从零开始的RPC(十二):分布式链路追踪
诊断式分布系统的问题
分布式系统变得日趋复杂,越来越多的系统开始走向分布式化,如微服务、分布式数据库、分布式缓存等,使得后台服务构成了一种复杂的分布式网络。
为什么需要分布式链路追踪
微服务极大地改变了软件的开发和交付模式,单体应用被拆分为多个微服务,单个服务的复杂度大幅降低,库之间的依赖也转变为服务之间的依赖。由此带来的问题是部署的粒度变得越来越细,众多的微服务给运维带来巨大压力,即使有了Docker容器和服务编排组件Kubernetes,这依然是个严肃的问题。
随着服务数量的增多和内部调用链的复杂化,开发者仅凭借日志和性能监控,难以做到全局的监控,在进行问题排查或者性能分析时,无异于盲人摸象。分布式追踪能够帮助开发者直观分析请求链路,快速定位性能瓶颈,逐渐优化服务间的依赖,也有助于开发者从更宏观的角度更好地理解整个分布式系统。
什么是分布式链路追踪
在微服务架构下,原单体服务被拆分为多个微服务独立部署,客户端就无法知晓服务的具体位置。系统由大量服务组成,这些服务可能由不同的团队开发,可能使用不同的编程语言来实现,也有可能布置在了几千台服务器,横跨多个不同的数据中心。在这种环境中,当出现错误异常或性能瓶颈时,获取请求的依赖拓扑和调用详情对于解决问题是非常有效的
分布式链路追踪就是将一次分布式请求还原成调用链路,将一次分布式请求的调用情况集中展示,比如各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。
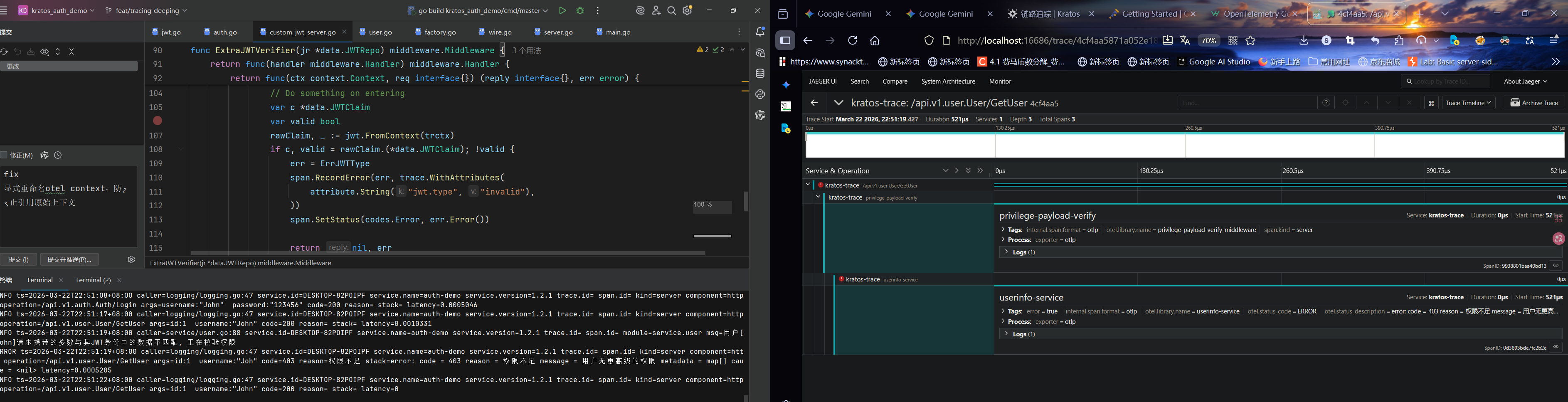
通常使用Tracing表示链路追踪。这里还要提到与之相近的还有两个概念:Logging 和 Metrics:
- Tracing:记录单个请求的处理流程,其中包括服务调用和处理时长等信息
- Logging:用于记录离散的日志事件,包含程序执行到某一点或某一阶段的详细信息
- Metrics:可聚合的数据,通常是固定类型的时序数据,包括Counter、Gauge、Histogram 等
同时这三种定义相交的情况(或者说混合出现)也比较常见:
- Tracing与Metrics:可聚合的事件。例如分析某对象存储的Nginx日志,统计某段时间内GET、PUT、DELETE、OPTIONS操作的总数
- Metrics与Tracing:单个请求中的可计量数据。例如SQL执行总时长、gRPC调用总次数等
- Tracing与Logging:请求阶段的标签数据。例如在Tracing的信息中标记详细的错误原因
针对每种分析需求,我们都有非常强大的集中式分析工具:
- Logging:ELK(Elasticsearch、Logstash、Kibana),elastic公司提供的一套完整的日志收集以及展示的解决方案
- Metrics:Prometheus,专业的 metric统计系统,存储的是时序数据,即按相同时序(相同名称和标签),以时间维度存储连续的数据的集合。随着时间推移,也许会进化为追踪系统,进而进行请求内的指标统计,但不太可能深入到日志处理领域。
- Tracing:Jaeger,是Uber开源的一个兼容OpenTracing标准的分布式追踪服务
分布式链路追踪规范:OpenTracing
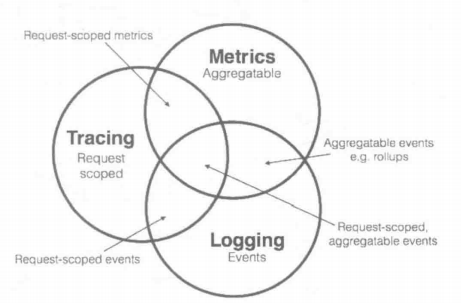
Tracing是在上世纪90年代就已出现的技术,但真正让该领域流行起来的还是源于Google的一篇Dapper论文。分布式追踪系统发展很快,种类繁多,但无论哪种组件,其核心步骤一般有3步:代码埋点、数据存储和查询展示
目前流行的链路追踪组件有Jaeger、Zipkin、Skywalking和 Pinpoint 等。在数据采集过程中,对用户代码的入侵和不同系统API的兼容性,导致切换链路追踪系统需要巨大的成本
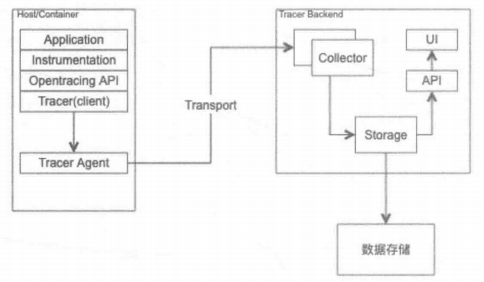
为了解决不同的分布式追踪系统API不兼容的问题,诞生了OpenTracing规范。OpenTracing是一个轻量级的标准化层,它位于应用程序/类库和追踪或日志分析程序之间。OpenTracing提供了6种语言的中立工具:Go、JavaScript、Java、Python、Objective-C和C++。OpenTracing 的架构支持Zipkin、LightStep 和Appdash 等追踪组件,并且可以轻松集成到开源的框架中,例如 gRPC、Flask、Django 和 Go-kit等
OpenTracing是一个Library库,定义了一套通用的数据上报接口,要求各个分布式追踪系统都来实现这套接口。这样一来,应用程序只需要对接OpenTracing,而无需关心后端采用的到底是什么分布式追踪系统,因此开发者可以无缝切换分布式追踪系统,也使得在通用代码库增加对分布式追踪的支持成为可能
OpenTracing于2016年10月加入CNCF基金会,是继Kubernetes和Prometheus之后,第三个加入CNCF的开源项目。它是一个中立的(厂商无关、平台无关)分布式追踪的API规范,提供统一接口,可方便开发者在自己的服务中集成一种或多种分布式追踪的实现
分布式链路追踪规范:OpenTelemetry(最新标准)
重要更新(2024-2025)
OpenTelemetry(OTel)已成为分布式链路追踪领域的事实标准,由 OpenTracing 和 OpenCensus 项目合并而成,并于2023年从CNCF毕业。根据2023年CNCF调研显示,OpenTelemetry的采用率已达78%。
什么是 OpenTelemetry
OpenTelemetry 是一个开源的可观测性框架,由一系列工具、API和SDK组成,允许开发团队以单一、统一的格式生成、处理和传输遥测数据(telemetry data)。它由云原生计算基金会(CNCF)开发,旨在提供标准化协议和工具,用于收集和路由指标、日志和跟踪数据。
OpenTelemetry 的核心优势
- 统一标准:整合了可观测性三大支柱(Tracing、Metrics、Logging),提供统一的API和SDK
- 厂商无关:不绑定任何特定的后端,支持多种存储和分析系统
- 跨语言支持:提供多种编程语言的SDK,包括Go、Java、Python、JavaScript、C++等
- 社区活跃:作为CNCF毕业项目,拥有庞大的社区支持和持续的维护
