Golang学习笔记(一)
CLI指令
go version # 查看版本号
go env # 查看go自己的环境变量goimports包安装
go env -w GOPROXY=https://goproxy.cn # 设置Go代理为国内镜像源
go install -v golang.org/x/tools/cmd/goimports@latest # 然后运行Go官方给的指令,安装所需的包
go list -m -f={{.Version}} golang.org/x/tools@latest # 查看版本goimports是一个自动格式化import语句的CLI工具
一
Hello World
// main.go
package main // 嘿嘿我Package又来定义包名了
import "fmt"
func main() {
fmt.Println("Hello World");
}写完之后go run main.go即可运行
Go逻辑包名简介
语法:
package <包名>不同Go代码文件可使用同一个包名,它们在编译阶段会被视为同一个命名空间中的代码,共享彼此的生命周期
尽管Golang倡导包名和目录保持一致,但我们确实可以利用package的机制来将项目代码分散到不同的文件中
fmt包简介
import "fmt"fmt包,即format,为Go提供了格式化输入输出的功能——说人话,就是Print和Println,以及Scan都在fmt里,类似于C的studio,存在感应该是差不多的
fmt.Println("Hello World");一些打印函数
fmt.Print // 顾名思义不换行的字符串打印
fmt.Println // 换行的字符串打印
fmt.Printf // 格式化打印, 和C语言差不多Print和Println
对于多个字符串字面量作为函数参数的情况,Print和Println都会自动连接字面量,但Println连接字符串时不会在中间加\n,而是加个空格:
fmt.Print("A", "B", "C", "\n");
// ABC
fmt.Println("A", "B", "C");
// A B CPrintf
Printf直接类比C语言的printf理解和使用,但Go还给Printf函数加了%v占位符,可以处理任何类型的变量
%v的魅力
当我们开始处理更复杂的类型,比如结构体 (struct) 时,%v 还有两个更有用的变体:
%v: 默认值。对于结构体,它只打印各个字段的值。%+v:带字段名。在打印结构体时,会把字段名也一起打印出来,非常便于调试。%#v: Go 语法表示。会打印出这个值的、符合 Go 语法的完整表示。
package main
import "fmt"
type User struct {
ID int
Name string
}
func main() {
u := User{ID: 101, Name: "Bob"}
fmt.Printf("v: %v\n", u)
fmt.Printf("+v: %+v\n", u)
fmt.Printf("#v: %#v\n", u)
}上面的代码的输出示例如下:
v: {101 Bob}
+v: {ID:101 Name:Bob}
#v: main.User{ID:101, Name:"Bob"}%v变种也并非只能用在结构体上,用在一般变量上也是可以的……就是不那么有趣……
基础语法
变量定义
Go作为一门现代化静态类型语言,既有如下前置关键字后置类型的变量定义写法:
var s string = "Hello World"
// 也可以省略类型,由编译器自行推导
var s = "Hello World"也有由编译器支持的智能类型推导:
s := "Hello World";:=学名叫短变量定义符
Go的社区规范是能让编译器自行推导就让编译器自行推导,除非是在函数外面/包级别的情形,才必须使用var关键字,让编译器在进入函数堆栈前给包级别的全局变量 分配好内存空间

和C语言不同的是,Go的变量在定义后必须至少被调用一次,否则就无法通过编译(导入的包也是至少要使用一次的)
注
刚刚发现Golang语句末尾的分号不是必需的
无视风险,强行定义但不使用
Python和C都允许未引用的符号进入解释或编译期(Python会warning,但问题不大)
Go倒也提供了一个“紧急出口”来处理你确实需要临时忽略某个变量或导入的情况。那就是空白标识符 (Blank Identifier) __ 是一个特殊的变量,你可以给它赋值,但它的值会被立即丢弃。编译器知道你是在有意地忽略这个值。
如下使用_忽略变量:
// 我现在只关心错误,暂时不处理 user
user, err := GetUser("123")
if err != nil {
log.Fatal(err)
}
// TODO: 后面再来处理 user
_ = user // 明确告诉编译器:我知道我没用它,我是故意的以及忽略包的引用:
import (
"database/sql"
_ "github.com/go-sql-driver/mysql" // _ 表示我只执行你的init(),但不会调用mysql.xx函数
)变量声明的其他语法
使用var时可以对多个变量赋上同样的值:
注
小括号语法也可以给import用:
import (
"fmt"
"math"
)记得定义了变量就一定要用
也可以一次性声明多个值不同的变量: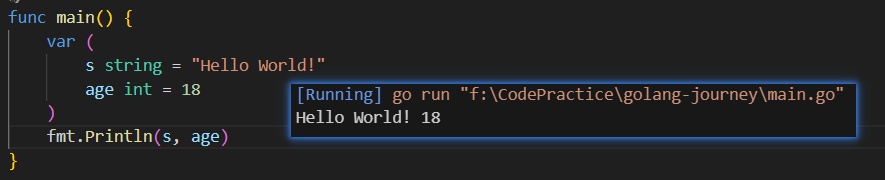
短变量声明符 左右两边可以有不止一个变量和参数,只要个数对应上就行:
func main() {
s, age := "Hello World", 18
fmt.Printf("%s, I'm %d years old.", s, age)
// Hello World, I'm 18 years old.
}常量定义
const name = value
// const pi = 3.1415926多个常量也可以一起声明:
const (
pi float64 = 3.1415926
e float64 = 2.71
)下一行的常量可以沿用上一行的赋值模式:
func main() {
const (
pi1 float64 = 3.14
pi2 // 赋值模式一致,均为 <variable> float64 = 3.14
)
fmt.Println(pi1, pi2)
// 3.14 3.14
}常量声明计数器iota
iota 是 Go 语言的一个特殊常量,它实际上是一个可以在 const 块中使用的、由编译器维护的计数器
相关信息
iota (发音为 /aɪˈoʊtə/) 是希腊字母表的第九个字母 (Ι, ι)。
在英语中,iota 这个词被引申为“极微小的量”或“丝毫”。比如,英文里会说 "There is not one iota of truth in his story." (他的话里没有一丝一毫是真的)。
为什么 Go 语言选择它?
