Golang学习笔记(五):协程与并发
参考资料
- Go中文文档
- Gemini 2.5 Flash
Goroutine(一):初入门道
协程之所以叫协程 (AI)
“协程 (Coroutine)”这个名字,可以拆解为“Co-” + “Routine”,意思是【协同式 (Cooperative) 的子程序 (Routine)】。
它的核心灵魂就在于“协同 (Cooperative)”这两个字。
1. 与“线程 (Thread)”的对立:谁是老大?
要理解“协程”,最好的方式就是把它和我们更熟悉的“线程 (Thread)”放在一起对比。它们最大的区别在于控制权 (Control) 的交接方式。
线程 (Thread):抢占式 (Preemptive) 的霸道总裁
- 谁是老大?:操作系统内核 (OS Kernel) 是老大。
- 工作方式:你可以创建多个线程,然后把它们都交给操作系统。操作系统内核有一个调度器 (Scheduler),它拥有绝对的权力。
- 调度器会根据一套复杂的算法(比如时间片轮转),运行一个线程一小段时间(比如 10 毫秒),然后不管这个线程乐不乐意,直接强行(抢占) 把它暂停,把它踢下 CPU,然后换另一个线程上来跑。
- 比喻:想象一群霸道的总裁在开会。每个人都在抢着发言,主持人(操作系统)每隔一分钟就敲一下槌子,强行打断当前发言的人,让下一个人说。谁也无法控制自己什么时候被“闭麦”。
协程 (Coroutine):协同式 (Cooperative) 的谦谦君子
- 谁是老大?:协程自己(或者说,用户态的调度器)是老大。
- 工作方式:一个协程启动后,它会一直运行,直到它自己决定要暂停并把控制权主动让出 (yield) 给其他协程。
- 它让出控制权的典型时机是:当它需要等待一个 I/O 操作时(比如读网络、写文件),或者它主动调用一个
yield函数时。 - 比喻:想象一群非常有礼貌的君子在开会。A 发言,直到他说到“我的观点暂时说完了,B 你来说吧”,然后他主动坐下,把发言权交给 B。B 说完,再主动交给 C。每个人都在互相协作,主动出让控制权。
2. “协程”这个名字的历史
这个概念其实非常古老,比线程还要早,由 Melvin Conway 在 1958 年提出。它的核心思想就是:一种可以暂停 (suspend) 和恢复 (resume) 执行的子程序。
- Routine (子程序):就是我们常说的函数或过程。
- Co (协同):强调了这些子程序之间是平等协作的关系,而不是像主函数调用子函数那样的“主从”关系。它们可以互相“激活”对方。
3. Go 的 Goroutine:一个“被解放”的协程
现在,我们终于来到了 Go 的 Goroutine。
Go 的 Goroutine 在概念上是一个协程,但它比传统的协程要强大得多,也更容易使用。 你可以把它看作是一个被 Go 运行时 (Go Runtime) 深度优化和赋能了的、更高层次的协程。
传统协程的痛点:
- 在很多语言里(比如早期的 Python
yield),你需要手动管理控制权的交接。你需要明确地在代码里写yield来让出 CPU。
Go 的 Goroutine 的魔法:
- 你【不需要】手动
yield! - Go 语言的运行时调度器 (Runtime Scheduler) 帮你做了这一切。
- 当你发起一个阻塞的系统调用(比如网络 I/O
net.Read)时,Go 的调度器会自动地:- 把当前的 Goroutine 置为“等待”状态。
- 把它从它所在的**操作系统线程 (M)**上“摘下来”。
- 从等待队列里,找一个已经准备好运行的其他 Goroutine。
- 把这个新的 Goroutine 放到这个操作系统线程 (M) 上去运行。
- 这一切对你是完全透明的! 你写的代码看起来就像是普通的同步阻塞代码,但 Go 的运行时在底层帮你实现了非阻塞的、高效的调度。
所以,Goroutine = 协程的轻量级 + 操作系统线程的抢占式调度的【融合体】。