- 向后兼容:兼容OpenTracing和OpenCensus,平滑迁移
OpenTelemetry 架构
OpenTelemetry 的架构主要分为三个部分:
- API:定义了生成遥测数据的接口,不包含具体实现
- SDK:提供了API的具体实现,包括数据采集、处理、批处理和导出等功能
- Collector:一个可扩展的中间件,用于接收、处理和导出遥测数据
OpenTelemetry 与其他组件的关系
关系说明
OpenTelemetry 就像是"标准建材供应商",而 Jaeger、SkyWalking 等就像是"建筑公司"。OpenTelemetry 提供标准化的数据格式和采集方式,而 Jaeger、SkyWalking 等后端负责存储、分析和展示数据。
- OpenTelemetry → Jaeger:OpenTelemetry 可以将追踪数据导出到 Jaeger
- OpenTelemetry → SkyWalking:SkyWalking 9.0+ 版本原生支持 OpenTelemetry 协议
- OpenTelemetry → Zipkin:通过 OpenTelemetry Collector 的 Zipkin 导出器
- OpenTelemetry → Prometheus:通过 OpenTelemetry Collector 的 Prometheus 导出器
对比:Jaeger 直连 vs OpenTelemetry 间接上传
| 模式 | Jaeger 直连 | OpenTelemetry 间接上传 |
|---|---|---|
| 优势 | - 配置简单 - 直接集成 - 低延迟 | - 统一标准 - 支持多种后端 - 数据预处理能力 - 可扩展性强 |
| 劣势 | - 绑定 Jaeger - 缺乏数据处理能力 - 扩展性有限 | - 增加系统复杂度 - 可能增加延迟 - 部署和维护成本 |
| 适用场景 | - 小型项目 - 快速原型 - 单一后端 | - 大型分布式系统 - 多语言环境 - 需要多种可观测性数据 |
Jaeger 直连:适合简单场景,直接使用 Jaeger SDK 发送数据到 Jaeger 后端。
OpenTelemetry 间接上传:适合复杂场景,通过 OpenTelemetry Collector 处理和路由数据,可以同时支持多种后端。
OpenTelemetry 在 Go 中的使用示例
import (
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/exporters/jaeger"
"go.opentelemetry.io/otel/sdk/resource"
sdktrace "go.opentelemetry.io/otel/sdk/trace"
semconv "go.opentelemetry.io/otel/semconv/v1.4.0"
)
func initTracer() (*sdktrace.TracerProvider, error) {
// 创建 Jaeger exporter
exp, err := jaeger.New(jaeger.WithCollectorEndpoint(jaeger.WithEndpoint("http://localhost:14268/api/traces")))
if err != nil {
return nil, err
}
// 创建 TracerProvider
tp := sdktrace.NewTracerProvider(
sdktrace.WithBatcher(exp),
sdktrace.WithResource(resource.NewWithAttributes(
semconv.SchemaURL,
semconv.ServiceNameKey.String("my-service"),
)),
)
// 设置全局 TracerProvider
otel.SetTracerProvider(tp)
return tp, nil
}新兴的可观测性平台:SigNoz
新兴平台
SigNoz 是一个基于 OpenTelemetry 构建的开源可观测性平台,提供了完整的解决方案,包括 Tracing、Metrics 和 Logs 的统一视图。
SigNoz 的特点:
- 完全基于 OpenTelemetry 构建
- 开源且自托管
- 统一的 Tracing、Metrics 和 Logs 视图
- 内置告警功能
- 支持多种存储后端(ClickHouse、PostgreSQL等)
分布式链路追踪的基础概念
在前文所提及的几种组件中,Zipkin组件是严格按照GoogleDapper论文实现的,下面基于Zipkin介绍其中涉及的基本概念
Span 基本工作单元
一次链路调用(可以是RPC、DB 调用等,没有特定的限制)创建一个Span。通过一个64位ID标识Span,通常使用UUID,Span中还有其他的数据,例如描述信息、时间戳、键值对的(Annotation)tag 信息、parentID等,其中parentID 用来表示Span调用链路的来源。
Trace 类似于树结构的 Span 集合
表示一条完整的调用链路,存在唯一标识。一个Trace代表了一个事务或者流程在(分布式)系统中的执行过程。Trace是由多个Span组成的一个有向无环图,每一个Span代表Trace中被命名并计时的连续性的执行片段。
Annotation 注解
用来记录请求特定事件相关信息(例如时间),通常包含4个注解信息,如下:
- CS (Client Sent):表示客户端发起请求
- SR (Server Receive):表示服务端收到请求
- SS (Server Send):表示服务端完成处理,并将结果发送给客户端
- CR (Client Receive):表示客户端获取到服务端返回信息
链路信息的还原依赖于两种数据,一种是各个节点产生的事件,如CS、SS,称之为带外数据,这些数据可以由节点独立生成,并且需要集中上报到存储端;另一种数据是TraceID、SpanID、ParentID,用来标识Trace、Span 以及 Span 在一个Trace 中的位置。这些数据需要从链路的起点一直传递到终点,称之为带内数据
