数字
maxBatteriesCouple[dSize - 2] = digits[dSize - 1] + 10*digits[dSize - 2]
var currPostfixMax = maxOf(digits[dSize - 1], digits[dSize - 2])
// 略过末位
for (i in (digits.size - 3) downTo 0) {
currPostfixMax = maxOf(currPostfixMax, digits[i + 1])
// 跟当前数值的前一个数比较
maxBatteriesCouple[i] = currPostfixMax + 10*digits[i]
}
return maxBatteriesCouple.max().also { batteries.add(it) }
}
infix fun findBatteries(input: Long): Int? = this
// .also { println("processing $input") }
.findBatteriesFromString(input.toString())
infix fun findBatteriesFromFile(filename: String): Int? {
val file = File(filename)
if (!(file.exists() and file.isFile)) {
println("Cannot find puzzle input file with path: ${file.absolutePath}")
return null
}
file.readText().lines().forEach { findBatteriesFromString(it) }
return password
}
companion object Runner {
fun main() {
val solver = Day3()
val filename = "src/main/resources/puzzles/2025/day3-part1.txt"
solver.findBatteriesFromFile(filename)?.
let { println("The answer is ${solver.password}") }
}
}
}Part 2:受限最大子序列
题目描述
The escalator doesn't move. The Elf explains that it probably needs more joltage to overcome the static friction of the system and hits the big red "joltage limit safety override" button. You lose count of the number of times she needs to confirm "yes, I'm sure" and decorate the lobby a bit while you wait.
Now, you need to make the largest joltage by turning on exactly twelve batteries within each bank.
The joltage output for the bank is still the number formed by the digits of the batteries you've turned on; the only difference is that now there will be _12_ digits in each bank's joltage output instead of two.
Consider again the example from before:
987654321111111
811111111111119
234234234234278
818181911112111Now, the joltages are much larger:
- In
_987654321111_111, the largest joltage can be found by turning on everything except some1s at the end to produce_987654321111_. - In the digit sequence
_81111111111_111_9_, the largest joltage can be found by turning on everything except some1s, producing_811111111119_. - In
23_4_2_34234234278_, the largest joltage can be found by turning on everything except a2battery, a3battery, and another2battery near the start to produce_434234234278_. - In
_8_1_8_1_8_1_911112111_, the joltage_888911112111_is produced by turning on everything except some1s near the front.
The total output joltage is now much larger: 987654321111 + 811111111119 + 434234234278 + 888911112111 = _3121910778619_.
解题代码
| 计算思路 | 输出 | 备注 |
|---|---|---|
| 【单调栈】 从左到右顺序扫描字符串,比较新数字和栈顶的数字, 大于的话就pop栈顶,然后push新的数字 如果到字符串末尾的距离等于栈空间余量 就直接push完剩余所有数字 | (栽在第二个输入上) | 如果一个较大的数前面 有多个很小的数字, 这个较大的数会被顶到 栈的末尾,在截断环节 可能会被错误移除 |
| 【单调栈/思路同上】 使用 mutableList<Char>缓存数字 | 130107952063486 | 算法存在博弈问题 |
| 【优先队列】 将数字列表按大小进行降序重排,取前N位数字 按照原始索引重新排列 | 存在边缘情况 | |
| 【单调栈/剩余名额管理优化】 不再计算栈的剩余容量,而是计算 还可以丢弃多少位 数字 |
| 计算思路 | 关键计算代码 |
|---|---|
| 【单调栈】 从左到右顺序扫描字符串,比较新数字和栈顶的数字, 大于的话就pop栈顶,然后push新的数字 如果到字符串末尾的距离等于栈空间余量 就直接push完剩余所有数字 | 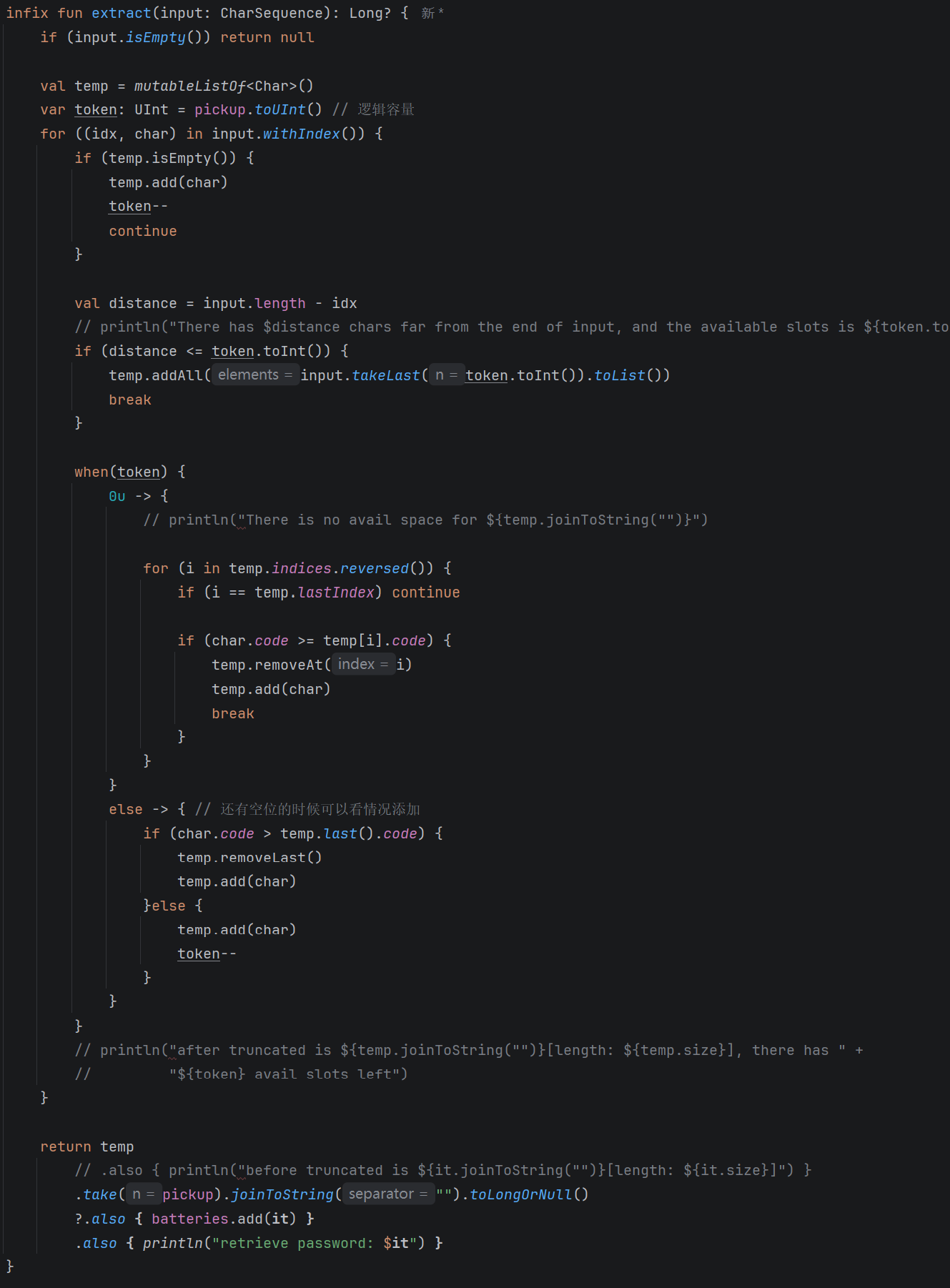 |