它既有协程那种极其轻量、切换开销极低的优点,又通过强大的运行时,让你摆脱了手动 yield 的心智负担,获得了类似“抢占式”的编程体验。
给你的印象总结:
- “协”= 协同/协作:这是精髓。协程是主动让出控制权。
- Goroutine 是“智能”协程:Go 运行时为你代劳了“主动让出”这个动作,让你的代码看起来是同步的,但实际上是异步、非阻塞的。
- 极度轻量:把 Goroutine 想象成“代码执行的最小单元”,你可以毫不吝啬地创建它们,就像调用函数一样随意。
带着“协同”和“轻量”这两个核心印象去学习接下来的内容,你会发现 Go 的并发模型是如此地优雅和强大。
Gorountine与sync.WaitGroup
古人言:通过通信来共享内存,而不是共享内存来通信
使用Goroutine
goroutine的概念类似于线程,但 goroutine是由Go的运行时(runtime)调度和管理的。Go程序会智能地将 goroutine 中的任务合理地分配给每个CPU。Go语言之所以被称为现代化的编程语言,就是因为它在语言层面已经内置了调度和上下文切换的机制。
Go语言中使用goroutine非常简单,只需要在调用函数的时候在前面加上go关键字,就可以为一个函数创建一个goroutine。
一个goroutine必定对应一个函数,可以创建多个goroutine去执行相同的函数。
import (
"fmt"
"golang-journey/logging" "time")
func tickDemo(tag any) {
ticker := time.Tick(time.Second * 5) // 间隔5秒
logging.Info(fmt.Sprintf("协程 %v 正在运行", tag))
for i := range ticker {
logging.Info(fmt.Sprintf("协程 %v 正在运行", tag))
if i.Second() >= 25 { // 运行25秒后结束
logging.Info(fmt.Sprintf("协程 %v 结束运行", tag))
break
}
}
}
func main() {
go tickDemo(1)
time.Sleep(time.Second * 3) // 延时3秒
go tickDemo(2)
time.Sleep(time.Second * 30) // 延时1分钟再退出程序
}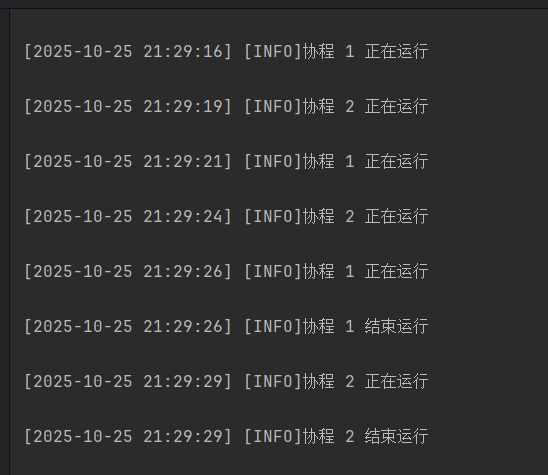
最后面的time.Sleep(time.Second * 30)是用来卡住主进程,让程序不要那么快退出的——主进程可不管你协程有没有跑完
使用sync.WaitGroup等待协程执行
可以用sync.WaitGroup来等待协程执行完毕
var wg sync.WaitGroup
func tickDemo(tag any) {
ticker := time.Tick(time.Second * 5) // 间隔5秒
logging.Info(fmt.Sprintf("协程 %v 正在运行, 已运行1次", tag))
for i := range ticker {
logging.Info(fmt.Sprintf("协程 %v 正在运行, 已运行%v次", tag, (i.Second()/5)+1))
if i.Second() >= 25 { // 运行25秒后结束
logging.Info(fmt.Sprintf("协程 %v 结束运行", tag))
break
}
}
wg.Done() // 释放协程, 计数器减1
}
func main() {
wg.Add(0) // 协程计数器+1
go tickDemo(1)
time.Sleep(time.Second * 3) // 延时3秒
wg.Add(2) // 协程计数器+1 // 合起来我直接加个2
go tickDemo(2)
wg.Wait() // 等待所有协程结束
}