通过带内数据的传递,可以将一个链路的所有过程串起来;通过带外数据,可以在存储端分析更多链路的细节。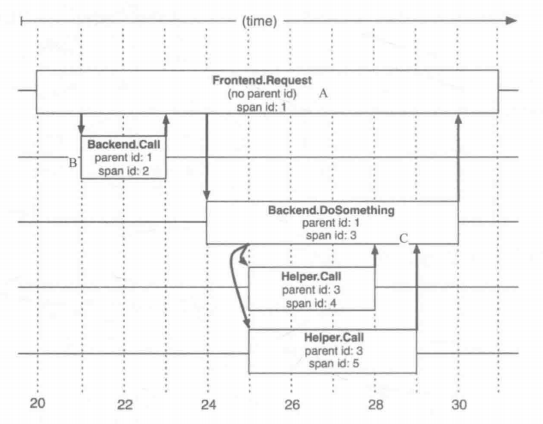
Trace树的运行机制
在上图中:对于每个Trace树,Trace都要定义一个全局唯一的TraceID,在这个跟踪中的所有Span都将获取到这个TraceID。每个Span都有一个ParentID和它自己的SpanID。上图中Frontend Request调用的 ParentID为空,SpanID为1;然后Backend Call的 ParentID为 1,SpanID为2;Backend DoSomething调用的ParentID也为1,SpanID为3,其内部还有两个调用,Helper Call的ParentID为3,SpanID为4,以此类推
追踪系统中用Span来表示一个服务调用的开始和结束时间,也就是时间区间。追踪系统记录了Span的名称以及每个SpanID的 ParentID,如果一个Span没有ParentID则被称为RootSpan,当前节点的ParentID即为调用链路上游的SpanID,所有的Span都挂在一个特定的追踪上,共用一个TraceID
几种流行的分布式链路追踪组件 (截止成书时间的2020年)
在大家熟悉了分布式链路追踪中的一些基础概念之后,我们来具体了解一下这几种流行的分布式链路追踪组件
简单易上手的Twitter Zipkin
Zipkin是一款分布式链路追踪组件,由Twitter开源,同样也兼容OpenTracingAPI;它基于GoogleDapper的论文设计,国内外很多公司都在用,文档资料也很丰富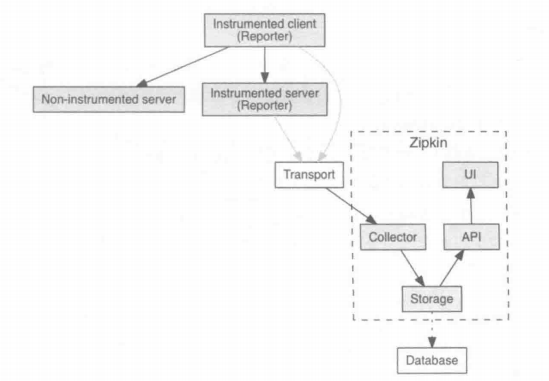
Zipkin架构图
从Zipkin的架构图可知,Zipkin包含如下4个部分:
- Collector:存储和索引报上来的链路数据,以供后续查找
- Storage:Zipkin的存储是可插拔的,最初是为了在Cassandra上存储数据而构建。除了Cassandra,Zipkin 还原生支持ElasticSearch和 MySQL。
- Zipkin Query Service (API):一旦数据被存储和索引,我们就需要一种方法来查看它。Zipkin搜索提供了一个简单的JSON API,用于查找和检索Trace记录。此API的主要使用者是Web UI
- Web UI:Web UI:Zipkin 查询链路追踪的界面。Web UI提供了一种基于服务、时间和注解查看Trace记录的方法
Zipkin分布式链路监控的优势是语言无关性,整体实现较为简单。Zipkin支持Java、PHP、Go 和NodeJS 等语言客户端。社区支持的插件较为丰富,包括RabbitMQ、Mysql和HTTPClient等。Zipkin UI界面功能较为简单,本身无告警功能,可能需要二次开发。
云原生链路监控组件Uber Jaeger
Jaeger是CNCF 云原生项目之一,Jaeger受 Dapper 和 Open Zipkin的启发,由Uber开源的分布式追踪系统,兼容Open Tracing API。它用于微服务的监控和排查,支持分布式上下文传播、分布式事务的监控、报错分析、服务的调用网络分析以及性能/延迟优化。Jaeger的服务端使用Go语言实现,其存储支持Cassandra、Elasticsearch和内存,并提供了Go、Java、Node、Python 和C++等语言的客户端库。Jaeger具有如下的特性:
- 高扩展性
Jaeger后端的分布式设计,可以根据业务需求进行扩展。例如,Uber任意一个Jaeger每天通常要处理数十亿个跨度 - 原生支持 OpenTracing
Jaeger后端、Web UI和工具库的设计支持OpenTracing标准。- 通过跨度引用将轨迹表示为有向无环图(不仅是树);
- 支持强类型的跨度标签和结构化日志;
- 通过行李支持通用的分布式上下文传播机制。
- 支持多个存储后端
Jaeger支持两种流行的开源NoSQL 数据库作为跟踪存储后端:Cassandra 3.4+和Elasticsearch 5.x / 6.x。 - 现代化Web UI
JaegerWebUI是使用流行的开源框架实现的。v1.0中发布了几项性能改进,以允许UI有效处理大量数据,并能够显示上万跨度的链路跟踪。 - 支持云原生部署
Jaeger后端支持Docker镜像部署。二进制文件支持各种配置方法,包括命令行选项,环境变量和多种格式(yaml、toml等)的配置文件。可以方便地部署到Kubernetes集群。 - 可观察性
默认情况下,所有Jaeger后端组件均开放Prometheus监控(也支持其他指标后端)。使用结构化日志库zap将日志标准输出。 - 与Zipkin向后兼容
已经使用Zipkin库,如果我们要切换到Jaeger,客户端也不必重写所有代码。Jaeger通过在HTTP上接受Zipkin格式(Thrift或JSON v1/v2)的跨度来提供与Zipkin的向后兼容性。从Zipkin后端切换到Jaeger后端变得很简单。
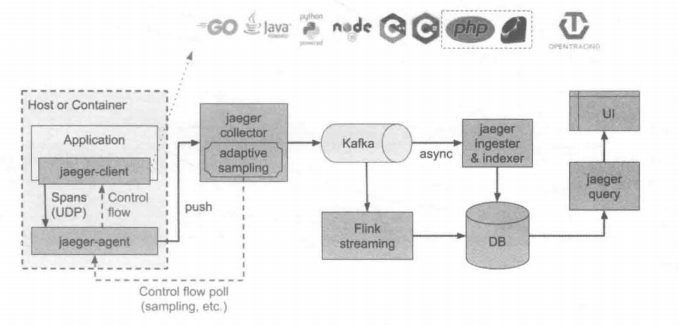
Jaeger架构
Jaeger主要由以下几部分组成:
- Jaeger Client
为不同语言实现了符合OpenTracing标准的 SDK。应用程序通过API写入数据,client library把trace记录按照应用程序指定的采样策略传递给jaeger-agent。 - Jaeger-Agent
它是一个监听在UDP端口上用以接收span数据的网络守护进程,它会将数据批量发送给collector。它被设计成一个基础组件,部署到所有的宿主机上。jaeger-agent将client library和collector解耦,为client library屏蔽了路由和发现collector的细节 - Jaeger-Collector
jaeger-collector:接收jaeger-agent 发送来的数据,然后将数据写入后端存储。jaeger-collector被设计成无状态的组件,因此可以同时运行任意数量的jaeger-collector。 - Data Store
后端存储被设计成一个可插拔的组件,支持将数据写入Cassandra、Elastic Search - Jaeger Query
