从零开始的RPC(十):容错处理与负载均衡
理论部分
服务熔断
熔断的概念最先来自于电路工程中,在我们的家庭电路中,在电表和电路的火线上会接有一根保险丝为电路安全护航。保险丝一般由熔点较低的金属制成,当电路上的电流过大时,它就会因为过热被熔断,从而达到保护电表和电路的作用。
在微服务架构中,服务之间的调用一般分为服务调用方和服务提供方。当下游服务因为过载或者故障不能用时,我们需要及时在上游的服务调用方暂时“熔断”调用方和提供方之间的调用链,避免服务雪崩现象的出现,从而保证服务调用方与系统整体的稳定性和可用性。
分布式系统中的服务雪崩
在分布式系统中,由于业务上的划分,一次完整的请求可能需要不同服务协作完成,在微服务架构中就是多个服务实例协作完成。请求会在这些服务实例中传递,服务之间的调用会产生新的请求,它们共同组成一条服务调用链,关系如下方时序图所示。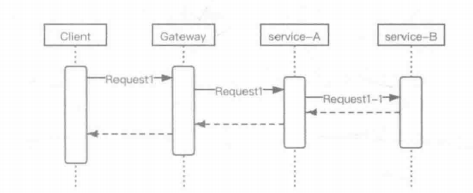
客户端发起了一次请求Request1,网关在接受到请求后将它转发给service-A,由于这次请求涉及到了service-B中的数据,所以service-A又向service-B发起了一次请求Request1-1来获取对应的数据,在处理结束后将结果返回给网关,由网关将结果返回给客户端。上图10-1中Request1和Request1-1共同组成了这次调用的调用链。
服务雪崩是指当调用链的某个环节(特别是服务提供方的服务)不可用时,导致了上游环节不可用,并最终将这种影响像雪崩一样扩大到整个系统中,导致了整个系统不可用的情况
服务雪崩的发生流程如下图所示: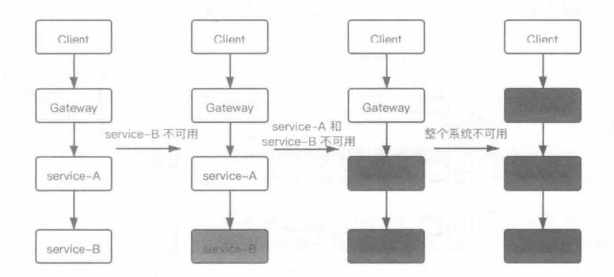
服务雪崩一般有3个阶段:
- 第一阶段是服务提供者不能调用
在初始阶段,一切运行良好,网关、service-A和service-B响应着客户端的各种请求。在某一个时间节点,服务提供者service-B由于网络故障或者请求过载而不可用,无法及时响应各类请求 - 第二阶段是服务调用者不可用
在服务提供者不可用之后,客户端可能会因为错误提示或者长时间的阻塞而不断发送相同的请求到网关中,网关再次将请求转发给service-A进行处理,service-A根据业务流程也会向service-B发起数据请求:同时上一阶段中service-A对service-B超时或者失败的请求可能会因为service-A中重试机制再次请求service-B。这些请求都无法从service-B中获取到有效的返回,最坏的结果是都被阻塞,无法及时响应。service-A也会因为发起了过多对service-B的请求而产生的等待线程耗尽了线程池中的资源,无法及时响应其他请求,导致了自身的不可用 - 最后阶段是整个系统的不可用
service-A中等待请求同样阻塞了转发请求的网关。网关也因为大量等待请求将会产生大量的阻塞线程,使得网关没有足够的资源处理其他请求,导致了整个系统无法对外提供服务
服务熔断保障系统可用性
为了避免服务雪崩现象的出现,我们需要及时“壮士断腕”,在必要的时候暂时切断对异常服务提供者的调用,保证部分服务的可用以及整体系统的稳定性。服务熔断机制如下图所示: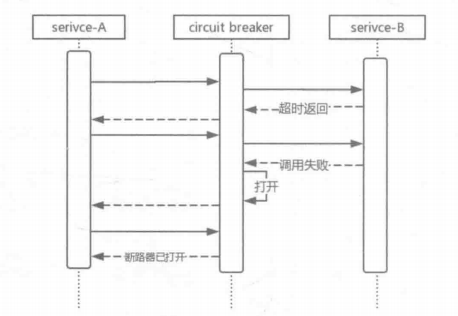