// [2025-10-25 21:39:18] [INFO]协程 1 正在运行, 已运行1次
// [2025-10-25 21:39:21] [INFO]协程 2 正在运行, 已运行1次
// [2025-10-25 21:39:23] [INFO]协程 1 正在运行, 已运行5次
// [2025-10-25 21:39:26] [INFO]协程 2 正在运行, 已运行6次
// [2025-10-25 21:39:26] [INFO]协程 2 结束运行
// [2025-10-25 21:39:28] [INFO]协程 1 正在运行, 已运行6次
// [2025-10-25 21:39:28] [INFO]协程 1 结束运行wg.Add接受一个int参数,表示要添加多少个协程——我直接加2个,反正第二个协程启动时,协程一还没跑完
Goroutine调度机制
介绍(转载自网络文档)
GPM是Go语言运行时(runtime)层面的实现,是go语言自己实现的一套调度系统。区别于操作系统调度OS线程。
- 1.G很好理解,就是个goroutine的,里面除了存放本goroutine信息外 还有与所在P的绑定等信息。
- 2.P管理着一组goroutine队列,P里面会存储当前goroutine运行的上下文环境(函数指针,堆栈地址及地址边界),P会对自己管理的goroutine队列做一些调度(比如把占用CPU时间较长的goroutine暂停、运行后续的goroutine等等)当自己的队列消费完了就去全局队列里取,如果全局队列里也消费完了会去其他P的队列里抢任务。
- 3.M(machine)是Go运行时(runtime)对操作系统内核线程的虚拟, M与内核线程一般是一一映射的关系, 一个groutine最终是要放到M上执行的;
P与M一般也是一一对应的。他们关系是: P管理着一组G挂载在M上运行。当一个G长久阻塞在一个M上时,runtime会新建一个M,阻塞G所在的P会把其他的G 挂载在新建的M上。当旧的G阻塞完成或者认为其已经死掉时 回收旧的M。
P的个数是通过runtime.GOMAXPROCS设定(最大256),Go1.5版本之后默认为物理线程数。 在并发量大的时候会增加一些P和M,但不会太多,切换太频繁的话得不偿失。
单从线程调度讲,Go语言相比起其他语言的优势在于OS线程是由OS内核来调度的,goroutine则是由Go运行时(runtime)自己的调度器调度的,这个调度器使用一个称为m:n调度的技术(复用/调度m个goroutine到n个OS线程)。 其一大特点是goroutine的调度是在用户态下完成的, 不涉及内核态与用户态之间的频繁切换,包括内存的分配与释放,都是在用户态维护着一块大的内存池, 不直接调用系统的malloc函数(除非内存池需要改变),成本比调度OS线程低很多。 另一方面充分利用了多核的硬件资源,近似的把若干goroutine均分在物理线程上, 再加上本身goroutine的超轻量,以上种种保证了go调度方面的性能。
设置Golang并行时占用的CPU数量
可以通过runtime.GOMAXPROCS()函数设置当前程序并发时占用的CPU逻辑核心数
Go 1.5及以前,默认使用的是单核心执行;Go 1.5+默认使用全部的CPU逻辑核心
func main() {
maxProcs := runtime.GOMAXPROCS(0) // 参数小于1时不修改最大核心数
fmt.Println("maxProcs:", maxProcs)
// maxProcs: 12 八大核四小核
}Goroutine(二):拥抱Channel
失败的测试代码:
package main
import (
"fmt"
"sync")
var wg sync.WaitGroup
func isPrime(n int) bool {
if n == 2 || n == 3 || n == 5 || n == 7 || n == 11 {
return true
}