接收查询请求,然后从后端存储系统中检索 trace 并通过 UI 进行展示。jaeger-query是无状态的,我们可以启动多个实例,把它们部署在Nginx这样的负载均衡器后面。
探针性能低损耗的SkyWalking
SkyWalking是一个国产的APM开源组件,具有监控、跟踪和诊断云原生架构中分布式系统的功能。SkyWalking支持多个来源和多种格式收集Trace和Metric数据,包括:
- Java、.NET Core、NodeJS 和 PHP语言自动织入的 SkyWalking格式
- 手动织入的Go客户端SkyWalking格式
- Istio追踪的格式
- Zipkin v1/v2格式
- Jaeger gRPC格式
SkyWalking 的核心是数据分析和度量结果的存储平台,通过HTTP或gRPC方式向SkyWalking Collecter提交分析和度量数据。SkyWalking Collecter对数据进行分析和聚合,并存储到数据库。最后我们可以通过 SkyWalking UI的可视化界面对最终的结果进行查看。SkyWalking支持从多个来源和多种格式收集数据:多种语言的SkyWalking Agent、Zipkin v1/v2、Istio勘测、Envoy度量等数据格式。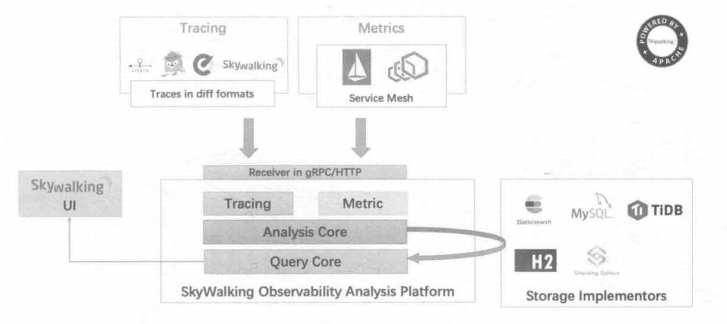
SkyWalking 6.x架构图
SkyWalking支持的存储组件有:ES、H2、Mysql、TiDB和 Sharding Sphere。SkyWalking的UI界面提供的链路追踪查询较为简单,SkyWalking拥有非常活跃的中文社区,支持多种语言的探针,且对国产开源软件全面支持。SkyWalking在探针性能方面表现优异,根据官方提供的基准测试结果,SkyWalking探针的性能损耗较低。
链路统计详细的Pinpoint
Pinpoint是一个APM工具,适用于用Java/PHP编写的大型分布式系统,Go语言项目不能直接应用Pinpoint,如需使用则需要使用代理进行改造。这里简单进行介绍,因为其链路追踪的分析较为完善。Pinpoint也是受Dapper的启发,可以通过跟踪分布式应用程序之间的调用链,帮助分析系统的整体结构以及它们中的组件是如何相互连接
Pinpoint的追踪数据粒度非常细,用户界面功能强大,Pinpoint中的服务调用展示做得非常丰富,在这方面它优于市面上大多数组件。Pinpoint使用HBase作为存储带来了海量存储的能力。丰富的界面背后,必然需要大量的数据采集,因此在几款常用链路追踪组件中,Pinpoint的探针性能最低,在生产环境需要注意应用服务的采样率,过高会影响系统的吞吐量。
另外,Pinpoint目前仅支持Java和PHP语言,采用字节码增强方式去理点,所以在理点时不需要修改业务代码,是非侵入式的,非常适合项目已经完成之后再增加调用链监控的实践场景。Pinpoint并不支持除Java、PHP语言之外的探针,在Go语言项目中应用需要基于Pinpoint进行二次封装开发。
分布式链路追踪组件对比(2024-2025更新)
| 指标/组件 | Zipkin | Jaeger | SkyWalking | Pinpoint | OpenTelemetry | SigNoz |
|---|---|---|---|---|---|---|
| OpenTracing兼容 | 支持 | 支持 | 支持 | 不支持 | 支持(原生) | 支持(基于OTel) |
| CNCF状态 | 孵化项目 | 毕业项目 | 孵化项目 | - | 毕业项目(2023年) | - |
| 客户端支持语言 | Java C# Go PHP等 | Python Go Node Java C++ C# Ruby PHP Rust | Java .NET Core NodeJS PHP | Java PHP | Go Java Python JavaScript C++ Ruby等 | Go Java Python JavaScript等 |
| 传输协议 | HTTP/MQ | UDP/HTTP | gRPC | Thrift | OTLP(OpenTelemetry Protocol) | OTLP |
| Web UI | 弱 | 一般 | 一般 | 强 | 无(依赖后端) | 强(统一视图) |
| 扩展性 | 强 | 强 | 一般 | 弱 | 强(Collector可扩展) | 强 |
| 性能损失 | 一般 | 一般 | 低 | 高 | 低(SDK优化) | 低 |
| 实现方式 | 拦截请求 侵入 | 拦截请求 侵入 | 字节码注入 无侵入 | 字节码注入 无侵入 | SDK/Agent 可侵入也可非侵入 | SDK/Agent 基于OTel |
| 告警 | 不支持 | 不支持 | 支持 | 支持 | 支持(通过Collector) | 支持(内置) |
| 统一可观测性 | 仅Tracing | 仅Tracing | Tracing+Metrics | 仅Tracing | Tracing+Metrics+Logs | Tracing+Metrics+Logs |
| 市场采用率 | 较低(2020年后下降) | 中等 | 较高(国内) | 低(仅Java/PHP) | 极高(78%) | 上升中(新兴) |
选型建议(2024-2025)
选型建议
根据不同的业务场景和需求,建议如下:
新项目/云原生环境:推荐使用 OpenTelemetry + Jaeger/SigNoz
- OpenTelemetry 作为数据采集标准
- Jaeger 作为成熟的后端存储和展示
- SigNoz 作为新兴的统一可观测性平台
已有 Zipkin/Jaeger 部署:平滑迁移到 OpenTelemetry
- OpenTelemetry 兼容现有的 Zipkin/Jaeger 后端
- 逐步替换客户端 SDK
Java/PHP 为主的项目:可考虑 Pinpoint(如需强大的UI)
- 字节码注入,无需修改代码
- 丰富的调用链展示
国内项目/中文社区支持:SkyWalking 仍是不错的选择
- 活跃的中文社区
- 对国产软件支持好
- 探针性能优异
统一可观测性需求:OpenTelemetry + SigNoz
- Tracing、Metrics、Logs 统一视图
- 开源自托管
- 完全基于 OpenTelemetry 标准
当然,除了通过修改应用程序代码增加分布式追踪之外,还有一种不需要修改代码