你可以把它想象成一个增量的“原子单位”或“最小步进”。它代表了常量组中最小的、自动增长的那个单位,这个含义与它的希腊字母起源和引申义非常贴切。
它的核心工作规则只有三条,非常简单:
iota只在 const 关键字声明的常量块中有效。- 每当一个新的
const块开始时,iota的值会自动重置为 0。 - 在同一个
const块中,每定义一个常量(每换一行),iota 的值就自动加 1。
func main() {
const (
count0 = iota
count1
count2
count3
)
fmt.Println(count0,count1,count2,count3)
// 0 1 2 3
}使用_可以跳过iota的某几个计数,比如跳过0:
func main() {
const (
_ = iota
count1
count2
count3
)
fmt.Println(count1,count2,count3)
// 1 2 3
}iota只在常量声明换行时才递增计数:(加上前面的赋值模式重复)
func main() {
const (
_, count1 = iota, iota
count2, count3 // 换行到这里iota才递增到1
count4, count5
)
fmt.Println(count1)
fmt.Println(count2, count3)
fmt.Println(count4, count5)
/*
0
1 1
2 2
*/
}iota可用于简洁地定义枚举常量 ,也可以用来实现位掩码等等:
func main() {
// 定义星期枚举
const (
_ = iota
Monday
Tuesday
Wednesday
Thursday
Friday
Saturday
Sunday
)
fmt.Println(Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday)
// 1 2 3 4 5 6 7
// 定义枚举常量以演示Linux文件权限
const (
Read = 1 << iota
Write = 1 << iota
Execute = 1 << iota
)
fmt.Printf("读权限: %d\n写权限: %d\n执行权限: %d\n", Read, Write, Execute)
// 写权限: 2
// 读权限: 1
// 执行权限: 4
}Go的注释
// 单行注释
/* 多行注释 */数据类型(一)
基本数据类型
整型
int8 int16 int32 int64
uint8 uint16 uint32 uint64知道数值写大了写小了会溢出不给编译就行了
高位向低位转换时也有可能溢出
func main() {
var num1 uint8 = 130
fmt.Printf("值为%d, 类型为%T\n", num1, num1)
// 值为130, 类型为uint8
var num2 = int8(num1) // 可以强制转换
fmt.Printf("值为%d, 类型为%T\n", num2, num2)
// 值为-126, 类型为int8
}但能通过编译
对应占位符:
%d%b:二进制输出%o:八进制输出%x:十六进制输出- ...
func main() {
num := 31
// 变量类型
fmt.Printf("Type: %T\n", num) // Type: int
// 二进制输出
fmt.Printf("%b\n", num) // 11111
// 八进制输出
fmt.Printf("%o\n", num) // \037
// 带前导0八进制输出
fmt.Printf("%#o\n", num) // 037
// 十进制输出
fmt.Printf("%d\n", num) // 31
// 十六进制输出
fmt.Printf("%x\n", num) // 1f
// 大写字母十六进制输出
fmt.Printf("%X\n", num) // 1F
// 带前缀小写字母十六进制输出
fmt.Printf("%#x\n", num) // 0x1f
// 带前缀大写字母十六进制输出
fmt.Printf("%#X\n", num) // 0X1F
}这里顺便了解一下%T占位符,可以打印参数的类型
func main() {
var small_num uint8 = 31
fmt.Printf("值为%d, 类型为%T\n", small_num, small_num)
// 值为31, 类型为uint8
}特殊整型
uint // 取决于操作系统架构;32位操作系统上就是uint32,64位操作系统上就是uint64
int // 32位操作系统上就是int32,64位操作系统上就是int64
uintptr // 无符号整型,用于存放一个指针重要
实际项目中整数类型、切片、map的元素数量等都可以用int来表示。在涉及到二进制传输、为了保持文件的结构不会受到不同编译目标平台字节长度的影响,不要使用int和uint
浮点型
float32 float64都是IEEE754浮点数
对应占位符为%f(默认保留六位小数,不够就补0);%.2f表示保留两位小数
可用math.MaxFloat32和math.MaxFloat64获得各自变量类型的最大值:
import (
"fmt"
"math"
)
func main() {
maxFloat32 := math.MaxFloat32
maxFloat64 := math.MaxFloat64
// 打印值和类型
fmt.Printf("maxFloat32: %v或%.2f, %T\n", maxFloat32, maxFloat32, maxFloat32)
// maxFloat32: 3.4028234663852886e+38或340282346638528859811704183484516925440.00, float64
fmt.Printf("maxFloat64: %v或%.2f, %T\n", maxFloat64, maxFloat64, maxFloat64)
// maxFloat64: 1.7976931348623157e+308或179769313486231570814527423731704356798070567525844996598917476803157260780028538760589558632766878171540458953514382464234321326889464182768467546703537516986049910576551282076245490090389328944075868508455133942304583236903222948165808559332123348274797826204144723168738177180919299881250404026184124858368.00, float64
}变量定义时可以使用科学计数法:
func main() {
pi := 314e-2 // 314 * (10 ^ -2), 小数点前移两位
fmt.Println(pi) // 3.14
}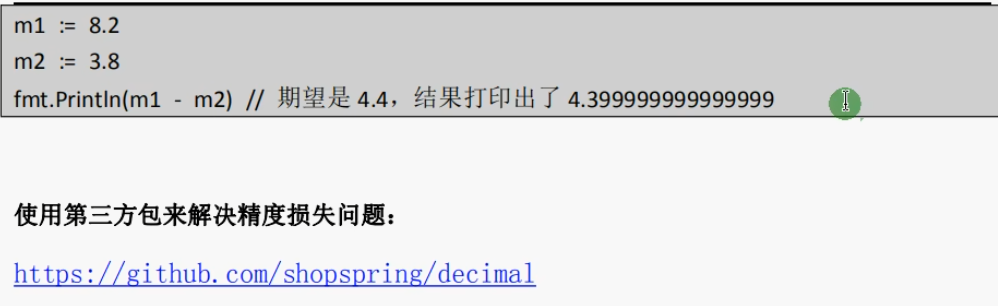
不过Golang也逃不掉浮点数精度丢失(截图是教程里的)
导入一下decimal试试看
go mod init golang-journey // 初始化项目方便导包 go mod init <包名>
go get github.com/shopspring/decimal // 导个包func main() {
f := 314.9
f_100times := f * 100 // 31489.999999999996; 丢失精度
fmt.Println(f_100times)