for i := 2; i < n; i++ {
if n%2 == 0 || n%3 == 0 || n%5 == 0 || n%7 == 0 || n%11 == 0 {
// 提前过滤一批因子为质数的参数
return false
} else if n%i == 0 { // 再接着后面的遍历
return false
}
}
return true
}
func isPrimeChannel(in chan int, out chan int) { // chan在函数传参中应当写明通道方向
for {
n, ok := <-in
if !ok { // 通道关闭时退出循环
break
}
if isPrime(n) {
out <- n
}
}
wg.Done()
}
func printPrime(outNum chan int) {
for {
n, ok := <-outNum
if !ok { // 通道关闭时退出循环
break
}
fmt.Printf("%d\n", n)
}
wg.Done()
}
func main() {
inNum := make(chan int, 16) // 创建容量为16的整型双向有缓冲通道
outNum := make(chan int, 32)
threads := 16
for i := 0; i < threads; i++ {
wg.Add(2) // 一次创建两个协程, 攻击创建32个协程
go isPrimeChannel(inNum, outNum) // 启动协程
go printPrime(outNum)
}
for i := 10; i < 100; i++ {
inNum <- i
}
close(inNum) // 先关闭写通道
close(outNum) // 再关闭读通道
wg.Wait() // 等待派发出去的协程执行完成
}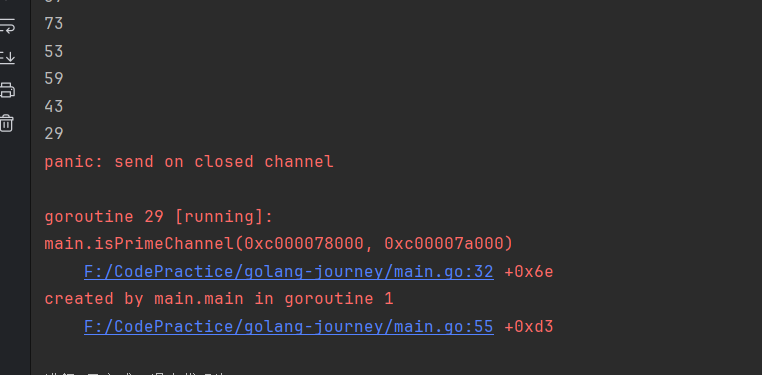
每次都会有几个协程被落下
参照AI代码改好了
package main
import (
"fmt"
"golang-journey/logging" "sync")
var wg sync.WaitGroup
func isPrime(n int) bool {
if n == 2 || n == 3 || n == 5 || n == 7 || n == 11 {
return true
}
for i := 2; i < n; i++ {
if n%2 == 0 || n%3 == 0 || n%5 == 0 || n%7 == 0 || n%11 == 0 {
// 提前过滤一批因子为质数的参数
return false
} else if n%i == 0 { // 再接着后面的遍历
return false
}
}
return true
}
func isPrimeChannel(id int, in <-chan int, out chan<- int, wg *sync.WaitGroup) { // chan在函数传参中应当写明通道方向
defer wg.Done()
logging.Info(fmt.Sprintf("isPrimeChannel %d started", id))
for n := range in { // for ... range可以自动处理通道关闭的情况
if isPrime(n) {
out <- n
}
}
logging.Info(fmt.Sprintf("isPrimeChannel %d finished", id))
}
func printPrime(outNum chan int) {
for n := range outNum {
fmt.Println(n)
}
wg.Done()
}
func main() {
inNum := make(chan int, 128) // 创建整型双向有缓冲通道