的非入侵的方式,那就是ServiceMesh。ServiceMesh一般会被翻译成服务啮合层,它是在网络层面拦截,通过Sidecar(Sidecar主张以额外的容器来扩展或增强主容器,而这个额外的容器被称为Sidecar容器)的方式为各个微服务增加一层代理,通过这层网络代理来实现一些服务治理的功能,因为是工作在网络层面,可以做到跨语言、非入侵。
2024-2025 年分布式链路追踪最新技术趋势
1. OpenTelemetry 成为事实标准
行业趋势
OpenTelemetry 已成为分布式链路追踪领域的事实标准,78% 的采用率使其成为 CNCF 最成功的项目之一。
- 统一可观测性:Tracing、Metrics、Logs 三大支柱的统一采集和处理
- 标准化协议:OTLP(OpenTelemetry Protocol)成为行业标准
- 生态成熟:各大云厂商和开源项目纷纷支持 OpenTelemetry
2. eBPF 技术的兴起
eBPF(Extended Berkeley Packet Filter)正在改变分布式链路追踪的实现方式:
eBPF 优势
eBPF 允许在 Linux 内核中安全地执行程序,无需修改应用程序代码即可实现深度可观测性。
eBPF 在链路追踪中的应用:
- 零代码侵入:无需修改应用程序代码即可采集追踪数据
- 内核级观测:能够捕获网络、系统调用等底层信息
- 低性能损耗:相比传统探针,eBPF 的性能损耗更低
- 完整调用链:能够捕获从用户态到内核态的完整调用链
相关项目:
- Cilium:基于 eBPF 的网络和安全解决方案,内置分布式追踪
- Pixie:基于 eBPF 的 Kubernetes 可观测性平台
- Parca:基于 eBPF 的连续性能分析工具
3. AI 辅助的异常检测
人工智能和机器学习技术正在被广泛应用于链路追踪领域:
AI 应用
AI 技术可以帮助自动发现异常模式、预测性能瓶颈、提供智能告警。
AI 在链路追踪中的应用场景:
- 异常检测:自动识别异常的调用链路和性能问题
- 根因分析:利用机器学习快速定位问题根因
- 性能预测:基于历史数据预测系统性能趋势
- 智能告警:减少误报,提高告警准确性
4. 云原生可观测性平台
新一代云原生可观测性平台正在兴起:
- Grafana Cloud:集成 Tracing、Metrics、Logs 的统一平台
- Datadog:企业级可观测性平台,支持 OpenTelemetry
- New Relic:全栈可观测性解决方案
- Dynatrace:基于 AI 的自动化可观测性平台
5. 边缘计算和分布式追踪
随着边缘计算的兴起,分布式追踪面临新的挑战:
边缘挑战
边缘环境网络不稳定、资源受限,需要轻量级的追踪方案。
边缘追踪的解决方案:
- 本地缓存:在边缘节点缓存追踪数据,网络恢复后批量上传
- 采样策略:在边缘节点实施智能采样,减少数据传输
- 压缩传输:使用高效的压缩算法减少带宽占用
- 离线追踪:支持离线场景下的追踪数据收集
2024-2025 年分布式链路追踪最佳实践
1. 采用 OpenTelemetry 标准
最佳实践
新项目应该直接采用 OpenTelemetry 作为数据采集标准,避免技术锁定。
实施步骤:
- 选择 OpenTelemetry SDK(根据编程语言)
- 配置合适的 Exporter(Jaeger、Zipkin、OTLP 等)
- 实施自动埋点(使用 OpenTelemetry Instrumentation)
- 配置采样策略(避免数据量过大)
- 集成到 CI/CD 流程
2. 合理的采样策略
采样是控制追踪数据量和性能损耗的关键:
采样策略
不同的采样策略适用于不同的场景,需要根据业务需求选择。
常用采样策略:
固定采样(Fixed Sampling)
// 采样 10% 的请求 sampler := trace.TraceIDRatioBased(0.1)动态采样(Dynamic Sampling)
- 根据服务负载动态调整采样率
- 高负载时降低采样率,低负载时提高采样率
智能采样(Smart Sampling)
- 基于错误率、响应时间等指标智能采样
- 优先采样异常请求和慢请求
基于标签的采样(Tag-based Sampling)
- 对特定标签的请求全采样
- 例如:对 VIP 用户的请求全采样
3. 上下文传播的最佳实践
正确的上下文传播是分布式追踪的关键:
上下文传播
确保 TraceID 和 SpanID 在服务间正确传播,避免链路断裂。
Go 中的上下文传播示例:
// 创建带有 trace 上下文的 context
ctx, span := tracer.Start(context.Background(), "operation")
defer span.End()
// 将 context 传递给下游服务
req, _ := http.NewRequestWithContext(ctx, "GET", "http://service-b", nil)
client.Do(req)注意事项:
- 始终使用
context.Context传递 trace 信息 - 避免在异步操作中丢失 context
- 使用
context.WithValue传递业务数据 - 注意 context 的生命周期管理
4. 性能优化
确保追踪系统不会影响业务性能:
性能影响
不合理的追踪配置可能导致严重的性能问题。
性能优化建议:
异步导出
// 使用批处理和异步导出 tp := sdktrace.NewTracerProvider( sdktrace.WithBatcher(exp), sdktrace.WithBatchTimeout(5*time.Second), )合理的采样率
- 生产环境建议采样率 1-10%
- 测试环境可以全采样
避免过度埋点
- 只在关键路径埋点
- 避免在循环中创建 span
使用轻量级 SDK
- 选择性能优化过的 SDK
- 避免使用过重的 instrumentation
5. 数据安全和隐私保护
追踪数据可能包含敏感信息,需要做好保护:
数据安全
追踪数据可能包含用户信息、请求参数等敏感数据,需要脱敏处理。
数据保护措施:
敏感数据脱敏