decimal_f := decimal.NewFromFloat(f)
decimal_f_100times := decimal_f.Mul(decimal.NewFromFloat(100)) // 31490
fmt.Println(decimal_f_100times)
}Go不支持重载运算符,所以decimal额外实现了多种运算函数来处理特殊高精度数运算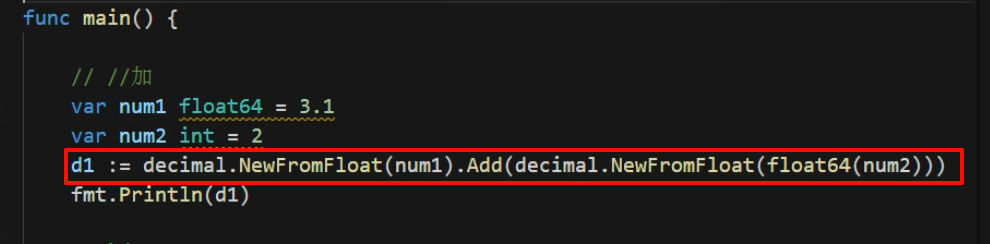
视频教程里的运算更是冗长……
浮点型也可以转换成整型,或者转回来——注意自己收拾精度丢失的问题
布尔型
Go语言中以bool类型进行声明布尔型数据,布尔型数据只有true(真)和false(假)两个值。
注意:
- 布尔类型变量的默认值为false。
- Go语言中不允许将整型强制转换为布尔型,
- 布尔型无法参与数值运算,也无法与其他类型进行转换。
注
Go源头上不支持隐式类型转换
字符串
字符串转义符
参考其他语言,不多做赘述
多行字符串
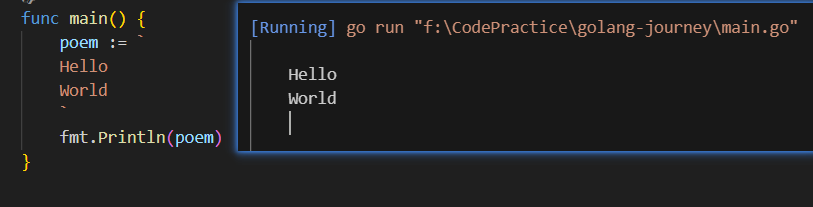
使用反引号``包裹
字符串方法
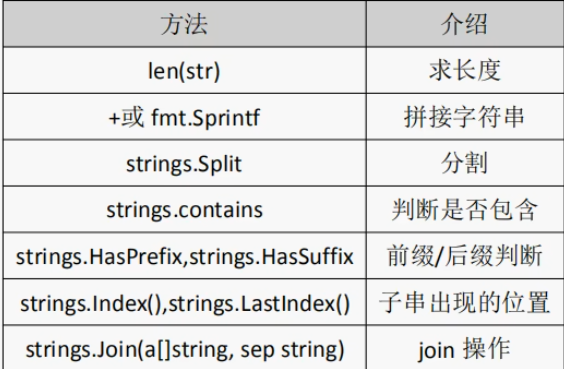
func main() {
s := "hello world"
s1, s2 := "hello", "world"
// 求字符串长度
fmt.Printf("字符串长度为: %d\n", len(s)) // 字符串的字节长度为: 11,不是字符个数,使用Unicode字符的时候特别要注意这个问题
// 拼接字符串 加号拼接
fmt.Printf("%v + %v = %v\n", s1, s2, s1+s2) // hello + world = helloworld
// 拼接字符串 Sprintf拼接
fmt.Printf("%v + %v = %v\n", s1, s2, fmt.Sprintf("%v%v", s1, s2)) // hello + world = helloworld
// 字符串分割
fmt.Println(strings.Split(s, " ")) // [hello world] // 数组元素用空格而不是逗号分隔
// 字符串包含子串, 以w为例
fmt.Println(strings.Contains(s, "w")) // true
// 前缀He判断, 后缀ld判断
fmt.Println(strings.HasPrefix(s, "He"), strings.HasSuffix(s, "ld")) // false true
// 子串world出现的位置
fmt.Println(strings.Index(s, "world")) // 6 // 下标从0开始
// join操作
fmt.Println(strings.Join([]string{"hello", "world"}, " ")) // hello world
}你说得对,Golang确实没有运算符重载,但和Java一样都支持字符串的+拼接运算……
注意,unsafe.Sizeof无法查看字符串变量的大小
注
值得注意的是,虽然 + 很方便,但它在循环中进行大量字符串拼接时,性能并不好。因为 Go 的字符串是不可变的,每次 s = s + "more" 都会创建一个全新的字符串,导致不必要的内存分配和垃圾回收。
在这种情况下,应该使用更高效的 strings.Builder:
package main
import (
"fmt"
"strings"
)
func main() {
words := []string{"hello", "world", "from", "go"}
// 不推荐的方式
var sentence1 string
for _, word := range words {
sentence1 += word + " "
}
fmt.Println(sentence1)
// 推荐的方式
var builder strings.Builder
for _, word := range words {
builder.WriteString(word)
builder.WriteString(" ")
}
sentence2 := builder.String()
fmt.Println(sentence2)
}默认值/零值
在许多语言中(比如 C),当你声明一个变量但没有给它赋值时,它的初始值是未定义的(可能是内存中的任意“垃圾”数据)。在 Python 中,变量在赋值前甚至不存在。
Go 语言完全不同。 Go 的设计哲学是安全和可预测。为了实现这一点,Go 规定:任何变量在声明后,都将自动被赋予一个明确的、可预测的初始值。这个值就叫做“零值” (Zero Value)。
这意味着在 Go 中,不存在“未初始化”的变量。只要变量存在,它就有一个合法的、可用的值。这从源头上消除了因使用未初始化变量而导致的一整类 bug。
| 类型类别 | 具体类型 (示例) | 零值 | 解释与类比 |
|---|---|---|---|
| 数值类型 | int, int8, int64 | 0 | 所有整型,无论是有符号还是无符号,默认都是数字 0。 |
float32, float64 | 0.0 | 所有浮点类型,默认也是数字 0。 | |
complex64, complex128 | 0+0i | 复数的实部和虚部都是0。 | |
| 布尔类型 | bool | false | 布尔值的默认状态是 假。 |
| 字符串类型 | string | "" | 字符串的零值是一个空字符串,而不是 nil!这是一个可用的、长度为0的字符串。 |
| 其他基础类型 | byte (是 uint8 的别名) | 0 | 字节的默认值是0。 |
rune (是 int32 的别名) | 0 | Unicode 码点的默认值是0。 | |
| 指针类型 | *int, *User | nil | nil 是所有指针、接口、函数、切片、映射和通道类型的零值。它表示该指针“不指向任何东西”。 |
| 结构体类型 | struct | 每个字段都是其对应类型的零值 | 这是一个递归的定义。结构体的零值不是 nil,而是一个所有字段都被初始化为其各自零值的实例。 |
??数据类型
byte和rune类型
func main() {
a_byte := 'c' // 这里实际上是rune,也就是int32的别名
fmt.Printf("%c或%v: [%T] %#v\n", a_byte, a_byte, a_byte, a_byte)
// c或99: [int32] 99
}写作int32,拼作byte,读作rune……
如你所见,直接打印参数(比如用%v)时,输出的是参数对应的Unicode码值,99;而使用%c时打印的则是Unicode字符
byte类型需要手动显式声明:
func main() {
a_rune := 'c'
fmt.Printf("%c或%v: [%T] %#v\n", a_rune, a_rune, a_rune, a_rune)
// c或99: [int32] 99
var a_byte byte = 'c'
fmt.Printf("%c或%v: [%T] %#v\n", a_byte, a_byte, a_byte, a_byte)
// c或99: [uint8] 0x63
}注
在 Go 中,string 的底层是一个只读的 []byte (字节切片),并且它的编码格式被强力推荐为 UTF-8。
UTF-8 是一种可变长度编码:
- 像 'c' 这样的 ASCII 字符,只占 1 个字节。
- 像 '好' 这样的常用汉字,占 3 个字节。
- 像 '😊' 这样的 emoji,占 4 个字节。
这就导致了一个重要的结论:直接按下标遍历字符串,遍历的是 byte,而不是 rune (字符)!