outNum := make(chan int, 128)
// 分离协程锁
calculatorWG, printerWG := &sync.WaitGroup{}, &sync.WaitGroup{}
// 启动计算协程并配置读写通道
numCalculators := 4
calculatorWG.Add(numCalculators) // 协程计数器+4
for i := 0; i < numCalculators; i++ {
go isPrimeChannel(i, inNum, outNum, calculatorWG)
}
// 再用一个协程管理计算协程
go func() {
calculatorWG.Wait()
close(outNum) // 让消费者关闭通道
}()
// 启动打印协程, 只开一个就够了
printerWG.Add(1)
go func() {
defer printerWG.Done()
for prime := range outNum {
fmt.Printf("Prime: %d\n", prime)
}
}()
// 发送数字
for i := 2; i < 100; i++ {
inNum <- i
}
close(inNum) // 发送完就可以关闭了(关闭的是写操作, 读还是能读出来的)
printerWG.Wait() // 等待打印协程结束
logging.Info("All done")
}通道channel
var ch make(chan <Type>, cap)chan <Type>:通道具体存储什么类型;存整型的就叫chan intcap:缓冲容量;不写的话得到的通道就是无缓冲通道,必须有读有写——光读不写会在执行时抛出panic
上面得到的通道是双向通道,既可读也可写——通道为空时进行接收操作会阻塞,通道为满时进行发送操作会阻塞,Go调度器会自动调度阻塞协程和就绪协程
也可以定义单向通道,双向通道能当单向通道用,反过来就不行:
var in make(<-chan <Type>, cap)
var out make(chan<- <Type>, cap)(在函数传参里也是这么写类型)
通道有三种操作:
- 发送:
ch <- 3 - 接收:
a <- ch:可以不接受值,写作<- ch;这个操作本身也是双返回值操作,可以选择忽略第二个值(也是个布尔值,表示通道是否为空) - 关闭(写操作):
close(ch);只是关闭了写操作,通道本身并没有被关闭,仍然可以读取(如果这是一个双向通道的话)
关于关闭通道需要注意的事情是,只有在通知接收方goroutine所有的数据都发送完毕的时候才需要关闭通道。通道是可以被垃圾回收机制回收的,它和关闭文件是不一样的,在结束操作之后关闭文件是必须要做的,但关闭通道不是必须的。
关闭后的通道有以下特点:
- 对一个关闭的通道再发送值就会导致panic。
- 对一个关闭的通道进行接收会一直获取值直到通道为空。
- 对一个关闭的并且没有值的通道执行接收操作会得到对应类型的零值。
- 关闭一个已经关闭的通道会导致panic。
可以使用for ... range结构遍历处理通道,结构会自动处理通道为空且关闭的情况(退出循环)
使用须知
通道是FIFO队列
func main() {
ch := make(chan int, 5)
ch <- 31
ch <- 63
ch <- 127
fmt.Printf("%#v 长度为%v 容量为%v\n", ch, len(ch), cap(ch))
// (chan int)(0xc0000a6000) 长度为3 容量为5
fmt.Println(<-ch) // 31
fmt.Println(<-ch) // 63
fmt.Println(<-ch) // 127
close(ch)
}同步通道的死锁问题
给无缓冲通道只写不读,回收的时候会触发deadlock: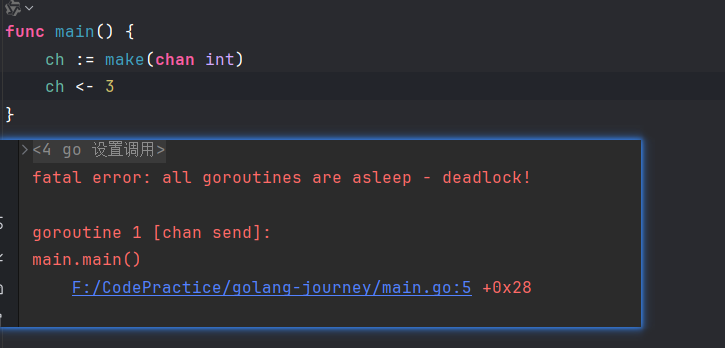