| 【单调栈-优化】 通过有限删除名额, 将全局组合问题降维 为局部比较。关键 在于维护栈单调性, 仅比较新元素与栈顶, 遇更大元素且有名额 则弹出栈顶,形成 连锁反应。此策略 利用贪心无后效性, 优先保证高位最大化, 实现O(n)时间复杂度, 大幅优化代码量 与运行效率。 | 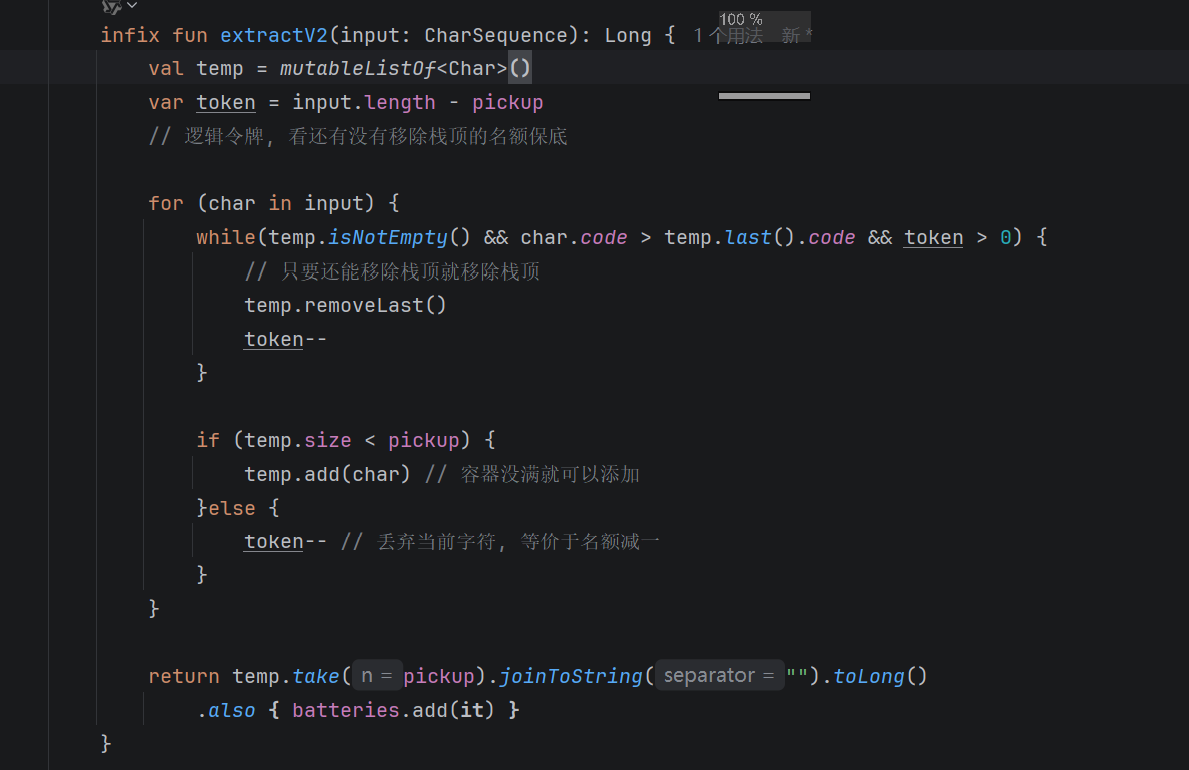 |
class Day3Part2Fix(
val pickup: Int = 12, // 取前N位数字
) {
var password: Long = 0L
get(): Long = batteries
/*
.also {
var sum: Long = 0L
for (num in batteries) {
val old = sum
sum += num
if (sum < old) {
throw IllegalStateException("The sum of batteries is overflowed")
}
println("${Long.MAX_VALUE} - $sum = ${Long.MAX_VALUE - sum}")
}
}
* */
.asSequence().sum()
val batteries: MutableList<Long> = mutableListOf()
fun reset() = batteries.clear()
infix fun extract(input: CharSequence): Long? {
if (input.isEmpty()) return null
val temp = mutableListOf<Char>()
var token: UInt = pickup.toUInt() // 逻辑容量
for ((idx, char) in input.withIndex()) {
if (temp.isEmpty()) {
temp.add(char)
token--
continue
}
val distance = input.length - idx
// println("There has $distance chars far from the end of input, and the available slots is ${token.toInt()}")
if (distance <= token.toInt()) {
temp.addAll(input.takeLast(token.toInt()).toList())
break
}
when(token) {
0u -> {
// println("There is no avail space for ${temp.joinToString("")}")
for (i in temp.indices.reversed()) {
if (i == temp.lastIndex) continue
if (char.code >= temp[i].code) {
temp.removeAt(i)
temp.add(char)
break
}
}
}
else -> { // 还有空位的时候可以看情况添加
if (char.code > temp.last().code) {
temp.removeLast()
temp.add(char)
}else {
temp.add(char)
token--
}
}
}
// println("after truncated is ${temp.joinToString("")}[length: ${temp.size}], there has " +
// "${token} avail slots left")
}
return temp
// .also { println("before truncated is ${it.joinToString("")}[length: ${it.size}]") }
.take(pickup).joinToString("").toLongOrNull()
?.also { batteries.add(it) }
.also { println("retrieve password: $it") }
}
infix fun extractV2(input: CharSequence): Long {
val temp = mutableListOf<Char>()
var token = input.length - pickup
// 逻辑令牌, 看还有没有移除栈顶的名额保底
for (char in input) {
while(temp.isNotEmpty() && char.code > temp.last().code && token > 0) {
// 只要还能移除栈顶就移除栈顶
temp.removeLast()
token--
}
if (temp.size < pickup) {
temp.add(char) // 容器没满就可以添加
}else {
token-- // 丢弃当前字符, 等价于名额减一
}
}
return temp.take(pickup).joinToString("").toLong()
.also { batteries.add(it) }
}
infix fun extractFromFile(filename: String): Long? {
val file = File(filename)
if (!(file.exists() and file.isFile)) {
println("Cannot find puzzle input file with path: ${file.absolutePath}")
return null
}
file.bufferedReader().useLines { lines ->
lines.forEach { extractV2(it) }
}
return password
}
companion object Runner {
fun main() {
val solver = Day3Part2Fix()
val filename = "src/main/resources/puzzles/2025/day3-part1.txt"
solver.extractFromFile(filename)?.
let { println("The answer is ${solver.password}") }
}
}
}使用到的API和语法以及优化建议
Day 4
Part 1:邻近计数
题目描述
You ride the escalator down to the printing department. They're clearly getting ready for Christmas; they have lots of large rolls of paper everywhere, and there's even a massive printer in the corner (to handle the really big print jobs).