相关信息
rune类型并非 Go 语言首创。它直接继承自 Go 的“精神前作”——Plan 9 from Bell Labs 操作系统。Go 的三位核心设计者中,有两位(Ken Thompson 和 Rob Pike)正是 Plan 9 和 UTF-8 的关键创造者。
rune 这个词完美地满足了他们当时的所有要求(感兴趣的话可以自己查询):
- 含义贴切:古代的符文(runes)就是一个个独立的、表意的符号。这个词本身就充满了“抽象符号”的意味,与“具体的字节”形成了鲜明对比。它抓住了字符的本质,非常地柏拉图式理想
- 简短且独特:它很短,符合 Go (以及 Plan 9) 的命名偏好。而且在编程语言中几乎没被用过,不会引起混淆。
- 有点“酷”:这个名字带有一点神秘和历史感,符合 Bell Labs 那种黑客文化的品味。
你可以用一个非常形象的比喻来记住 rune 和 byte 的区别,这也正是这个命名的精髓所在:
| 概念 | Go 的术语 | 它代表什么 |
|---|---|---|
| 字符的“灵魂” | rune | 一个字符的抽象身份——它的 Unicode 码点。'好' 的灵魂就是它的码点 22909。 |
| 字符的“肉体” | []byte | 这个字符在内存或磁盘上如何被编码和存储。'好' 的肉体就是 UTF-8 编码后的三个字节 [228, 189, 160]。 |
因此,当你写下 '好' 时,你是在创造一个 rune,引用的是这个字的灵魂。当你把它存入一个 string 时,Go 会用 UTF-8 编码规则,为这个灵魂塑造一个 []byte 的肉体。
遍历字符串中的字符(不是字节)
func main() {
s := "你好"
fmt.Println("字符串长度 (字节数):", len(s)) // 输出 6,因为一个汉字占3个字节
// 错误的遍历方式 (遍历字节)
for i := 0; i < len(s); i++ {
fmt.Printf("%c ", s[i]) // 会输出乱码
}
fmt.Println()
// 正确的遍历方式 (遍历 rune)
for _, r := range s { // for...range 遍历字符串时,会自动按 rune 解码
fmt.Printf("%c ", r)
}
fmt.Println() // 输出: 你 好
}字符串修改
要修改字符串,需要先将其转换成
[]rune或[]byte,完成后再转换为string。无论哪种转换,都会重新分配内存,并复制字节数组。
func main() {
s := "Hello World!"
runeS := []rune(s)
runeS[0] = 'h'
fmt.Println(string(runeS))
s = "Hello World!"
byteS := []byte(s)
byteS[0] = 'h'
fmt.Println(string(byteS))
}基本数据类型间的转换
由于Golang没有隐式类型转换,所以哪怕是整型,也必须转换到一致的数据宽度才能运算……
复合数据类型
数组
字符串切片就是一种数组……啊呸,切片……
fmt.Println(strings.Split(s, " ")) // [hello world]运算符
算数运算符
二元运算符:
+-*/:除法;整型除整型还是得到整型(小数位舍去),浮点型除浮点型才得到浮点型;没有隐式类型转换%:求余
一元运算符(其实是语句):++:不是运算符,其实是语句(下同);并且没有前++的写法,要写成a++而不是++a,更不能a=i++--
关系运算符
==!=<<=>>=
逻辑运算符
&&||!:非运算符
位运算符
<<>>&:按位与运算^:按位异或运算|:按位或运算
赋值运算符
=:最简单的赋值运算符+=-=*=/=%=
二
流程控制
if-else分支结构
if statement1 { // 逻辑表达式不需要用括号括起来
... // 只有一行语句也要加大括号
}else if statement2 {
...
}示例:
func main() {
a, b := 5, 2
if a > b {
fmt.Println("a > b")
} else {
fmt.Println("a <= b")
}
// a > b
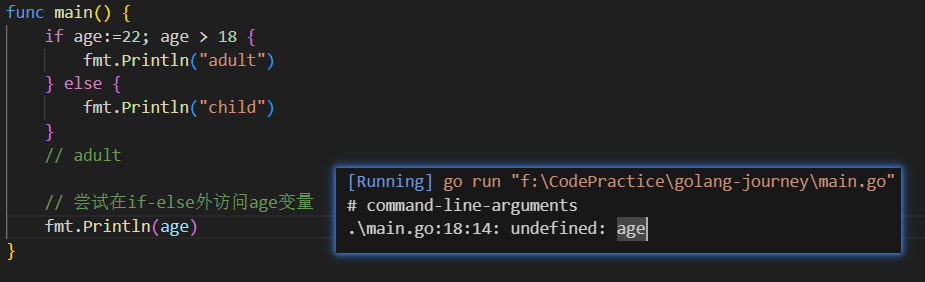
}短变量声明符 可以用在逻辑表达式里,临时创建一个变量,这个变量的生命周期仅限于if-else块内(或for循环块内)
func main() {
if age:=22; age > 18 {
fmt.Println("adult")
} else {
fmt.Println("child")
}
// adult
}
for循环结构
for 初始化语句; 逻辑判断; 迭代语句 {
...