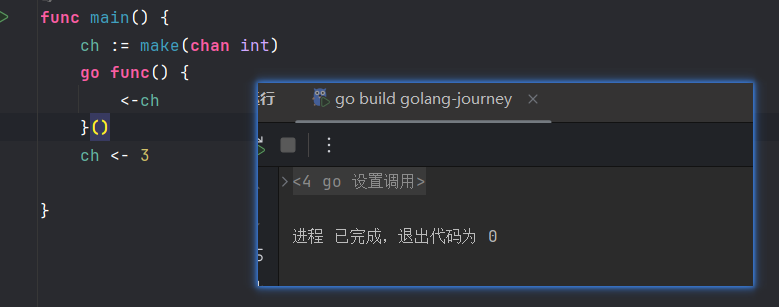
无缓冲通道要同步读写,所以也可以叫同步通道——这里匿名函数没读到值的时候会进入阻塞状态,直到ch写入值
无缓冲通道上的发送操作会阻塞,直到另一个goroutine在该通道上执行接收操作,这时值才能发送成功,两个goroutine将继续执行。相反,如果接收操作先执行,接收方的goroutine将阻塞,直到另一个goroutine在该通道上发送一个值。
有缓冲通道可以只写不读
func main() {
ch := make(chan int, 1)
ch <- 3
logging.Info("发送成功")
// [2025-10-25 23:07:00] [INFO]发送成功
}”出入关门“
通过内置的close()函数关闭channel(如果你的管道不往里存值或者取值的时候一定记得关闭管道)
- 这个操作只是关闭了写操作 ,不会影响读操作
遍历通道
使用for ... range遍历通道,当通道关闭后会自动退出循环
单向通道
有的时候我们会将通道作为参数在多个任务函数间传递,很多时候我们在不同的任务函数中使用通道都会对其进行限制,比如限制通道在函数中只能发送或只能接收。
总结
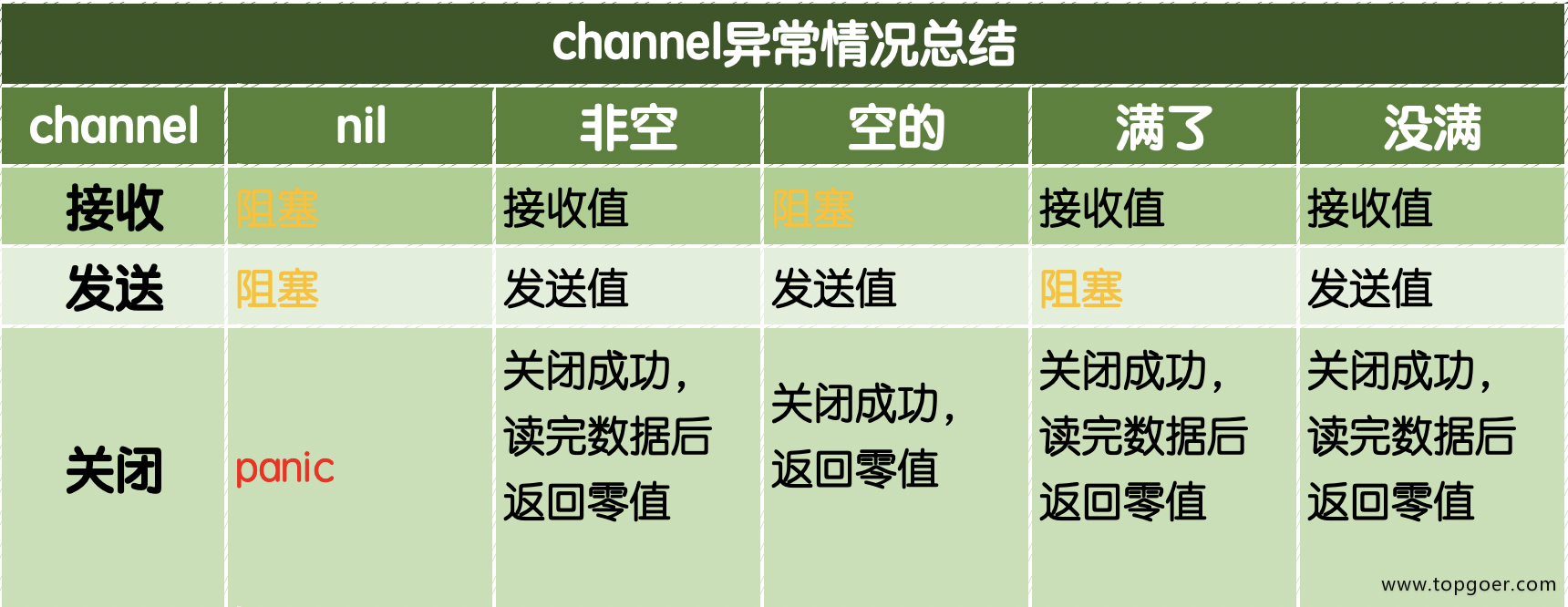
注意
关闭已经关闭的channel也会引发panic。
Goroutine与Channel(三):select多路复用和panic处理
select ... case结构
在某些场景下我们需要同时从多个通道接收数据。通道在接收数据时,如果没有数据可以接收将会发生阻塞。
过多的阻塞会影响性能。为了应对这种场景,Go内置了select关键字,可以同时响应多个通道的操作。
select的使用类似于switch语句,它有一系列case分支和一个默认的分支。每个case会对应一个通道的通信(接收或发送)过程。select会一直等待,直到某个case的通信操作完成时,就会执行case分支对应的语句。具体格式如下:
select {
case <-chan1:
// 如果chan1成功读到数据,则进行该case处理语句
case chan2 <- 1:
// 如果成功向chan2写入数据,则进行该case处理语句
default:
// 如果上面都没有成功,则进入default处理流程
}select可以同时监听一个或多个channel,直到其中一个channel ready
示例:监听两个通道,看看哪个通道先得到数据;不用写default,写了立马进default分支
func test(tag any, ch chan string) {
a := ((rand.Int() % 5) + 1) * 20
logging.Info(fmt.Sprintf("协程 %v 准备执行, 延迟 %v 豪秒", tag, a))
time.Sleep(time.Duration(int(time.Millisecond) * a)) // 随机延迟 1~5 秒
ch <- fmt.Sprintf("协程 %v 执行完毕", tag)
wg.Done()
}
func main() {
ch1 := make(chan string, 2)
ch2 := make(chan string, 2)
wg.Add(2)
go test(1, ch1)
go test(2, ch2)
select {
case msg := <-ch1:
fmt.Printf("接收到消息: %v\n", msg)
case msg := <-ch2:
fmt.Printf("接收到消息: %v\n", msg)
}
// [2025-10-25 23:51:19] [INFO]协程 2 准备执行, 延迟 100 豪秒
// [2025-10-25 23:51:19] [INFO]协程 1 准备执行, 延迟 80 豪秒
// 接收到消息: 协程 1 执行完毕
// wg.Wait()
}- 使用