// 使用 span.SetAttributes 记录脱敏后的数据 span.SetAttributes( attribute.String("user.id", hashUserID(userID)), attribute.String("request.params", sanitizeParams(params)), )访问控制
- 限制追踪数据的访问权限
- 实施审计日志
数据加密
- 传输层加密(TLS)
- 存储层加密
数据保留策略
- 定期清理过期数据
- 根据合规要求设置保留期限
6. 与其他可观测性数据的关联
将追踪数据与日志、指标关联,提供完整的可观测性:
统一可观测性
通过 TraceID 关联 Tracing、Metrics、Logs,提供完整的系统视图。
关联方法:
在日志中记录 TraceID
log.WithField("trace_id", span.SpanContext().TraceID().String()). Info("Processing request")在 Metrics 中添加 TraceID 标签
histogram.Record(ctx, duration, metric.WithAttributes(attribute.String("trace_id", traceID)))使用统一平台
- 选择支持 Tracing、Metrics、Logs 统一的平台
- 例如:SigNoz、Grafana Cloud
Service Mesh 与分布式链路追踪(2024-2025更新)
Service Mesh 的发展趋势
根据 CNCF 2024 年技术雷达报告,Service Mesh 在生产环境的采用率持续增长:
Service Mesh 采用
Service Mesh 正在从实验性技术转向生产就绪的技术,越来越多的企业开始采用。
主流 Service Mesh 方案:
Istio - 最流行的 Service Mesh
- 功能完善,社区活跃
- 原生支持 OpenTelemetry
- 适合大型企业
Linkerd - 轻量级 Service Mesh
- 性能优异,资源占用低
- 简单易用
- 适合中小型项目
Consul Connect - Consul 集成的 Service Mesh
- 与 Consul 服务发现无缝集成
- 配置简单
- 适合已有 Consul 部署的环境
Service Mesh 的优势
Service Mesh 优势
Service Mesh 通过 Sidecar 代理实现非侵入式的分布式追踪,特别适合多语言环境。
主要优势:
零代码侵入
- 无需修改应用程序代码
- 自动采集追踪数据
- 降低开发成本
跨语言支持
- 不受编程语言限制
- 统一的追踪标准
- 适合多语言微服务
统一管理
- 集中配置追踪策略
- 统一的数据采集
- 简化运维
丰富的功能
- 流量管理
- 安全策略
- 可观测性
Service Mesh 与 OpenTelemetry 的集成
集成方案
现代 Service Mesh 都支持 OpenTelemetry,可以无缝集成到现有的可观测性体系中。
Istio + OpenTelemetry 集成示例:
# Istio 配置示例
apiVersion: telemetry.istio.io/v1alpha1
kind: Telemetry
metadata:
name: mesh-default
spec:
tracing:
- providers:
- name: otel-collector
randomSamplingPercentage: 10.00配置 OpenTelemetry Collector 接收 Istio 数据:
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
exporters:
jaeger:
endpoint: jaeger:14250
tls:
insecure: true
service:
pipelines:
traces:
receivers: [otlp]
exporters: [jaeger]Service Mesh 的挑战和限制
Service Mesh 挑战
Service Mesh 不是银弹,需要权衡其带来的复杂性和收益。
主要挑战:
性能开销
- Sidecar 代理会带来额外的网络延迟
- 需要额外的资源(CPU、内存)
- 需要优化 Sidecar 配置
运维复杂度
- 需要运维 Service Mesh 控制平面
- 需要理解复杂的配置
- 需要专门的技能
学习曲线
- 概念复杂,学习成本高
- 需要时间掌握最佳实践
调试困难
- 问题可能出在 Sidecar
- 需要额外的调试工具
Service Mesh 选型建议
选型建议
根据团队规模、技术栈、业务需求选择合适的 Service Mesh 方案。
选型决策树:
大型企业/复杂环境
- 选择 Istio
- 功能完善,生态成熟
- 需要专门的运维团队
中小型项目/追求简单
- 选择 Linkerd
- 轻量级,易用
- 性能优异
已有 Consul 部署
- 选择 Consul Connect
- 与现有系统集成
- 配置简单
云原生环境
- 考虑云厂商的托管 Service Mesh
- AWS App Mesh
- Google Cloud Service Mesh
- Azure Service Mesh
实践
在上一章中的认证鉴权Demo中进行链路埋点
创建并注入Tracer
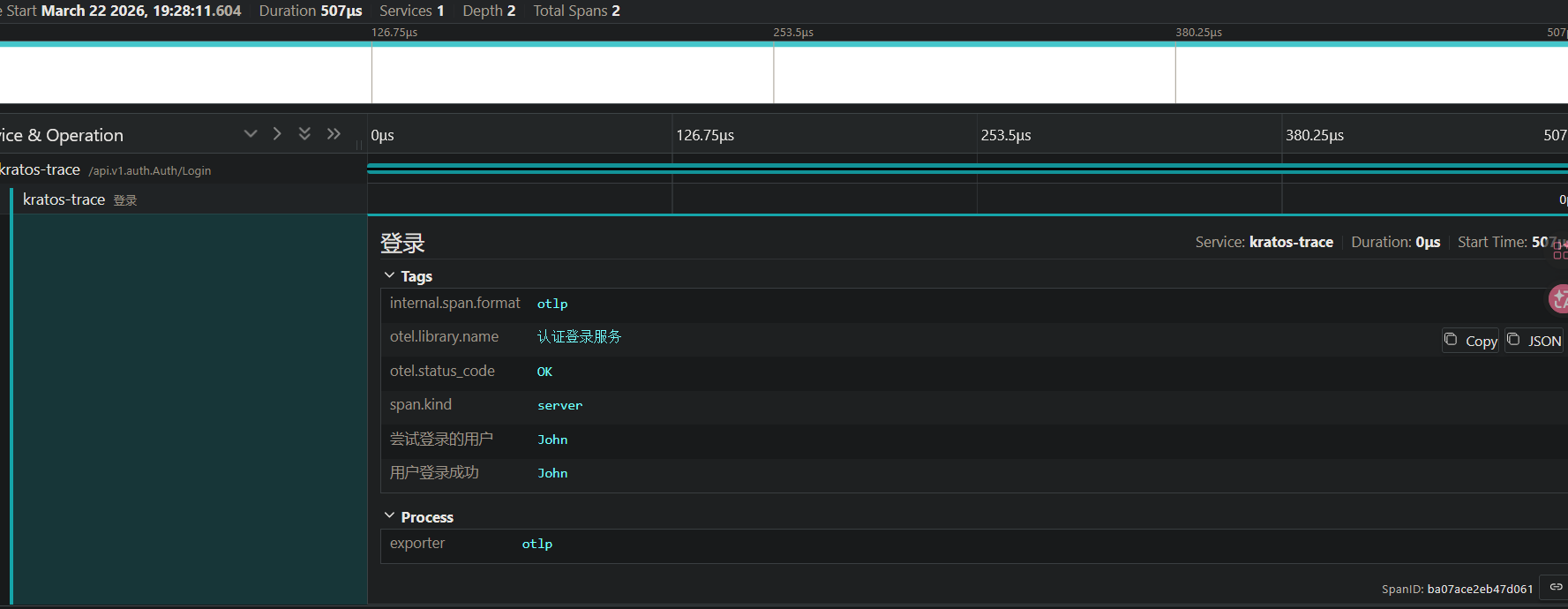
先给登录接口插个span记录一下可能的登录结果
func (s *AuthService) Login(ctx context.Context, req *pb.LoginRequest) (*pb.LoginReply, error) {
switch {
case req.GetUsername() == "":
return nil, ErrEmptyUsername
case req.GetPassword() == "":
return nil, ErrEmptyPassword
}
// (在参数校验完之后) 创建tracer
tracer := otel.Tracer("auth-login-service") // 获取span
// 对应的标签是otel.library.name
// 创建span
ctx, span := tracer.Start(ctx, "login", // 设置操作名称