}示例:
func main() {
for i := 1; i < 10; i++ {
fmt.Println(i)
}
}for循环也可以只有逻辑判断部分:
func main() {
i := 1
for i < 10 {
fmt.Println(i)
i++
}
}这时候用起来就和while循环(其他语言的)差不多
还可以直接写没有退出条件的无限循环,这里就不演示了
顺便演示一下break语句
func main() {
i := 1
for {
fmt.Println(i)
i++
if i > 10 {
break
}
}
}for range键值循环
Go语言中可以使用for range遍历数组、切片、字符串、map及通道(channel)。通过forrange遍历的返回值有以下规律:
- 数组、切片、字符串返回索引和值。
map返回键和值。通道(channel)只返回通道内的值。
range 是 Go 语言内置的关键字,是 for 循环语法的一部分,专门用于构成“for-range”这种特殊的循环结构。
相关信息
range 不具备函数的任何特征:
不能独立调用:你不能写 values := range(mySlice)。它必须、也只能出现在 for 关键字之后。
没有括号:它的“参数”是直接跟在后面的表达式,没有 () 包裹。
不能作为值传递:你不能把它赋值给一个变量 fn := range,也不能把它作为参数传给另一个函数。
遍历字符串:
func main() {
s := "hello world"
for idx, c := range s {
fmt.Printf("[%d]-> %c\n", idx, c)
/*
[0]-> h
[1]-> e
[2]-> l
*/
}
}遍历数组:
func main() {
s := []string{"php", "go", "python", "java", "c", "c++", "c#", "javascript", "ruby", "perl", "lua", "shell"}
for idx, elem := range s {
fmt.Printf("[%d]-> %s\n", idx, elem)
/*
[0]-> php
[1]-> go
[2]-> python
*/
}
}switch-case多联分支结构
- Golang的
switch-case不需要给每个case分支末尾写上break,Golang会自己退出的
用拓展名后缀判断来演示:
func main() {
filename := "index.html"
filename_ext := strings.Split(filename, ".")[1]
switch filename_ext {
case "html":
fmt.Println("html文件")
case "css":
fmt.Println("css文件")
case "js":
fmt.Println("js文件")
default:
fmt.Println("未知文件")
}
// html文件
}switch后也可以不跟case变量,这时case分支每个都可以有自己独立的逻辑表达式:
import (
"fmt"
"strings"
)
func main() {
filename := "index.png"
filename_ext := strings.Split(filename, ".")[1]
file_mem := 128 // bytes
switch {
case filename_ext == "html":
fmt.Println("html文件")
case filename_ext == "css":
fmt.Println("css文件")
case filename_ext == "js":
fmt.Println("js文件")
case filename_ext == "png" && file_mem < 1024:
fmt.Println("小图片")
default:
fmt.Println("其他文件")
}
// 小图片
}switch的fallthrough
fallthrough关键字可以执行满足条件的case的下一个case——这是为了兼容C语言风味的switch-case: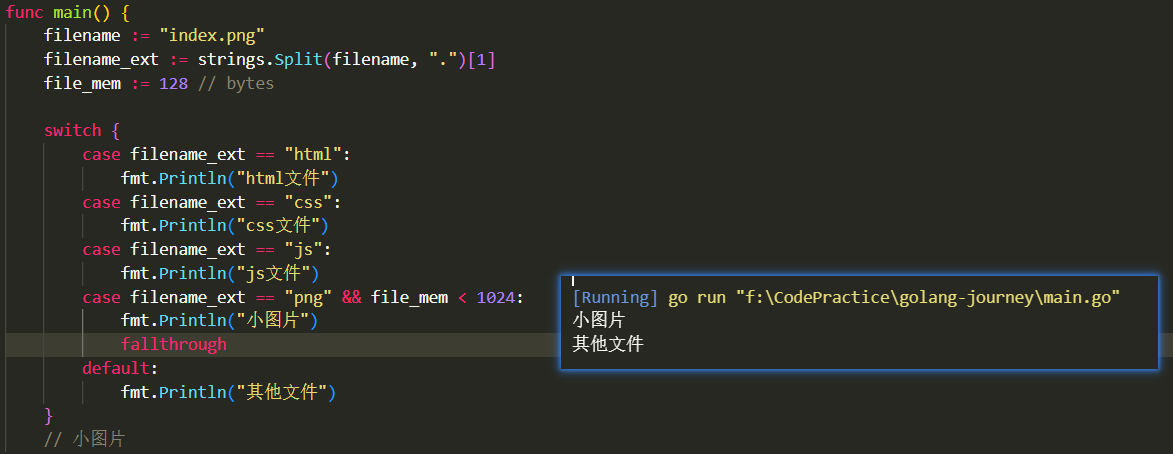
关键字大全
break
continue <label> // 标签是可选的; 在continue语句后添加标签时,表示开始标签对应的循环
goto <label> // ???
break <label> // Go风格的goto,直接中断某个标号的运算
defer // 确保函数退出前执行某些**清理**操作; 用于替代c语言中goto cleanup~的模goto……啊?
是的,Go 语言确实有 goto 关键字。 这在现代语言中几乎是异类,也是 Go 在设计上最引人争议、但同时也最能体现其设计哲学的特点之一。
Go goto 的核心限制:
- 不能跳过变量声明:你不能用 goto 跳过一个新变量的声明和初始化代码,这防止了使用未初始化变量的 bug。
- 作用域限制:goto 和它要跳转到的标签 (label) 必须在同一个函数内。你绝对不能用 goto 跳出当前函数。
这个第二点至关重要。它把 goto 可能造成的混乱,完全限制在了一个函数内部,确保了“意大利面条”最多只是一小碗,绝不会蔓延到整个项目。
在 99.9% 的情况下,你都不应该使用 goto。Go 提供了更优秀、更结构化的工具来解决几乎所有问题。
goto 在 Go 中仅存的、被社区勉强接受的合理用例,主要集中在一个场景:从深度嵌套的循环中一次性跳出。
break <label>
Go 还提供了一个更优雅、更结构化的工具,这才是 Go 的最佳实践:带标签的 break (Labeled Break)。
func main() {
i := 0
Loop:
for {
fmt.Println(i)
i++
if i > 10 {
break Loop // 跳出最外层循环(中断标号)
}
}
}三
复合数据类型
数组 array
var 变量名 []类型名 // 声明不定长数组(其实是切片)
var 变量名 [元素数量]类型名 // 声明定长数组
变量名 := []类型名{元素1, 元素2, 元素3, ...} // 编译器自动推导类型和分配内存
var 变量名 [...]类型名{元素1, 元素2, 元素3, ...} // 编译器自行分配内存和推断数组长度
变量名 = []类型名{元素1, 元素2, 元素3, ...} // 初始化数组示例:
func main() {
var arrayString []string
arrayString = []string{"php", "java", "go"}
for _, s := range arrayString {
fmt.Println(s)
}
}注意:数组的长度也是数组的一部分;长度必须是常量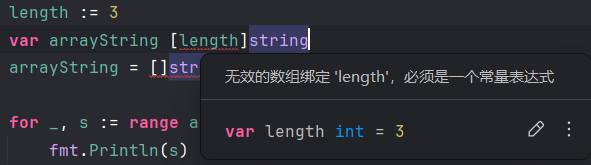
我嘞个不支持variable array
相关信息
Go 语言不但不提供 VLA,而且还提供了一个远比 VLA 更强大、更安全、更灵活的替代品:切片 (Slice)。
func myGoFunction(n int) {
// 这才是 Go 的方式!