select来获取channel里面的数据时不需要关闭通道(因为通道为空时读取操作会被阻塞) - 如果两个通道同时跑完,那么随机选一个执行
下面的例子(转载)则演示了如何轮询检查通道是否为满:
package main
import (
"fmt"
"time"
)
// 判断管道有没有存满
func main() {
// 创建管道
output1 := make(chan string, 10)
// 子协程写数据
go write(output1)
// 取数据
for s := range output1 {
fmt.Println("res:", s)
time.Sleep(time.Second)
}
}
func write(ch chan string) {
for {
select {
// 写数据
case ch <- "hello":
fmt.Println("write hello")
default:
fmt.Println("channel full")
}
time.Sleep(time.Millisecond * 500)
}
}Goroutine(四):Lock锁
情境引入
下面的程序会开启两个协程,同时对一个全局变量进行递增操作——必然导致状态竞争事故:
var x int64 = 0
var wg sync.WaitGroup
func increase() {
for i := 0; i < 5000; i++ {
x++
fmt.Printf("[%v] %v\n", i+1, x)
}
wg.Done()
}
func main() {
wg.Add(2)
go increase()
go increase()
wg.Wait()
}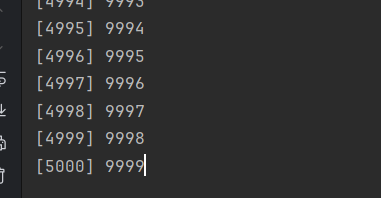
加了5000*2次才到9999
锁
互斥锁 sync.Mutex
互斥锁是一种常用的控制共享资源访问的方法,它能够保证同时只有一个goroutine可以访问共享资源。Go语言中使用sync包的Mutex类型来实现互斥锁。 使用互斥锁来修复上面代码的问题:
var x int64 = 0
var wg sync.WaitGroup
var lock sync.Mutex // 互斥锁
func increase() {
for i := 0; i < 5000; i++ {
lock.Lock()
x++
lock.Unlock() // 迭代完就解锁
fmt.Printf("[%v] %v\n", i+1, x)
}
wg.Done()
}
func main() {
wg.Add(2)
go increase()
go increase()
wg.Wait()
}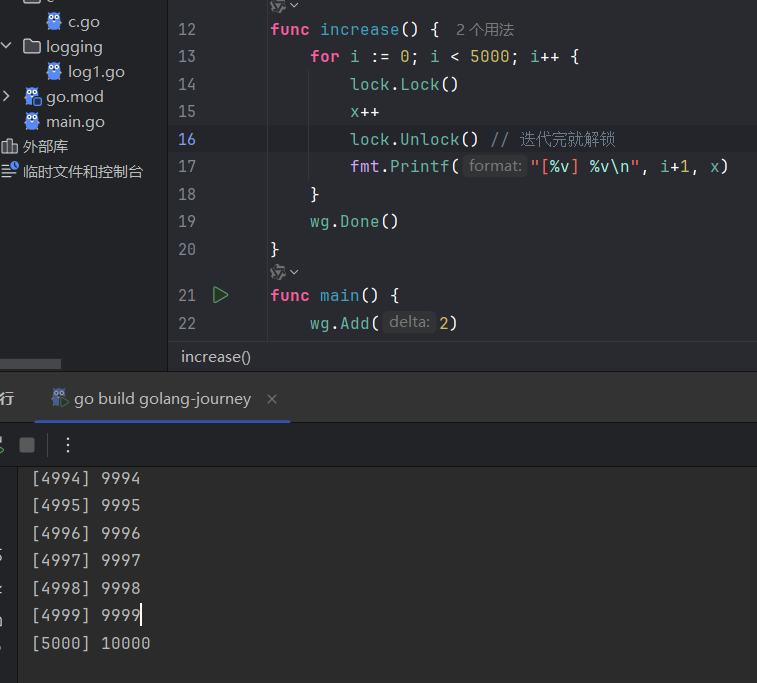
虽然执行顺序还是乱的,但至少算对了
读写互斥锁 sync.RWMutex
互斥锁是完全互斥的,但是有很多实际的场景下是读多写少的,当我们并发的去读取一个资源不涉及资源修改的时候是没有必要加锁的,这种场景下使用读写锁是更好的一种选择。读写锁在Go语言中使用sync包中的RWMutex类型。
读写锁分为两种:读锁和写锁。当一个goroutine获取读锁之后,其他的goroutine如果是获取读锁会继续获得锁,如果是获取写锁就会等待;当一个goroutine获取写锁之后,其他的goroutine无论是获取读锁还是写锁都会等待。
var rwlock sync.RWMutex
rwlock.Lock() // 加写锁定
rwlock.Unlock() // 解除写锁定
rwlock.RLock() // 加读锁定
rwlock.RUnlock() // 解除读锁定改坏的质数计算代码:
package main
import (
"fmt"
"golang-journey/logging" "sync")
var wg sync.WaitGroup
var rwlock sync.RWMutex