trace.WithTimestamp(time.Now()), // 设置时间戳
trace.WithSpanKind(trace.SpanKindServer), // 服务端处理请求
trace.WithAttributes(
attribute.String("user", req.GetUsername()), // 设置标签
),
)
defer span.End()
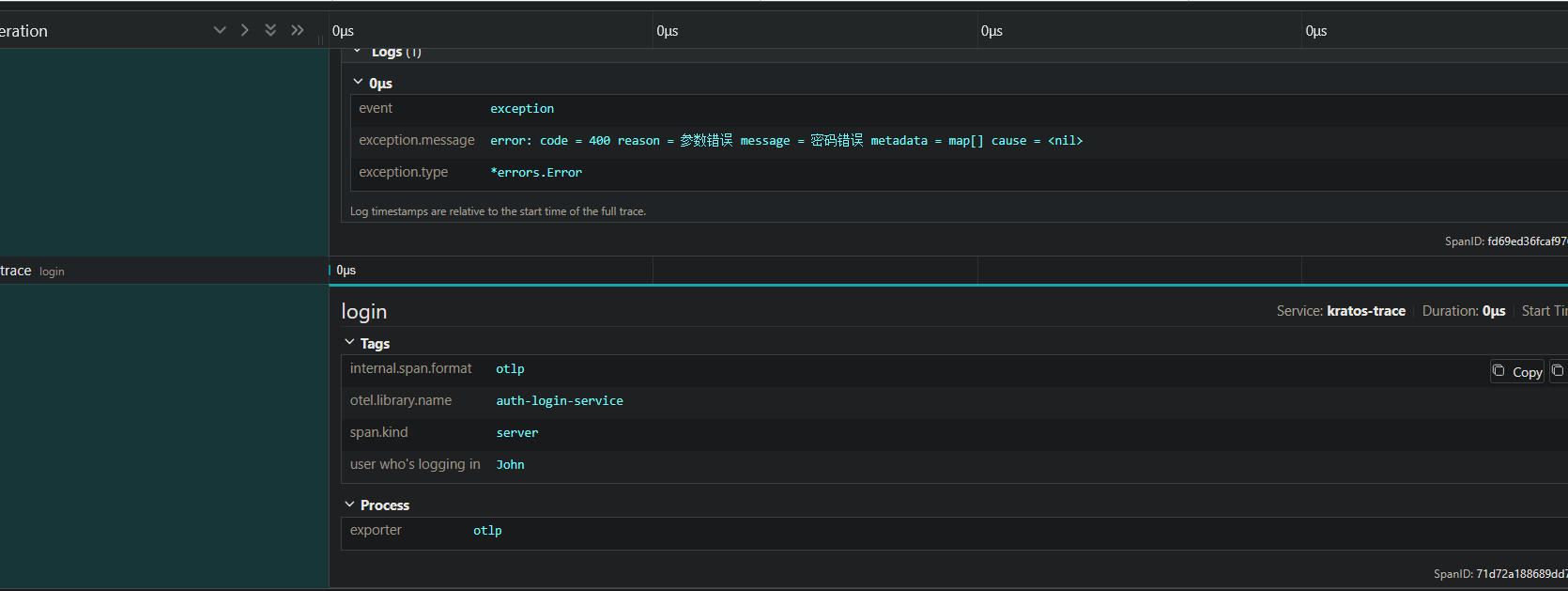
userInDB, err := s.ur.GetUserByUsername(ctx, req.GetUsername())
if err != nil {
span.RecordError(err, trace.WithTimestamp(time.Now())) // 记录异常
// 记得进行span.SetStatus(codes.Error)
// 不过Kratos本身也预设了一些插桩, 这里插不插没什么大不了的
if errors.As(err, errors.Error{}) { // 如果是Kratos自定义异常, 那么可以直接返回
return nil, err
}
return nil, ErrUserNotExist
}
switch {
case req.GetUsername() != userInDB.Username:
span.RecordError(err,
trace.WithTimestamp(time.Now()),
trace.WithAttributes(attribute.String("user", req.GetUsername())))
// span.SetStatus(codes.NotFound)
return nil, ErrUserNotExist
case req.GetPassword() != string(userInDB.Password):
span.RecordError(err,
trace.WithTimestamp(time.Now()),
trace.WithAttributes(attribute.String("user", req.GetUsername())))
// span.SetStatus(codes.InvalidArgument)
return nil, ErrPasswordMismatch
}
var token string
if token, err = s.jr.NewJWT(userInDB); err != nil {
s.log.Errorf("无法为用户[%v]生成JWT凭据: %v", userInDB.Username, err)
span.RecordError(err,
trace.WithTimestamp(time.Now()),
trace.WithAttributes(attribute.String("user.token.generation_failed", req.GetUsername())),
)
span.SetStatus(codes.Error, "token.generation_failed")
return nil, ErrJWTGenerateFailed
}
span.SetAttributes(attribute.String("user.logged_in", req.GetUsername()))
span.SetStatus(codes.Ok, "Logged in successfully")
return &pb.LoginReply{
Message: "登录成功",
Token: token,
}, nil
}
注
用中文不是好文明
在repo逻辑中进行插桩
不要把span直接往repo函数逻辑里插,只要确保ctx是同一个就行了
看了一圈感觉没什么好加的,就不打算为了练习而练习了
在中间件逻辑里插桩
提示
context是不可变的,记得重命名新的Context,确保span能传给下一个中间件或传到服务里
// ExtraJWTVerifier
//
// 额外JWT状态校验器
func ExtraJWTVerifier(jr *data.JWTRepo) middleware.Middleware {
return func(handler middleware.Handler) middleware.Handler {
return func(ctx context.Context, req interface{}) (reply interface{}, err error) {
var trctx context.Context
var span trace.Span
tracer := otel.Tracer("privilege-payload-verify-middleware")
// 记得显式替换下游context,把spanID传下去
trctx, span = tracer.Start(ctx, "privilege-payload-verify",
trace.WithTimestamp(time.Now()),
trace.WithSpanKind(trace.SpanKindServer),
)
defer span.End()
if _, ok := transport.FromServerContext(ctx); ok {
// JWT荷载校验
// Do something on entering
var c *data.JWTClaim
var valid bool
rawClaim, _ := jwt.FromContext(trctx)
if c, valid = rawClaim.(*data.JWTClaim); !valid {
err = ErrJWTType
span.RecordError(err, trace.WithAttributes(
attribute.String("jwt.type", "invalid"),
))
span.SetStatus(codes.Error, err.Error())
return nil, err
}
if !jr.Compare(trctx, c.GetJTI(), c) {
err = ErrJWTMismatch