mySlice := make([]int, n) // 在【堆 (Heap)】上分配一个大小为 n 的数组,并返回一个指向它的切片
}数组是可变类型,可以通过索引直接修改数组中的元素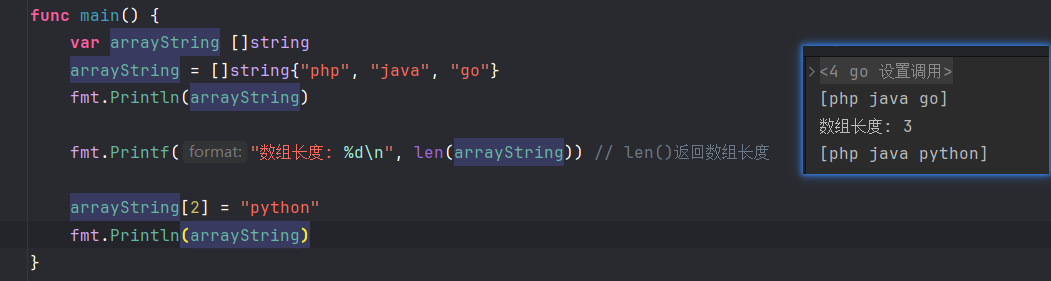
在初始化数组时,也可以直接对指定索引进行赋值:
变量名 := [...]类型名{下标: 元素x, 下标: 元素y, ...}未被赋值的元素则会赋上默认值——0
func main() {
a := []int{1: 1, 3: 5, 5: 7}
// [0 1 0 5 0 7]
fmt.Println(a)
}多维数组
var 变量名 [元素数量][元素数量]类型名可以套很多维
最外层数组的长度可以由编译器自行推断
var 变量名 [...][元素数量]类型名 = [...][元素数量]类型名{元素1, 元素2, ...}内层的话就不行
引用类型
基本数据类型 和 数组 都是值类型
相关信息
在 Go 中,所有变量的赋值和函数传参都永远是“按值传递” (pass-by-value) 的。永远。
值类型 (Value Types)的定义:
一个值类型的变量,其变量名直接持有数据的值。内存中,这个变量所占用的空间,就是存放数据本身的空间。
当你把一个值类型的变量赋给另一个变量,或者把它作为参数传递给一个函数时,Go 会完整地复制 (copy) 这个值,创建一个全新的、独立的副本。
至于 “引用类型” (Reference Types) ,一个所谓的“引用类型”变量,它本身并不直接持有数据。它持有的,是一个指向底层数据结构的指针或描述符。数据本身通常是在堆 (Heap) 上分配的。
当我们把一个引用类型的变量赋给另一个变量,或者传递给函数时,Go 依然是按值传递,但它复制的是这个指针或描述符,而不是底层那份庞大的数据。
常见的“引用类型”:
- 切片 (Slice):
[]int(最经典的例子) - 映射 (Map):
map[string]int - 通道 (Channel):
chan int - 指针 (Pointer):
*int - 函数 (Function):
func() - 接口 (Interface)
| 特性 | 值类型 (Value Types) | “引用类型” (Reference Types) |
|---|---|---|
| 变量持有的是... | 数据本身 | 指向底层数据的描述符/指针 |
| 赋值/传参时... | 完整复制数据,创建全新副本 | 复制描述符/指针,共享底层数据 |
| 修改副本/参数... | 不影响原始变量 | 会影响原始变量的底层数据 |
| 内存分配 | 通常在**栈 (Stack)**上 | 底层数据通常在**堆 (Heap)**上 |
| 典型代表 | int, string, struct, [n]T (数组) | []T (切片), map, chan, *T (指针) |
切片 slice
var name []T切片(Slice)是一个拥有相同类型元素的可变长度的序列。它是基于数组类型做的一层封装。它非常灵活,支持自动扩容。
切片是一个引用类型,它的内部结构包含地址、长度和容量。
确切地说,一个切片变量,实际上是一个小小的 struct,我们称之为切片头 (Slice Header),它包含三个部分:
- 一个指向底层数组的指针
- 切片的长度 (len)
- 切片的容量 (cap)
传递切片时实际上传递的是底层数组的指针,所以切片是引用类型
关于切片的声明和数组的声明长得一模一样这回事,需要多加小心:
- 数组 (Array):声明时,方括号内必须有一个明确的、非负的长度(常量或数字)。 这个长度是其类型的一部分。
- 切片 (Slice):声明时,方括号内是空的。
Go 的设计者们故意让它们的语法相似,因为切片的本质就是一个 “指向并管理一个底层数组片段的、更灵活的视图”
让我们用一个表格来对比这两者的“貌合神离”:
| 特性 | 数组 (Array) [N]T | 切片 (Slice) []T |
|---|---|---|
| 本质 | 值类型 (Value Type) | 引用类型 (Reference Type) |
| 长度 | 固定的 (Fixed)。长度 N 是其类型的一部分。 | 可变的 (Variable)。可以随时增长 (通过 append)。 |
| 类型身份 | [5]int 和 [10]int 是两种完全不同、互不兼容的类型。 | 任何 int 类型的切片,其类型都是 []int。 |
| 内存 | 直接持有数据。变量本身就是一块连续的内存。 | 持有对底层数组的引用。变量是一个包含【指针、长度、容量】的“描述符”。 |
| 函数传参 | 完整拷贝整个数组的数据。函数内修改不影响外部。 | 拷贝描述符。函数内修改会影响外部共享的底层数组。 |
| 灵活性 | 差。长度不可变。 | 极高。是 Go 语言中最常用、最强大的数据结构。 |
基于数组创建切片
func main() {
a := [4]string{"java", "go", "php", "python"} // 省略长度直接变切片的话也是可以的
slicedA := a[1:3]
fmt.Printf("%#v\n", a) // [4]string{"java", "go", "php", "python"}
fmt.Printf("%#v\n", slicedA) // []string{"go", "php"}
}还支持下面的切片:
slicedA := a[1:]
slicedA := a[:3]
slicedA := a[:] // 返回切片类型的整个数组切片的属性
长度len和容量cap
func main() {
a := []string{"java", "go", "php", "python"}
fmt.Printf("%#v的长度是%d,容量是%d\n", a, len(a), cap(a))
// []string{"java", "go", "php", "python"}的长度是4,容量是4
}对于从已有数组创建的切片,其len和cap行为略有差异: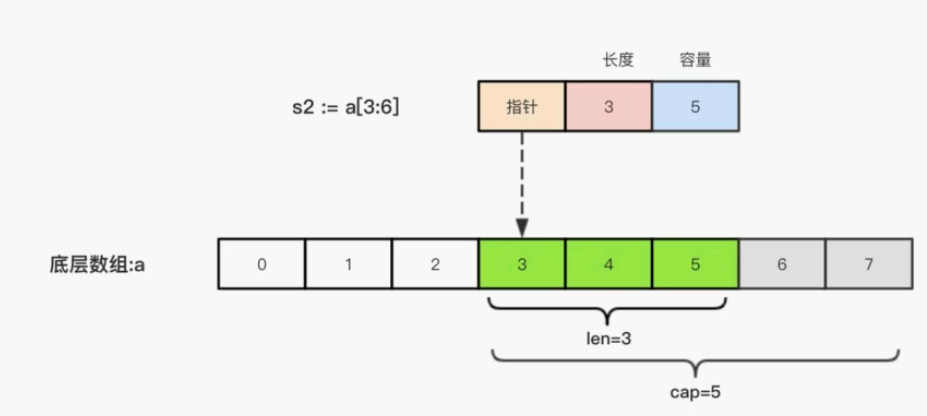
func main() {
a := []string{"java", "go", "php", "python"}