Decorating here will be easy: they can make their own decorations. What you really need is a way to get further into the North Pole base while the elevators are offline.
"Actually, maybe we can help with that," one of the Elves replies when you ask for help. "We're pretty sure there's a cafeteria on the other side of the back wall. If we could break through the wall, you'd be able to keep moving. It's too bad all of our forklifts are so busy moving those big rolls of paper around."
If you can optimize the work the forklifts are doing, maybe they would have time to spare to break through the wall.
The rolls of paper (@) are arranged on a large grid; the Elves even have a helpful diagram (your puzzle input) indicating where everything is located.
For example:
..@@.@@@@.
@@@.@.@.@@
@@@@@.@.@@
@.@@@@..@.
@@.@@@@.@@
.@@@@@@@.@
.@.@.@.@@@
@.@@@.@@@@
.@@@@@@@@.
@.@.@@@.@.The forklifts can only access a roll of paper if there are fewer than four rolls of paper in the eight adjacent positions. If you can figure out which rolls of paper the forklifts can access, they'll spend less time looking and more time breaking down the wall to the cafeteria.
In this example, there are _13_ rolls of paper that can be accessed by a forklift (marked with x):
..xx.xx@x.
x@@.@.@.@@
@@@@@.x.@@
@.@@@@..@.
x@.@@@@.@x
.@@@@@@@.@
.@.@.@.@@@
x.@@@.@@@@
.@@@@@@@@.
x.x.@@@.x.Consider your complete diagram of the paper roll locations. How many rolls of paper can be accessed by a forklift?
总结就是:数数卷纸旁边有几筒卷纸,小于4筒就可以标记为×
解题代码
| 计算思路 | 输出 | 备注 |
|---|---|---|
| 【工程】 协程扫描每一行,穷举 可以存活的个数 |
| 计算思路 | 关键计算代码 |
|---|
Part 2
题目描述
解题代码
| 计算思路 | 输出 | 备注 |
|---|---|---|
| 【工程】 协程扫描每一行,穷举 可以存活的个数 |
package org.example.Day4
import kotlinx.coroutines.Dispatchers
import kotlinx.coroutines.coroutineScope
import kotlinx.coroutines.launch
import kotlinx.coroutines.runBlocking
import kotlinx.coroutines.withContext
import java.io.File
import java.util.concurrent.atomic.*
import kotlin.system.measureNanoTime
data class Coordinate(val row: Int, val col: Int)
enum class Direction {
UP, DOWN, LEFT, RIGHT,
UP_RIGHT, UP_LEFT, DOWN_RIGHT, DOWN_LEFT
}
enum class ScanMode {
SCAN_ROW, SCAN_COL
}
abstract class Map {
val symbolEmpty: Char = '.'
val symbolStuff: Char = '@'
abstract val width: Int
abstract val height: Int
abstract val diagram: Array<CharSequence>
// 要使给定坐标的格子可以存活,其周围八个格子可不为空的限额数量
val aliveToken = 4
init {
require(symbolEmpty != symbolStuff) { "Blank tags and filled tags cannot be the same" }
}
// 查看某点周围的情况
fun peekWhere(coordinate: Coordinate, direction: Direction = Direction.UP): Char {
val newX = when (direction) {
Direction.LEFT, Direction.DOWN_LEFT, Direction.UP_LEFT -> coordinate.col - 1
Direction.RIGHT, Direction.DOWN_RIGHT, Direction.UP_RIGHT -> coordinate.col + 1
else -> coordinate.col
}
val newY = when (direction) {
Direction.UP, Direction.UP_LEFT, Direction.UP_RIGHT -> coordinate.row - 1
Direction.DOWN, Direction.DOWN_LEFT, Direction.DOWN_RIGHT -> coordinate.row + 1
else -> coordinate.row
}
return if (newX in 0 until width && newY in 0 until height) {
diagram[newY][newX]
} else {
symbolEmpty
}
}
fun isWhereNotEmpty(coordinate: Coordinate, direction: Direction = Direction.UP): Boolean {
return peekWhere(coordinate, direction) != symbolEmpty
}
infix fun peekUp(coordinate: Coordinate): Char = peekWhere(coordinate, Direction.UP)
infix fun peekDown(coordinate: Coordinate): Char = peekWhere(coordinate, Direction.DOWN)
infix fun peekLeft(coordinate: Coordinate): Char = peekWhere(coordinate, Direction.LEFT)
infix fun peekRight(coordinate: Coordinate): Char = peekWhere(coordinate, Direction.RIGHT)
infix fun peekUpRight(coordinate: Coordinate): Char = peekWhere(coordinate, Direction.UP_RIGHT)
infix fun peekUpLeft(coordinate: Coordinate): Char = peekWhere(coordinate, Direction.UP_LEFT)
infix fun peekDownRight(coordinate: Coordinate): Char = peekWhere(coordinate, Direction.DOWN_RIGHT)
infix fun peekDownLeft(coordinate: Coordinate): Char = peekWhere(coordinate, Direction.DOWN_LEFT)
fun isUpNotEmpty(coordinate: Coordinate): Boolean = isWhereNotEmpty(coordinate, Direction.UP)
fun isDownNotEmpty(coordinate: Coordinate): Boolean = isWhereNotEmpty(coordinate, Direction.DOWN)
fun isLeftNotEmpty(coordinate: Coordinate): Boolean = isWhereNotEmpty(coordinate, Direction.LEFT)
fun isRightNotEmpty(coordinate: Coordinate): Boolean = isWhereNotEmpty(coordinate, Direction.RIGHT)
fun isUpRightNotEmpty(coordinate: Coordinate): Boolean = isWhereNotEmpty(coordinate, Direction.UP_RIGHT)
fun isUpLeftNotEmpty(coordinate: Coordinate): Boolean = isWhereNotEmpty(coordinate, Direction.UP_LEFT)
fun isDownRightNotEmpty(coordinate: Coordinate): Boolean = isWhereNotEmpty(coordinate, Direction.DOWN_RIGHT)
fun isDownLeftNotEmpty(coordinate: Coordinate): Boolean = isWhereNotEmpty(coordinate, Direction.DOWN_LEFT)
fun _cannotSurvive(coordinate: Coordinate, doWhenTrue: (CharArray?) -> Unit = {}): Boolean {