func isPrime(n int) bool {
if n == 2 || n == 3 || n == 5 || n == 7 || n == 11 {
return true
}
for i := 2; i < n; i++ {
if n%2 == 0 || n%3 == 0 || n%5 == 0 || n%7 == 0 || n%11 == 0 {
// 提前过滤一批因子为质数的参数
return false
} else if n%i == 0 { // 再接着后面的遍历
return false
}
}
return true
}
func isPrimeChannel(id int, in []int, out []int, wg *sync.WaitGroup) { // chan在函数传参中应当写明通道方向
defer wg.Done()
logging.Info(fmt.Sprintf("isPrimeChannel %d started", id))
for n := range in { // for ... range可以自动处理通道关闭的情况
rwlock.Lock()
if isPrime(n) {
out = append(out, n)
}
rwlock.Unlock()
}
logging.Info(fmt.Sprintf("isPrimeChannel %d finished", id))
}
func printPrime(outNum []int) {
for n := range outNum {
fmt.Println(n)
}
wg.Done()
}
func main() {
inNum := make([]int, 16384) // 创建整型双向有缓冲通道
outNum := make([]int, 16384)
// 发送数字
idx := 0
for i := 2; i < 100; i++ {
inNum[idx] = i
idx++
}
// 写完数字后启动计算协程
wg := sync.WaitGroup{}
numCalculators := 4
wg.Add(numCalculators)
for i := 0; i < numCalculators; i++ {
go isPrimeChannel(i, inNum, outNum, &wg)
}
// 等待计算完毕
wg.Wait()
// 打印结果
go printPrime(outNum)
logging.Info("All done")
}示例(转载):
var (
x int64
wg sync.WaitGroup
lock sync.Mutex
rwlock sync.RWMutex
)
func write() {
// lock.Lock() // 加互斥锁
rwlock.Lock() // 加写锁
x = x + 1
time.Sleep(10 * time.Millisecond) // 假设读操作耗时10毫秒
rwlock.Unlock() // 解写锁
// lock.Unlock() // 解互斥锁
wg.Done()
}
func read() {
// lock.Lock() // 加互斥锁
rwlock.RLock() // 加读锁
time.Sleep(time.Millisecond) // 假设读操作耗时1毫秒
rwlock.RUnlock() // 解读锁
// lock.Unlock() // 解互斥锁
wg.Done()
}
func main() {
start := time.Now()
for i := 0; i < 10; i++ {
wg.Add(1)
go write()
}
for i := 0; i < 1000; i++ {
wg.Add(1)
go read()
}
wg.Wait()
end := time.Now()
fmt.Println(end.Sub(start))
}