如上图所示,我们在service-A向service-B的请求中增加了一根“保险丝”,即断路器。它会统计一段时间内service-A对service-B请求响应结果,在超时或者失败次数过多的情况下,阻断service-A对service-B的请求,直接返回相关的异常处理结果,使得service-A中的请求线程能够及时返回,避免资源耗尽而不可用,从而保护了服务调用者,避免了服务级联失败
断路器
断路器能够很好地保护服务调用方的稳定性,它能够避免服务调用者频繁执行可能失败的服务提供者,防正服务调用者浪费CPU使用周期和线程资源
断路器设计模式借鉴了电路中的保险丝设计方案。断路器代理了服务调用方对提供方的请求,它监控了最近请求的失败和超时次数。在下游服务因为过载或者敌障无法提供正常响应时,断路器中的请求失败率就会大大提升,在超过一定阀值之后,断路器会打开,切断服务调用者和服务提供者之间的联系,此时服务调用者会执行失败逻辑或者返回异常,避免无效的线程等待。同时断路器中还提供检测恢复机制,允许服务调用者尝试调用服务提供者以检测其是否恢复正常,若正常则关闭断路器,恢复正常调用。
断路器中存在三种状态,分别是关闭、打开、半开,它们之间的状态转化如下图所示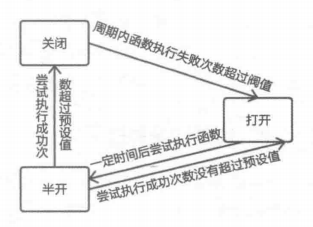
- 关闭状态
如果程序正常运行,那么断路器大多数时候都处于这个状态,此时服务调用者正常调用服务提供者。断路器会统计周期时间内的请求总次数和失败次数的比例 - 打开状态
如果最近失败频率超过预设的阀值之后,断路器就会进入打开的状态。服务调用者对服务提供者的调用将会立即失败,转而执行预设的失败逻辑或者返回异常 - 半开状态
断路器进入打开状态之后将启动一个超时定时器,在定时器到达时,它会进入到半开状态。此时断路器允许服务调用者尝试对服务提供者发起少量实际调用请求(检测恢复机制)。如果这些请求都成功执行,那么断路器就认为服务提供者已经恢复正常,进入关闭状态,失败计数器也同时复位。如果这些请求失败,断路器将返回到打开状态,并重新启动超时定数器,重复进行检测恢复。
关闭状态使用的失败计数器基于时间窗口计数,它会定期自动复位。只有在窗口时间内发生的请求总次数和请求失败次数达到一定的阀值,断路器才会被打开。半打开状态使用成功计数器记录调用操作的成功尝试次数,在指定数量的连续操作调用成功后,断路器恢复到关闭状态。如果任何调用失败,断路器会立即进入断开状态,成功计数器将在下次进入半开状态时重新清零。半开状态仅允许有限的请求发生真正的调用,这有助于防止刚恢复的服务提供者突然被请求淹没而再次岩机
负载均衡
负载均衡能够将大量的请求,根据负载均衡算法,分发到多台服务器上进行处理,使得所有服务器负载都维持在高效稳定的状态,以提高系统的吞吐量,保证可用性
负载均衡类型
负载均衡分为软件负载均衡和硬件负载均衡。软件负载均衡一般使用独立的负载均衡软件来实现请求的分发,它配置简单,使用成本低,能够满足基本的负载均衡要求,但是负载均衡软件的质量和所部署服务器的性能就有可能成为系统吞吐量的瓶颈:硬件负载均衡依赖于特殊的负载均衡设备,部署成本高,但相对于软件负载均衡,能够满足更多样化的需求
基于DNS负载均衡和反向代理负载均衡是我们常见的软件负载均衡。在DNS服务器中,会为同一个名称配置多个不同的IP地址,不同的DNS请求会解析到不同的IP地址,从而达到不同请求访问不同服务器的自的:而反向代理负载均衡使用代理服务器,将请求按照一定的规则分发到下游的服务器集群进行处理,最常见的方式即服务网关
负载均衡算法
负载均衡算法定义了如何将请求分散到服务实例的规则,优秀的负载均衡算法能够有效提高系统的吞吐量,使服务集群中各服务的负载处于高效稳定的状态。常见的负载均衡算法有以下几种