var token = aliveToken
// Direction.entries 在Kotlin 1.9后可用
for (diretcion in Direction.entries) {
if (isWhereNotEmpty(coordinate, diretcion)) token--
// 周围格子不为空的数量已达到阈值(4)
if (token <= 0) return false
}
doWhenTrue(null)
return true
}
abstract fun cannotSurvive(coordinate: Coordinate): Boolean
// 扫描某行的统计可以存活的格子数目
fun scanRow(row: Int): Int{
if (row >= height) return 0
return buildList {
for (col in 0 until width) {
if (diagram[row][col] == symbolStuff) {
add(
cannotSurvive(Coordinate(row, col))
/*
.also {
if (it) println("($row, $col) can survive") else println("($row, $col) cannot survive")
}
* */
)
}
}
}.sumOf { if(it) 1 else 0 }
}
fun scanCol(col: Int): Int{
if (col >= width) return 0
return buildList {
for (row in 0 until height) {
if (diagram[row][col] == symbolStuff) {
add(cannotSurvive(Coordinate(row, col)))
}
}
}.sumOf { if(it) 1 else 0 }
}
// 扫描地图网格
suspend fun scan(counter: AtomicInteger = AtomicInteger(0), mode: ScanMode = ScanMode.SCAN_ROW): Int {
when(mode) {
ScanMode.SCAN_ROW -> {
// coroutineScope也可以阻塞进程执行其作用域内的协程
withContext(Dispatchers.Default) {
coroutineScope {
for (row in 0 until height) {
launch {
counter.addAndGet(scanRow(row))
// .also { println("Row ${row + 1} process done, now we have ${counter.get()} paper rolls which can live until next round") }
}
}
}
}
}
else -> {println("Not implemented yet")} // 置空
}
return counter.get()
}
fun scanSync(counter: AtomicInteger = AtomicInteger(0)): Int {
for (row in 0 until height) {
// 彻底不用 launch,不用 coroutineScope,就用最原始的循环
val rowResult = scanRow(row)
counter.addAndGet(rowResult)
// println("Row ${row + 1} done")
}
return counter.get()
}
}
open class Part1(width: Int = 0, height: Int = 0) : Map() {
override var width: Int = width
override var height: Int = height
override var diagram: Array<CharSequence> = arrayOf()
set(value) {
field = value
width = value.maxOfOrNull { it.length } ?: 0 // 以最短行的长度作为宽度
height = value.size
}
override fun cannotSurvive(coordinate: Coordinate): Boolean = _cannotSurvive(coordinate, {})
// 从文件中加载题目(可能会耗时很久)
infix fun loadFromFile(fileName: String): Boolean {
val file = File(fileName)
if (!file.exists() || !file.isFile) return false
// Return nothing if the file does not exist or is not a file
// WTF data type transformation
val raw = file.readText().lines().map { it.trim() }.filter { it.isNotEmpty() }.toTypedArray()
this.diagram = raw.map { it.trim() }.toTypedArray()
return true
}
companion object Runner {
fun timeTest() {
val filename = "src/main/resources/puzzles/2025/day4-part1.txt"
val solver = Part1()
if (!(solver loadFromFile filename)) {
println("Failed to load puzzle from file $filename")
return
}
var time = buildList {
for (i in 1..10) {
add(measureNanoTime {
runBlocking {
val answer = solver.scan()
}
}.also { println("[$i]Coroutine scan cost $it ns") })
}
}.average()
println("Coroutine Scan avg cost $time ns")
time = buildList {
for (i in 1..10) {
add(measureNanoTime {
runBlocking {
val answer = solver.scanSync()
}
}.also { println("[$i]Synchronous scan cost $it ns") })
}
}.average()
println("Synchronous Scan avg cost $time ns")
}
}
}
class Part2: Part1(width = 0, height = 0) {
infix fun override(newDiagram: Array<CharArray>) {
diagram = newDiagram.map { it.joinToString("") }.toTypedArray()
}
// 覆写无法存活时的逻辑
override fun cannotSurvive(coordinate: Coordinate): Boolean = _cannotSurvive(coordinate, {
nextDiagram[coordinate.row][coordinate.col] = symbolEmpty
})
// 缓存下一轮地图
private var nextDiagram: Array<CharArray> = arrayOf()
fun initDiagramCache() {
nextDiagram = diagram.map { line ->
// 使用toString生成Seq的字符串版本才能调用toCharArray方法
line.toString().toCharArray()
}.toTypedArray()
}
// 循环到计数器不再变化为止
fun cycleUntilTheEnd(): Int {
val counter = AtomicInteger(0)
var old = counter.get()
runBlocking{
while (true) {
initDiagramCache()
scan(counter) // scan本身是阻塞的
override(nextDiagram)
if (old == counter.get()) break
old = counter.get()
}
}
return counter.get()
}
companion object Runner {
fun main() {
val filename = "src/main/resources/puzzles/2025/day4-part1.txt"
val solver = Part2()
if (!(solver loadFromFile filename)) {
println("Failed to load puzzle from file $filename")
return
}
runBlocking {
val answer = solver.cycleUntilTheEnd()
println("Answer is $answer")
}
}
}
}T老师的思考
作为一名有Go语言基础的资深程序员,我理解你在Kotlin中追求不可变性的初衷,但需要提醒你几个关键点:
1. 不可变性 ≠ 过度类型转换
不可变性的核心是防止意外的状态修改,而不是通过复杂的类型转换链来实现
你在代码中多次转换类型(
CharArray→String→CharSequence),这反而增加了复杂度和性能开销真正的不可变性应该通过设计模式来实现,而不是通过类型系统的限制
2. 逻辑不可变 vs 物理不可变
你提到的"逻辑上不被修改"是正确的思路
在算法竞赛中,物理不可变往往带来不必要的性能损失
Go语言的设计哲学更注重实用性和性能,你可以借鉴这种思维方式
3. Kotlin的可变性是特性,不是缺陷
Kotlin的
var和val设计给了你选择的自由在性能敏感的场景(如AoC),合理使用可变变量是明智的
不要为了"纯粹"而牺牲代码的可读性和性能
4. 具体建议
简化数据结构:直接使用
List<String>或Array<CharArray>,避免不必要的转换信任自己:作为有经验的程序员,你应该相信自己在逻辑层面控制状态的能力
性能优先:在算法竞赛中,性能和正确性比"纯粹的不可变性"更重要
代码可读性:复杂的类型转换链会让代码难以维护,违背了Kotlin简洁的设计理念
5. Go vs Kotlin的思维差异
Go:实用主义,相信程序员的能力,提供简单的工具
Kotlin:提供强大的类型系统,但也要合理使用
你可以结合两者优点:用Go的实用思维来写Kotlin代码
6. 实际改进方向
// 当前:复杂的类型转换