slicedA := a[1:3]
fmt.Printf("%#v的长度是%d,容量是%d\n", a, len(a), cap(a))
// []string{"java", "go", "php", "python"}的长度是4,容量是4
fmt.Printf("%#v的长度是%d,容量是%d\n", slicedA, len(slicedA), cap(slicedA))
// []string{"go", "php"}的长度是2,容量是3
}使用make函数安全地构造切片
上面的章节都是基于数组来创建的切片,如果需要动态的创建一个切片,我们就需要使用内置的make()函数
a := make([]Type, size, cap)Type:元素类型size:切片长的元素数量cap:切片容量
func main() {
a := make([]int, 4, 8)// 容量是8,但只能访问前4个元素
fmt.Printf("%#v\n", a)
// []int{0, 0, 0, 0}
}扩容策略
当 append 函数发现现有容量不足时,它需要计算一个新的容量。计算规则可以分为两个阶段:
- 当切片容量小于 256 时:新容量 = 旧容量 * 2
在切片还比较小的时候,Go 会采取非常激进的翻倍策略。- 旧容量 (oldCap): c
- 新容量 (newCap): 2 * c
- 当切片容量大于或等于 256 时:新容量 = 旧容量 * 1.25 (大约)
当切片变得很大时,再继续翻倍会造成巨大的内存浪费。例如,一个 1GB 的切片翻倍就会立刻变成 2GB。为了避免这种情况,Go 的策略变得更加保守。
它会反复地给旧容量增加 25% (即 oldCap / 4),直到新容量足够大为止。- 旧容量 (oldCap): c
- 新容量 (newCap): c + c/4 (循环此操作)
重要
- 最终容量的内存对齐:上面计算出的新容量只是一个目标值。Go 的内存分配器为了效率,会从一些预设的“尺寸类 (size classes)”中选择一个最接近且不小于目标值的尺寸。所以你最终得到的实际容量,可能会比计算出的值稍大一点,以便进行内存对齐。
append(slice1, slice2...)的特殊情况:
正如我们之前讨论的,当你一次性 append 多个元素时,Go 不会傻傻地进行多次扩容。它会先计算出最终需要的最小长度(len(slice1) + len(slice2)),然后拿这个目标长度去和现有容量 cap(slice1) 比较。- 如果容量足够,就在原地操作。
- 如果容量不足,它会用上面的扩容算法计算出一个至少能容纳下所有新元素的新容量,然后只进行一次内存分配和拷贝。
如果你能预估一个切片最终大概会有多大,请在创建时就用 make 函数预分配足够的容量!
切片的操作
切片扩容
Golang中无法通过下标访问切片长度之外的元素:
这时需要使用append函数来为切片扩容(并返回指向新切片的指针):
func main() {
a := make([]int, 4, 8) // 长度4, 容量8
for i := 0; i < len(a); i++ {
a[i] = 1 << i
}
// 接下来使用append继续扩容
for i := len(a); i < cap(a); i++ {
a = append(a, 1<<i)
}
fmt.Printf("%#v\n", a)
// []int{1, 2, 4, 8, 16, 32, 64, 128}
}根据append函数文档,当新加入的元素未超过切片容量时,append函数只会增加切片长度,反之则会隐式创建新的切片,最后都会返回切片指针append函数本身不会改变传入的切片的内容(或者说切片本身不存储底层数组的内容,只存储数组指针),所以必须显式更新切片变量
当切片容量足够的时候,切片的append操作不会创建新的数组——当切片是由数组或切片进行slice操作得到的时候,对这个切片进行append会污染原数组:
func main() {
a := make([]int, 4, 8) // 长度4, 容量8
for i := 0; i < len(a); i++ {
a[i] = 1 << i
}
// 接下来使用append继续扩容
for i := len(a); i < cap(a); i++ {
a = append(a, 1<<i)
}
fmt.Printf("%#v\n", a)
// []int{1, 2, 4, 8, 16, 32, 64, 128}
slicedA := a[3:5]
_ = append(slicedA, 251)
fmt.Printf("%#v\n", a)
// []int{1, 2, 4, 8, 16, 251, 64, 128}
// 这里污染了原数组a
}切片复制
func copy(dst []Type, src []Type) int
The copy built-in function copies elements from a source slice into a destination slice. (As a special case, it also will copy bytes from a string to a slice of bytes.) The source and destination may overlap. Copy returns the number of elements copied, which will be the minimum of len(src) and len(dst).
从切片中删除元素
Golang本身并没有从切片中删除元素的方法。可以使用切片自身的特性来删除元素
切片+append:
func main() {
a := make([]int, 4, 8) // 长度4, 容量8
for i := 0; i < len(a); i++ {
a[i] = 1 << i
}
// 接下来使用append继续扩容
for i := len(a); i < cap(a); i++ {
a = append(a, 1<<i)
}
fmt.Printf("%#v\n", a)
// 删除下标为2的元素
slicedA := append(a[:2], a[3:]...)