span.RecordError(err, trace.WithAttributes(
attribute.String("jwt.type", "mismatch"),
))
span.SetStatus(codes.Error, err.Error())
return nil, err
}
defer func() {
// Do something on exiting
}()
span.AddEvent("incoming user passed the jwt payload verification",
trace.WithTimestamp(time.Now()),
trace.WithAttributes(
attribute.String("jwt.type", "valid"),
attribute.String("user.username", c.GetUsername()),
attribute.Int("user.privilege.enum_value", int(c.GetPrivilege())),
),
)
}
return handler(trctx, req)
}
}
}
func (u *UserService) GetUser(ctx context.Context, request *user.GetUserRequest) (*user.GetUserReply, error) {
tracer := otel.Tracer("userinfo-service")
trctx, span := tracer.Start(ctx, "userinfo-service")
defer span.End()
var res *ent.User
var err error
claim, err := u.jr.FromContext(trctx)
if err != nil {
span.RecordError(err)
span.SetStatus(codes.Error, err.Error())
return nil, err
}
// 请求参数若有一与当前JWT不匹配, 则检查是否有更高的权限
if uint32(claim.GetUserID()) != request.GetId() || claim.GetUsername() != request.GetUsername() {
u.log.Infof("用户[%v]请求携带的参数与其JWT身份中的数据不匹配, 正在校验权限", claim.GetUsername())
span.AddEvent("用户请求携带的参数与其JWT身份中的数据不匹配, 正在校验权限",
trace.WithTimestamp(time.Now()),
trace.WithAttributes(
attribute.String("jwt.username", claim.GetUsername()),
attribute.Int("jwt.privilege", int(claim.GetPrivilege())),
attribute.Int("jwt.userid", claim.GetUserID()),
attribute.String("request.username", request.GetUsername()),
attribute.Int("request.id", int(request.GetId())),
),
)
if claim.UnableDoAnyThing() || !(claim.IsUser() || claim.IsAdminOrHigher()) {
span.RecordError(err, trace.WithAttributes(
attribute.String("user.privilege.digest", "cannot meet higher requirement"),
))
span.SetStatus(codes.Error, ErrForbidden.Error())
return nil, ErrForbidden
}
}
span.AddEvent("用户请求携带的参数与其JWT身份中的数据匹配或拥有更高的权限, 继续处理",
trace.WithTimestamp(time.Now()),
trace.WithAttributes(
attribute.String("jwt.username", claim.GetUsername()),
attribute.Int("jwt.privilege", int(claim.GetPrivilege())),
attribute.Int("jwt.userid", claim.GetUserID()),
attribute.String("request.username", request.GetUsername()),
attribute.Int("request.id", int(request.GetId())),
),
)
switch {
case request.Id == 0 && request.GetUsername() == "":
return nil, ErrEmptyUsername
case request.Id != 0:
res, err = u.ur.GetUserById(trctx, int(request.Id))
case request.GetUsername() != "":
res, err = u.ur.GetUserByUsername(trctx, request.GetUsername())
}
res, err = u.ur.GetUser(trctx, int(request.GetId()), request.GetUsername())
if err != nil {
u.log.Errorf("无法获取用户: %v", err)
return nil, ErrUserNotExist
}
return &user.GetUserReply{
User: &user.UserModel{
Id: uint32(int32(res.ID)),
Username: res.Username,
Privilege: user.UserPrivilege(int32(res.Privilege)),
},
}, nil
}