this.diagram = raw.map { it.trim() }.toTypedArray()
// 建议:直接使用,相信自己的控制能力
this.diagram = raw // 如果raw已经是正确的格式
// 或者:一次性转换完成
this.diagram = file.readText().lines()
.filter { it.isNotEmpty() }
.toTypedArray()7. 最终建议
在算法竞赛中,不要过度纠结于"完美的不可变性"。你的Go语言经验已经让你具备了良好的状态管理能力,应该相信自己的判断。Kotlin的类型系统是工具,不是枷锁。合理使用可变性,让代码更简洁、更高效,这才是真正的专业水准。
记住:好的代码是解决问题的代码,不是符合某种教条的代码。
使用到的API和语法以及优化建议
代码中使用到的API
| 类别 | API/语法 | 用途 | 位置 |
|---|---|---|---|
| 协程 | runBlocking | 阻塞式启动协程 | Part1.Runner.timeTest, Part2.Runner.main, Part2.cycleUntilTheEnd |
coroutineScope | 创建协程作用域 | Map.scan | |
launch | 启动新协程 | Map.scan | |
withContext | 切换协程上下文 | Map.scan | |
Dispatchers.Default | 默认调度器 | Map.scan | |
| 原子操作 | AtomicInteger | 原子整数计数器 | Map.scan, Map.scanSync, Part2.cycleUntilTheEnd |
| 集合操作 | buildList | 构建列表 | Map.scanRow, Map.scanCol |
sumOf | 求和操作 | Map.scanRow, Map.scanCol | |
map | 映射操作 | Part1.loadFromFile, Part2.override, Part2.initDiagramCache | |
filter | 过滤操作 | Part1.loadFromFile | |
toTypedArray | 转换为数组 | Part1.loadFromFile, Part2.override, Part2.initDiagramCache | |
| 文件操作 | File | 文件操作 | Part1.loadFromFile |
readText | 读取文件内容 | Part1.loadFromFile | |
| 时间测量 | measureNanoTime | 测量执行时间 | Part1.Runner.timeTest |
| 其他 | enum class | 枚举类定义 | Direction, ScanMode |
infix fun | 中缀函数 | Map.peekUp, Map.peekDown等 | |
abstract class | 抽象类 | Map | |
override | 方法重写 | Part1.cannotSurvive, Part2.cannotSurvive |
代码问题分析
1. 类型转换混乱
问题:
- 冗余的类型转换:在
loadFromFile方法中,先将文件内容转换为TypedArray,然后又对每个元素进行trim并再次转换为TypedArray,存在冗余操作 - 不必要的中间转换:在
Part2.override方法中,将CharArray转换为String,然后再转换为CharSequence数组 - 复杂的类型转换链:在
Part2.initDiagramCache方法中,先将CharSequence转换为String,然后再转换为CharArray
影响:
- 增加内存占用:每次转换都会创建新的对象
- 降低性能:多次转换增加了计算开销
- 代码可读性差:复杂的转换链使代码难以理解
2. 协程调用隐患
问题:
- 阻塞式协程:在
timeTest和cycleUntilTheEnd方法中使用runBlocking阻塞主线程 - 线程安全但非协程最优:使用
AtomicInteger进行线程安全计数,虽然有效,但在协程环境中不是最高效的方式 - 协程粒度问题:为每一行创建一个协程,可能导致协程创建开销大于并行处理的收益
影响:
- 主线程阻塞:
runBlocking会阻塞调用线程,失去协程的非阻塞优势 - 潜在性能问题:协程创建过多可能导致调度开销增加
- 代码设计不清晰:混合使用阻塞和非阻塞代码
3. 其他潜在问题
- 设计问题:
_cannotSurvive方法接受一个doWhenTrue参数,在不同子类中使用方式不一致,增加了代码理解难度 - 错误处理:
loadFromFile方法在文件不存在时直接返回false,没有提供详细的错误信息 - 注释问题:代码中存在一些被注释掉的代码,影响代码整洁度
优化建议
1. 类型转换优化
建议:
- 减少冗余转换:在
loadFromFile方法中,直接一次转换完成 - 使用更直接的类型:考虑使用
List<String>而非Array<CharSequence>,减少转换次数 - 优化缓存初始化:在
initDiagramCache方法中,考虑直接使用CharSequence的get方法访问字符,避免转换
示例:
// 优化前
val raw = file.readText().lines().map { it.trim() }.filter { it.isNotEmpty() }.toTypedArray()
this.diagram = raw.map { it.trim() }.toTypedArray()
// 优化后
this.diagram = file.readText().lines()
.map { it.trim() }
.filter { it.isNotEmpty() }
.toTypedArray()
// 优化 initDiagramCache
nextDiagram = Array(height) { row ->
CharArray(width) { col ->
diagram[row][col]
}
}2. 协程优化
建议:
- 使用
async替代launch:对于需要返回结果的并行操作,使用async更合适 - 使用
CompletableDeferred:在协程环境中,使用CompletableDeferred替代AtomicInteger进行结果聚合 - 调整协程粒度:考虑按批次处理行,而不是为每一行创建一个协程
- 避免
runBlocking:在生产代码中,尽量避免使用runBlocking,特别是在循环中
示例:
// 优化后的 scan 方法
suspend fun scan(): Int {
return withContext(Dispatchers.Default) {
val deferreds = mutableListOf<Deferred<Int>>()
// 按批次处理
val batchSize = 10
for (batchStart in 0 until height step batchSize) {
val batchEnd = minOf(batchStart + batchSize, height)
deferreds.add(
async {
var sum = 0
for (row in batchStart until batchEnd) {
sum += scanRow(row)
}
sum
}
)
}
deferreds.sumOf { it.await() }
}
}3. 设计优化
建议:
- 简化方法签名:考虑将
_cannotSurvive方法拆分为两个方法,一个用于判断,一个用于处理副作用 - 改进错误处理:在
loadFromFile方法中,提供更详细的错误信息,或者使用异常处理 - 清理代码:移除被注释掉的代码,保持代码整洁
- 使用
data class:考虑将Map类的属性封装为数据类,提高代码可读性
示例:
// 优化后的 cannotSurvive 方法
fun cannotSurvive(coordinate: Coordinate): Boolean {
var token = aliveToken
for (direction in Direction.entries) {
if (isWhereNotEmpty(coordinate, direction)) token--
if (token <= 0) return false
}
return true
}
// 单独的副作用处理方法
fun markForRemoval(coordinate: Coordinate) {
nextDiagram[coordinate.row][coordinate.col] = symbolEmpty
}4. 性能优化
建议:
- 预分配内存:在
scanRow和scanCol方法中,预分配列表大小,减少内存分配 - 使用
IntArray:对于需要频繁访问的数组,使用原始类型数组提高性能 - 避免字符串操作:在
initDiagramCache方法中,直接操作字符而不是字符串 - 并行度控制:根据CPU核心数调整并行度,避免过度并行
示例:
// 优化后的 scanRow 方法
fun scanRow(row: Int): Int {
if (row >= height) return 0
var count = 0
for (col in 0 until width) {
if (diagram[row][col] == symbolStuff && cannotSurvive(Coordinate(row, col))) {
count++
}
}
return count
}5. 代码可读性优化
建议:
- 提取常量:将魔法数字(如
aliveToken = 4)提取为命名常量 - 添加文档:为关键方法添加KDoc文档注释
- 简化表达式:使用更简洁的表达式,如 Elvis 运算符
- 统一命名:保持命名风格一致,如使用驼峰命名法
示例:
// 提取常量
companion object {
private const val ALIVE_TOKEN = 4
private const val SYMBOL_EMPTY = '.'
private const val SYMBOL_STUFF = '@'
}
// 使用 Elvis 运算符
val width = value.maxOfOrNull { it.length } ?: 0总结
通过以上优化建议,可以:
- 提高代码性能:减少类型转换、优化协程使用、预分配内存
- 增强代码可读性:简化类型转换、清理代码、添加文档
- 提升代码质量:改进错误处理、优化设计、统一命名
- 充分发挥协程优势:避免阻塞、使用合适的协程API、调整协程粒度
这些优化不仅能解决当前代码中的问题,还能为未来的代码维护和扩展打下良好的基础。
Day 5
Part 1:区间合并+二分查找
题目描述
As the forklifts break through the wall, the Elves are delighted to discover that there was a cafeteria on the other side after all.