- 随机法
随机从服务集群中选取一台服务分配请求。随机法实现简单明了,保证了请求的分散性,但是无法顾及请求分配是否合理和服务器的负载能力。 - 轮询法或加权轮询法
将请求轮流分配给现有服务集群中的每一台服务,适用于服务集群中各服务负载能力相当且请求处理差异不大的情况下。加权轮询会根据各服务的权重,额外分配更多的请求,例如服务 A 权重 1,服务器 B 权重 2,服务器 C 权重 3,则分配的过程为A-B-B-C-C-C-A-B-B-C-C-C..... - Hash法或一致Hash法
使用Hash算法将请求分散到各个服务中。一致性Hash 则基于虚拟节点,在某一个服务节点宕机后将请求平摊到其他服务节点,避免请求的剧烈变动 - 最小连接数法
将请求分配到当前服务集群中处理请求最少的服务中。该算法需要负载均衡服务器和服务之间存在信息交互,负载均衡服务器需要了解集群中各个服务的负载情况。
实践部分
【时代的眼泪】Hystrix
略
Kratos 负载均衡组件
详情请见
Kratos支持如下负载均衡实现:
- WRR (Weighted Round Robin) - 加权轮询
- 原理 :按权重比例轮流分配请求到各个后端节点
- 特点 :权重高的节点获得更多请求,分配相对均匀
- 适用场景 :后端节点性能差异较大时,通过权重平衡负载
- Kratos默认 :Kratos Client 内置的默认负载均衡算法
- P2C (Power of Two Choices) - 二选一
- 原理 :随机选取两个节点,选择当前负载较轻(或延迟较低)的那个
- 特点 :避免全局状态同步,实现简单且效果接近最优
- 适用场景 :节点数量多、需要快速决策的大规模分布式系统
- 优势 :比纯随机更均衡,比轮询更适应动态变化
- Random - 随机
- 原理 :完全随机选择一个后端节点
- 特点 :实现最简单,无状态,分布均匀性依赖大数定律
- 适用场景 :节点性能相近、请求成本相似的场景
- 缺点 :可能出现短期不均衡,不适合节点差异大的情况
试用一下
// 注册负载均衡组件
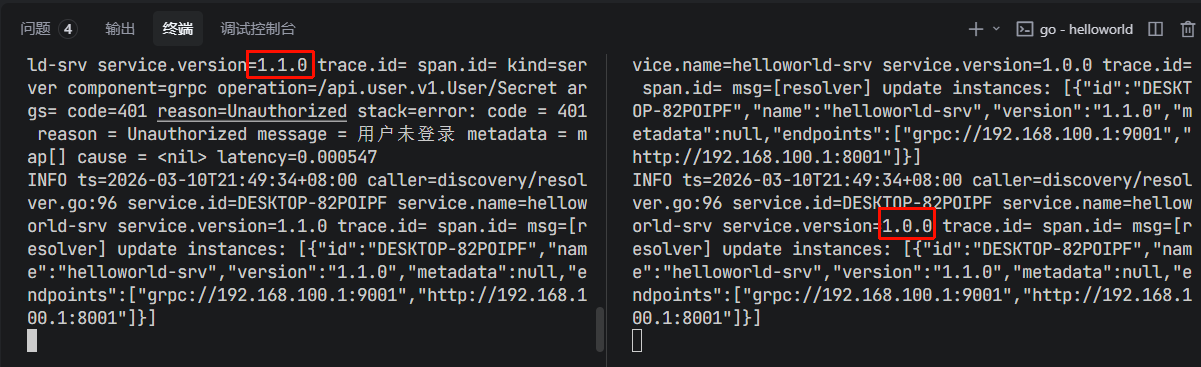
nodeFilter := filter.Version("1.1.0") // 筛选版本号为1.1.0的服务实例
selector.SetGlobalSelector(p2c.NewBuilder()) // 由于 gRPC 框架的限制,只能使用全局 balancer name 的方式来注入 selector
conn, err := grpc.DialInsecure(
ctx,
grpc.WithEndpoint("discovery:///helloworld-srv"),
grpc.WithDiscovery(discoveryCenter),
grpc.WithNodeFilter(nodeFilter),
)
if err != nil {
panic(err)
}
defer conn.Close()- 如果目标服务版本不存在,Kratos的gRPC客户端会得到
503响应(Kratos的error handling是这样的,把httpz状态码当作通用状态码来使用)
这里是因为服务端没有注册JWT中间件,导致请求被拦截了
# 运行(本人)客户端demo
# <src>\cmd\<main>
go run .
-conf ../../configs\worker-1\config.yaml -v 1.1.0