fmt.Printf("%#v\n", slicedA)
// []int{1, 2, 8, 16, 32, 64, 128}
}注意把...放在切片后面来展开切片
切片排序:Golang内置sort包
sort升序排序
sort默认按升序排序
func main() {
intA := []int{1245, 44, 487, 78, 49, 747}
float64A := []float64{1.2456, 2.5854, 48.2, 45.2, 4.132}
stringA := []string{"php", "java", "moonbit", "go"}
// sort默认升序排序
// 对int数组的排序
sort.Ints(intA) // 没有返回值
fmt.Println(intA) // [44 49 78 487 747 1245]
// 对float64数组的排序
sort.Float64s(float64A)
fmt.Println(float64A) // [1.2456 2.5854 4.132 45.2 48.2]
// 对string数组的排序
sort.Strings(stringA)
fmt.Println(stringA) // [go java moonbit php] // 疑似按首字符码值排序
}注意:Ints函数没有返回值
sort降序排序
使用Reverse函数来反转切片,配合Ints等方法就可以实现降序排序
func main() {
intA := []int{1245, 44, 487, 78, 49, 747}
float64A := []float64{1.2456, 2.5854, 48.2, 45.2, 4.132}
stringA := []string{"php", "java", "moonbit", "go"}
// Reverse+sort降序排序
// 对int数组的排序
sort.Sort(sort.Reverse(sort.IntSlice(intA))) // [1245 747 487 78 49 44]
fmt.Println(intA)
// 对float64数组的排序
sort.Sort(sort.Reverse(sort.Float64Slice(float64A))) // [48.2 45.2 4.132 2.5854 1.2456]
fmt.Println(float64A)
// 对string数组的排序
sort.Sort(sort.Reverse(sort.StringSlice(stringA))) // [php moonbit java go]
fmt.Println(stringA)
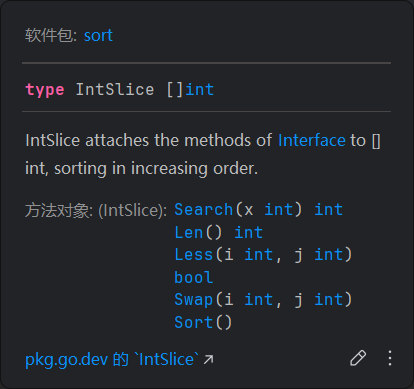
}注意Sort方法接受的是sort Interface,一个封装了数组长度、元素交换方法和元素排序方法的结构体;而IntSlice系列方法做的就是把传入的数组属性贴到sort Interface后面,再返回这个接口,供sort的其他通用方法使用
type Interface interface {
Len() int // 1. 你有多长?
Less(i, j int) bool // 2. 索引 i 的元素是否应该排在索引 j 的元素前面?
Swap(i, j int) // 3. 如何交换索引 i 和 j 的元素?
}
键值对 map
map是一种无序的键值对结构,是引用类型,必须初始化 才能使用
map[KeyType]ValueTypemap的默认值为nil,需要make函数来帮助分配内存
make(map[KeyType]ValueType, cap)
// make函数还可用于slice、channel的内存分配func main() {
userInfo := make(map[string]string, 8)
userInfo["username"] = "MemorySeer"
fmt.Printf("%T -> %#v\n", userInfo, userInfo)
}map也支持在声明时进行(部分)初始化
func main() {
// 可以土法var
userInfo := map[string]string{
"username": `MemorySeer`, // 即使只有一个键值对也必须在末尾写上逗号
}
fmt.Printf("键值对内容为: %v, \n", userInfo)
// 键值对内容为: map[username:MemorySeer], }使用for k,v := range map[Key]Value遍历键值对:
func main() {
userInfo := map[string]string{
"username": `MemorySeer`,
"age": `20`,
"sex": `female`,
}
// 遍历键值对
for k, v := range userInfo {
fmt.Printf("%v -> %v\n", k, v)
}
}使用k,v := map["key"]来判断指定键在map中是否存在:
func main() {
userInfo := map[string]string{
"username": `MemorySeer`,
"age": `20`,
"sex": `female`,
}
v, isExisted := userInfo["username"]
fmt.Println(v, " ", isExisted) // MemorySeer true
v, isExisted = userInfo["nickname"]
fmt.Printf("[%v] %v\n", v, isExisted) // [] false
}也可以选择不接收键是否存在的布尔值
Golang的错误处理哲学
| 特性 | error 范式 ((value, error)) | comma, ok 范式 ((value, bool)) |
|---|---|---|
| 解决的问题 | 操作失败 (Operational Failure) | 存在性查询 (Existence Check) |
| 语义 | “出错了,这是错误信息。” | “没找到,这是个正常结果。” |
| 返回类型 | error 接口(丰富信息) | bool(简单信号) |
| 核心提问 | “操作成功了吗?” | “东西在吗?” |
| 典型场景 | 文件 I/O, 网络请求, 数据解析 | map 访问, 通道接收, 类型断言 |
使用delete(map[KeyType]ValueType, key)函数从键值对中删除对象
func main() {
userInfo := map[string]string{
"username": `MemorySeer`,
"age": `20`,
"sex": `female`,
}
key := "sex"
_, isExisted := userInfo[key]
fmt.Printf("key \"%v\" exists? %v!\n", key, isExisted) // key "sex" exists? true!
delete(userInfo, key)
_, isExisted = userInfo[key] // 更新flag
fmt.Printf("key \"%v\" exists? %v!\n", key, isExisted) // key "sex" exists? false!
}复合类型:键值对数组
记得使用type定义类型别名,不要到处拉shi随地中括号乱扔
func main() {
type userInfoType map[string]string // 定义类型别名, 弄一坨在这里
users := make([]userInfoType, 3)
usernames := []string{"Alice", "Bob", "Freeman"}
ages := []string{"18", "20", "19"}
for idx, userInfo := range users {
if userInfo == nil {
users[idx] = userInfoType{
"index": strconv.Itoa(idx + 1),
"username": usernames[idx],
"age": ages[idx],
}
}
}
fmt.Println(users)
// [map[age:18 index:1 username:Alice] map[age:20 index:2 username:Bob] map[age:19 index:3 username:Freeman]]
}复合类型:切片键值对
func main() {
type userInfoColumn = []string // 不小心写多一个等于号,但是也能跑
userInfoTable := make(map[string]userInfoColumn, 3)
userInfoTable["username"] = []string{"Alice", "Bob", "Freeman"}
userInfoTable["age"] = []string{"18", "20", "19"}
userInfoTable["sex"] = []string{"male", "female", "female"}
fmt.Println(userInfoTable)
// map[age:[18 20 19] sex:[male female female] username:[Alice Bob Freeman]]
}注
这里不小心使用的 type userInfoColumn = []string 语法,是 Go 语言中的【类型别名 (Type Alias)】。
而上一个标题使用的是更常用的 type userInfoType map[string]string ,【类型定义 (Type Definition)】。
“那我到底该用哪个?” —— 99% 的情况用【类型定义】
| 特性 | 类型定义 (Type Definition) type T U | 类型别名 (Type Alias) type T = U |
|---|---|---|
| 本质 | 创建一个全新的类型 | 给一个已有类型起个新名字 |
| 类型身份 | T 和 U 是不同类型 | T 和 U 是同一类型 |
| 赋值 | 需要显式类型转换 T(u) | 可以直接赋值 |
| 定义方法 | 可以为新类型 T 定义方法 | 不可以为别名 T 单独定义方法 |
| 常用场景 | 默认选择! 用于抽象、封装和增强代码可读性 | 极少数情况,主要用于大型代码库的重构 |
nil
当你声明了一个变量,但却还并没有赋值时,golang中会自动给你的变量赋值一个默认零值。这是每种类型对应的零值。
值类型的零值是0、0.0、false和[];引用类型的零值全是nil
func main() {
var a []int
fmt.Printf("( %T )%#v (%v)\n", a, a, a)
// []int []int(nil) []
}