You can hear a commotion coming from the kitchen. "At this rate, we won't have any time left to put the wreaths up in the dining hall!" Resolute in your quest, you investigate.
"If only we hadn't switched to the new inventory management system right before Christmas!" another Elf exclaims. You ask what's going on.
The Elves in the kitchen explain the situation: because of their complicated new inventory management system, they can't figure out which of their ingredients are fresh and which are spoiled. When you ask how it works, they give you a copy of their database (your puzzle input).
The database operates on ingredient IDs. It consists of a list of fresh ingredient ID ranges, a blank line, and a list of available ingredient IDs. For example:
3-5
10-14
16-20
12-18
1
5
8
11
17
32The fresh ID ranges are inclusive: the range 3-5 means that ingredient IDs 3, 4, and 5 are all fresh. The ranges can also overlap; an ingredient ID is fresh if it is in any range.
The Elves are trying to determine which of the available ingredient IDs are fresh. In this example, this is done as follows:
- Ingredient ID
1is spoiled because it does not fall into any range. - Ingredient ID
5is fresh because it falls into range3-5. - Ingredient ID
8is spoiled. - Ingredient ID
11is fresh because it falls into range10-14. - Ingredient ID
17is fresh because it falls into range16-20as well as range12-18. - Ingredient ID
32is spoiled.
So, in this example, 3 of the available ingredient IDs are fresh.
Process the database file from the new inventory management system. How many of the available ingredient IDs are fresh?
解题代码
typealias sRange = Array<Long> // [start, end]
// 会发生索引溢出
// 如果是 num1 .. num2这种写法, num1或num2大于int.MAX_VALUE时会抛出index overflow
infix fun Number.inBetween(arr: sRange?) = arr?.let {
this.toLong() >= arr[0] && this.toLong() <= arr[1]
}?: false
infix fun Number.greaterThanBoth(arr: sRange) = this.toLong() > arr[1]
infix fun Number.lessThanBoth(arr: sRange) = this.toLong() < arr[0]
typealias sRangeList = MutableList<sRange>
fun sRangeList.sortByStart(): sRangeList {
this.sortBy { it[0] }
return this
}
fun sRangeList.sortByEnd(): sRangeList {
this.sortBy { it[1] }
return this
}
/*
超压缩情况时的代码
var maxStartIdx = 0 // 临时最大上界的索引
var maxEnd = this[maxStartIdx][1] // 临时最大上界
for (startIdx in 1 .. this.lastIndex) {
when {
maxEnd < this[startIdx][0] -> {
merged.add(this[maxStartIdx])
// maxStartIdx = startIdx
// maxEnd = this[maxStartIdx][1]
}
maxEnd >= this[startIdx][0] && maxEnd <= this[startIdx][1] -> {
// maxEnd = this[startIdx][1]
merged.add(arrayOf(this[maxStartIdx][0], this[startIdx][1]))
// maxStartIdx = startIdx
}
else -> continue
}
maxEnd = this[startIdx][1]
maxStartIdx = startIdx
}
* */
// 区间合并
fun sRangeList.merge(): sRangeList {
Log.i("开始合并区间列表,区间数量: ${this.size}")
Log.i("输入区间列表: ${this.map { it.contentToString() }}")
return when (this.size) {
0 -> {
Log.i("区间列表为空,返回空列表")
mutableListOf()
}
2 -> {
val result = mutableListOf(this[0].copyOf(), this[1].copyOf())
Log.i("区间列表有2个元素,直接返回拷贝: ${result.map { it.contentToString() }}")
result
}
else -> {
val merged = mutableListOf<sRange>()
Log.i("开始合并多个区间")
var current = this[0].copyOf()
Log.i("初始当前区间: ${current.contentToString()}")
for (startIdx in 1 .. this.lastIndex) {
val next = this[startIdx]
Log.i("处理第 $startIdx 个区间: ${next.contentToString()}")
when {
// 当前上界大于下一个区间的下界, 就更新临时最大上界
current[1] >= next[0] -> {
Log.i("当前区间 ${current.contentToString()} 与下一个区间 ${next.contentToString()} 有重叠,合并为 [${current[0]}, ${maxOf(current[1], next[1])}]")
current[1] = maxOf(current[1], next[1])
Log.i("更新后的当前区间: ${current.contentToString()}")
}
// 没有交集, 就将临时区间添加到结果集中
else -> {
Log.i("当前区间 ${current.contentToString()} 与下一个区间 ${next.contentToString()} 无重叠,将当前区间添加到结果集")
merged.add(current)
Log.i("结果集现在包含: ${merged.map { it.contentToString() }}")
current = next.copyOf()
Log.i("更新当前区间为: ${current.contentToString()}")
}
}
}
Log.i("循环结束,将当前区间 ${current.contentToString()} 添加到结果集")
merged.add(current)
Log.i("添加后的结果集: ${merged.map { it.contentToString() }}")
val sortedResult = merged.toMutableList().sortByStart()
Log.i("排序后的结果集: ${sortedResult.map { it.contentToString() }}")
sortedResult
}
}
}
fun sRangeList.mergeUntilNoChange(maxCycleTimes: Int = 1000): sRangeList {
val lastSize = this.size
var merged = mutableListOf<Array<Long>>()
var remainingCycleTimes = maxCycleTimes
do {
merged = merged.merge()
remainingCycleTimes--
}
while (merged.size != lastSize && remainingCycleTimes > 0)
return merged
}
// 二分查找不适用于区间重叠的情况, 所以必须先合并区间
infix fun Number.inRanges(ranges: sRangeList): Boolean {
Log.i("[inRanges] 开始检查值 $this 是否在区间列表中,区间数量: ${ranges.size}")
return when(ranges.size) {
0 -> {
Log.i("[inRanges] 区间列表为空,返回 false")
false
}
1 -> {
val result = this inBetween ranges[0]
Log.i("[inRanges] 只有一个区间 ${ranges[0].contentToString()},检查结果: $result")
result
}
2 -> {
val result = this inBetween ranges[0] || this inBetween ranges[1]
Log.i("[inRanges] 有两个区间 ${ranges[0].contentToString()} 和 ${ranges[1].contentToString()},检查结果: $result")
result
}
else -> {
val num = this.toLong()
// 二分查找最近的下界
Log.i("[inRanges] 使用二分查找检查,区间列表: ${ranges.map { it.contentToString() }}")
var low = 0
var high = ranges.lastIndex
var mid: Int // 进入循环后会更新值
var flag = false
var iteration = 0
Log.i("[inRanges] 初始 low: $low, high: $high")
while (!flag && low <= high) {
iteration++
mid = (low + high) / 2
Log.i("[inRanges] 迭代 $iteration: 计算 mid = floor(($low + $high) / 2) = $mid")
when {
mid < 0 || mid > ranges.lastIndex -> {
Log.i("[inRanges] mid $mid 超出边界 [0, ${ranges.lastIndex}],退出循环")
break
}
num > ranges[mid][1] -> {
Log.i("[inRanges] 值 $this 大于区间 ${ranges[mid].contentToString()} 的上界,设置 low = $mid + 1 = ${mid + 1}")
low = mid + 1
}
num < ranges[mid][0] -> {
Log.i("[inRanges] 值 $this 小于区间 ${ranges[mid].contentToString()} 的下界,设置 high = $mid - 1 = ${mid - 1}")
high = mid - 1
}
else -> {
val result = this inBetween ranges[mid]
Log.i("[inRanges] 值 $this 在区间 ${ranges[mid].contentToString()} 中,设置 flag = $result")
flag = result
}
}
Log.i("[inRanges] 迭代 $iteration 结束: low = $low, high = $high, flag = $flag")
}
Log.i("[inRanges] 二分查找结束,最终结果: $flag")
flag
}
}
}
class puzzle(
val ranges: MutableList<Array<Long>>? = null,
val ids: Array<Long>? = null
)
// 请确保在项目根目录下运行
class Solver(private val crawler: ICrawler): ICrawler by crawler {
var password: Long = 0
private val puzzle: String by lazy {
runBlocking {
crawler.getPuzzle(day = 5).also {
Log.i("已获取题目文件内容")
}
}
}
val parsedPuzzle by lazy {
Log.i("正在解析题目内容")
parseFromString().also {
Log.i("已解析题目内容")
}
}
fun parseFromString(input: String = puzzle): puzzle {
val lines = input.lines().map { it.trim() }
val rangesStr = lines.filter { it.contains("-") && it.isNotEmpty() }
val idsStr = lines.reversed().filter { !it.contains("-") && it.isNotEmpty() }
val ranges = rangesStr.map {
it.split("-").map { it -> it.toLongOrNull()?: 0L }.toTypedArray()
}.toMutableList().sortByStart().merge()
val ids = idsStr.map { it.toLongOrNull()?: 0L }.sorted().toTypedArray()
return puzzle(ranges = ranges, ids = ids)
}
fun solve(puzzle: puzzle = parsedPuzzle): Long {
val ids = parseFromString().ids
val ranges: MutableList<sRange> = puzzle.ranges?.toMutableList() ?: mutableListOf()
var passwd: Long = 0
Log.i ("共有${ids?.size?: 0}个数字等待验证")
ids?.forEach {
Log.i ("开始判断${it}是否位于区间中")
var num = it
measureTimeMillis {
if (it inRanges ranges) passwd++
}.also { Log.i ("判断${num}是否位于区间中耗时: $it ms") }
}
return passwd
}
companion object {
fun buildSolver(sess: String = "Just ensure this is not empty"): Solver {
val crawler = CrawlerV2(sess=sess)
return Solver(crawler)
}
// 解题用的函数
fun solveThePuzzle() {
val solver = buildSolver()
measureTimeMillis {
val password = solver.solve()
println ("The password is $password")
}.also { println("cost $it ms") }
}
}
}解题思路
| 计算思路 | 输出 | 备注 |
|---|---|---|
| 【区间合并】 1. 先对区间列表按下界大小进行升序排序 2. 遍历区间,若当前上界不大于下一个上界,则 立刻将当前区间添加到 merged列表中;若当前上界大于或等于下一个上界,则直接进入下一次循环 3. 由于只遍历到倒数第二个区间,所以结束循环后 需要手动把末尾区间添加到列表里 | 224/476 | 会有过度合并的情况,原因未知 |
| 【区间合并】 1. 先对区间列表按下界大小进行升序排序 2. 遍历区间,若当前上界不大于下一个上界,则 立刻将当前区间添加到 merged列表中;若当前上界大于或等于下一个上界,则更新当前上界 | 511 | 由Gemini指导修改 |
Part 2:区间合并
题目描述
The Elves start bringing their spoiled inventory to the trash chute at the back of the kitchen.
So that they can stop bugging you when they get new inventory, the Elves would like to know all of the IDs that the fresh ingredient ID ranges consider to be fresh. An ingredient ID is still considered fresh if it is in any range.
Now, the second section of the database (the available ingredient IDs) is irrelevant. Here are the fresh ingredient ID ranges from the above example:
3-5
10-14
16-20
12-18The ingredient IDs that these ranges consider to be fresh are 3, 4, 5, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, and 20. So, in this example, the fresh ingredient ID ranges consider a total of 14 ingredient IDs to be fresh.
Process the database file again. How many ingredient IDs are considered to be fresh according to the fresh ingredient ID ranges?
解题代码
class SolverPart2(private val crawler: ICrawler): ICrawler by crawler {
var password: Long = 0
private val puzzle: String by lazy {
runBlocking {
crawler.getPuzzle(day = 5).also {
Log.i("已获取题目文件内容")
}
} } val parsedPuzzle by lazy {
Log.i("正在解析题目内容")
parseFromString().also {
Log.i("已解析题目内容")
}
}
fun parseFromString(input: String = puzzle): puzzle {
val lines = input.lines().map { it.trim() }
val rangesStr = lines.filter { it.contains("-") && it.isNotEmpty() }
val idsStr = lines.reversed().filter { !it.contains("-") && it.isNotEmpty() }
val ranges = rangesStr.map {
it.split("-").map { it -> it.toLongOrNull()?: 0L }.toTypedArray()
}.toMutableList().sortByStart().merge()
val ids = idsStr.map { it.toLongOrNull()?: 0L }.sorted().toTypedArray()
// 总计1187行输入(不带空字符串)
// 187行原始区间, 合并后得到68行区间
// 1000行ID
return puzzle(ranges = ranges, ids = ids)
}
fun solve(puzzle: puzzle = parsedPuzzle): Long {
val ids = parsedPuzzle.ids
val ranges = puzzle.ranges?.toMutableList() ?: mutableListOf()
password = 0 // 先置零
for (arr in ranges) {
password += arr[1] - arr[0] + 1
}
return password
}
companion object {
fun buildSolver(sess: String = "Just ensure this is not empty"): SolverPart2 {
val crawler = CrawlerV2(sess=sess)
return SolverPart2(crawler)
}
// 解题用的函数
fun solveThePuzzle() {
val solver = buildSolver()
measureTimeMillis {
val password = solver.solve()
println ("The password is $password")
}.also { println("cost $it ms") }
}
}
}| 计算思路 | 输出 | 备注 |
|---|
| 计算思路 | 关键计算代码 |
|---|
思路总结草稿
/*
* 思路演进分析:
*
* 1. 问题理解:
* - AoC 2025 Day 5 题目是 "Cafeteria",主要考察排序、区间合并等知识点
* - Part 1:统计现有库存中有多少个 ID 是新鲜的(落在任何一个新鲜区间内)
* - Part 2:计算所有给定的新鲜区间的并集包含了多少个整数
*
* 2. 初始思路:
* - 直接遍历每个 ID,再遍历每个区间检查是否在其中(O(N×M) 复杂度)
* - 对于 Part 2,直接将所有区间内的数塞进一个 set 里去重,最后求 size
*
* 3. 优化思路:
* - 对区间进行排序,然后合并重叠的区间,减少后续操作的复杂度
* - 对合并后的区间使用二分查找,将 Part 1 的时间复杂度从 O(N×M) 降到 O(N log M)
* - 对于 Part 2,直接计算合并后每个区间的长度之和,避免使用 set 导致的内存问题
*
* 4. 代码演进:
* - 首先定义了 sRange(区间)和 sRangeList(区间列表)的类型别名
* - 实现了 sortByStart 和 sortByEnd 函数用于排序区间
* - 实现了 merge 函数用于合并重叠的区间
* - 实现了 inRanges 函数用于检查一个数字是否在任何一个区间内
* - 实现了 Solver 类用于解决 Part 1,SolverPart2 类用于解决 Part 2
*
* 5. 关键问题与解决方案:
* - 区间合并逻辑:初始版本可能存在错误,比如直接添加最后一个原始区间而不是当前合并后的区间
* - 二分查找逻辑:初始版本可能存在死循环问题,比如缺少 low <= high 的条件
* - 日志添加:为了调试和理解代码执行流程,添加了详细的日志输出
*
* 6. 成功原因:
* - 正确实现了区间合并算法,确保了区间的无重叠性
* - 正确实现了二分查找算法,确保了查找的高效性
* - 合理使用了 Kotlin 的语言特性,如扩展函数、类型别名等
* - 代码结构清晰,逻辑明确,易于理解和维护
*/使用到的API和语法以及优化建议
失败代码分析与优化
失败代码问题:
区间合并逻辑错误:
merge()函数中,当区间数量为 2 时,直接返回两个区间的拷贝,没有检查是否需要合并mergeUntilNoChange()函数存在逻辑错误,初始化merged为空列表后调用merged.merge(),始终返回空列表- 超压缩代码逻辑问题:
- 注释掉了关键的状态更新代码(
maxStartIdx和maxEnd的更新) - 每次遇到重叠区间都直接添加到结果集,而不是累积合并
- 循环结束后没有添加最后一个合并区间
- 没有处理区间完全包含的情况
- 注释掉了关键的状态更新代码(
性能问题:
- 初始实现直接遍历每个 ID 和每个区间,时间复杂度 O(N×M),数据量大时慢到爆炸
- Part 2 用 Set 存所有新鲜 ID,大区间直接内存溢出,根本跑不动
优化原因:
- 区间合并:通过合并重叠区间,减少后续操作的区间数量
- 二分查找:将 Part 1 的时间复杂度从 O(N×M) 降到 O(N log M)
- 直接计算:Part 2 直接计算合并后区间的长度之和,避免内存问题
算法优化建议
区间合并算法优化:
正确的区间合并步骤:
- 排序:首先按区间起始值排序
- 初始化:创建结果列表,设置当前合并区间为第一个区间
- 遍历:
- 如果当前区间与下一个区间重叠,更新当前合并区间的结束值
- 如果不重叠,将当前合并区间添加到结果集,设置下一个区间为新的当前区间
- 收尾:将最后一个合并区间添加到结果集
优化后的合并函数:
fun sRangeList.merge(): sRangeList { if (size <= 1) return this.toMutableList() // 1. 按起始值排序 val sorted = this.sortedBy { it[0] }.toMutableList() // 2. 初始化 val merged = mutableListOf<sRange>() var current = sorted[0].copyOf() // 3. 遍历 for (i in 1 until sorted.size) { val next = sorted[i] if (current[1] >= next[0]) { // 有重叠,合并区间 current[1] = maxOf(current[1], next[1]) } else { // 无重叠,添加当前区间并更新 merged.add(current) current = next.copyOf() } } // 4. 收尾 merged.add(current) return merged }性能优化建议:
- 提前排序:确保区间按起始值排序,这是合并算法的前提
- 单次遍历:使用单次遍历完成合并,避免多次循环
- 内存优化:直接在原列表基础上操作,减少内存开销
- 边界处理:正确处理空列表、单元素列表等边界情况
二分查找优化:
- 确保合并后的区间列表已排序
- 使用标准二分查找算法,避免死循环
- 利用短路求值,找到匹配区间后立即返回
时间复杂度分析:
- 合并操作:O(n log n)(主要来自排序)
- 查找操作:O(log n) 每查询(使用二分查找)
- 整体复杂度:Part 1 为 O(m log n),其中 m 是 ID 数量,n 是区间数量
代码 API 与技巧
核心 API 与技巧:
类型别名(Type Alias):
typealias sRange = Array<Long>:简化区间表示typealias sRangeList = MutableList<sRange>:简化区间列表表示
扩展函数(Extension Functions):
fun sRangeList.sortByStart():按区间起始值排序fun sRangeList.sortByEnd():按区间结束值排序fun sRangeList.merge():合并重叠区间
中缀函数(Infix Functions):
infix fun Number.inBetween(arr: sRange?):检查值是否在区间内infix fun Number.greaterThanBoth(arr: sRange):检查值是否大于区间上限infix fun Number.lessThanBoth(arr: sRange):检查值是否小于区间下限infix fun Number.inRanges(ranges: sRangeList):检查值是否在任何区间内
属性委托(Property Delegation):
private val puzzle: String by lazy:延迟加载题目内容val parsedPuzzle by lazy:延迟解析题目内容
类委托(Class Delegation):
class Solver(private val crawler: ICrawler): ICrawler by crawler:委托实现 ICrawler 接口
协程(Coroutines):
runBlocking { ... }:在同步环境中运行协程
高阶函数(Higher-Order Functions):
lines.map { it.trim() }:处理输入行rangesStr.filter { it.contains("-") && it.isNotEmpty() }:过滤区间行ids?.forEach { ... }:遍历 ID 列表
伴生对象(Companion Object):
companion object { ... }:提供静态方法和工厂方法
性能优化:
- 短路求值:二分查找一旦找到匹配区间立即返回
- 内联函数:可能的内联优化(代码中未明确标注)
- 时间测量:
measureTimeMillis { ... }:测量执行时间
日志系统:
Log.i(...):详细的日志输出,便于调试和理解执行流程
这些 API 和技巧的组合使用,使得代码既高效又易于理解和维护。