Golang学习笔记(七):文件操作和泛型
文件操作
读取文件
方法一:os.File.Read()
file, err := os.Open(filePath) // 打开文件流
// 注意有个包叫path/filepath
file.Read(dst []bytes) (readBytes, err) // 读取文件内容, 返回读取到的字节数, 读不到就报错
defer file.Close() // 关闭文件流, 关不了会报错示例:
package main
import (
"fmt"
log "log/slog" // 目前主流日志库, 开箱即用
"os"
filepath "path/filepath" // 用于安全地处理路径
)
func main() {
fp, err := filepath.Abs("./flag")
// 待打开的文件路径为 F:\CodePractice\golang-journey\flag
if err != nil {
log.Error("文件路径格式化错误: %v\n", err)
}
fmt.Printf("待打开的文件路径为 %v \n", fp)
file, err := os.Open("./flag")
if err != nil {
log.Error("尝试打开文件, 但发生错误: %v\n", err)
}
defer func(file *os.File) {
err := file.Close()
if err != nil {
log.Error("尝试关闭文件, 但发生错误: %v\n", err)
}
}(file)
fileContent := make([]byte, 256)
readBytes, err := file.Read(fileContent) // 返回读取到的字节数或抛出错误
if err != nil {
log.Error("尝试读取文件, 但发生错误: %v\n", err)
if err == io.EOF {
log.Debug("已读取到文件末尾\n")
}
}
fmt.Printf("读取到%v字节, 文件内容: %v \n", readBytes, string(fileContent[:readBytes]))
// 读取到25字节, 文件内容: flag{This_is_just_a_flag}
}- 读取到文件末尾时会
Read函数会返回io.EOF错误 slog不自带参数格式化,所以上面写的调试语句其实打印不了参数……- 这里使用
filepath.Abs来处理(可能有的)路径遍历情形;如果有必要,还可以用String.HasPrefix检查文件路径是否在沙盒目录下,进一步地还可以禁用符号链接(symbol link)
os.File指针会自动后移
os.File 的本质:操作系统文件描述符的“状态化”封装
当你调用 os.Open 或 os.Create 时,Go 的 os 包在底层会向操作系统内核请求一个文件描述符 (File Descriptor)。
文件描述符:在操作系统层面,这只是一个简单的整数,它代表了一个打开的文件。
内核的维护:对于每一个文件描述符,操作系统内核都会维护一个与之关联的**“文件描述表 (File Description Table)”。这个表里记录了所有关于这个打开文件的状态信息**,其中最重要的一项就是:当前的读写偏移量 (current file offset)。
os.File 这个 struct,就是 Go 语言对这个“带有状态的文件描述符”的一个高级封装。
所以,当你调用 f.Read(buffer) 时,发生了以下一系列事情(简化版):
Go 的 f.Read 方法调用了底层的 read() 系统调用,并把你的 buffer 和文件描述符交给了操作系统内核。
内核根据文件描述符,找到了它的状态表,看到了当前的偏移量(比如是 0)。
内核从磁盘上文件的偏移量 0 开始,读取数据,填满你的 buffer。
读取了多少字节,内核就把状态表里的那个偏移量向后移动多少字节。
read() 系统调用返回,f.Read 方法也返回。
下一次你再调用 f.Read(buffer),内核看到的就是一个已经被更新过的、更大的偏移量,于是它就从新的位置继续读取。
结论: os.File 是一个有状态 (stateful) 的对象。它的状态由操作系统内核维护。Read 和 Write 方法会自动更新这个状态。
据此,可以尝试调小一点切片容量,测试一下分步读取
func readFileByBlock(file *os.File, blockSize int) {
log.Info(fmt.Sprintf("单次读取%v字节\n", blockSize))
totalReadBytes := 0
fileContentBlock := make([]byte, blockSize)
var fileContent []byte
for readBytes, err := file.Read(fileContentBlock); ; readBytes, err = file.Read(fileContentBlock) {
if err == io.EOF {
log.Info("文件已读完")
break
} else if err != nil {
log.Error("尝试读取文件, 但发生错误: %v\n", err)
break
}
totalReadBytes += readBytes
fmt.Printf("已读取%v字节, 文件内容: %v \n",
readBytes, string(fileContentBlock),
)
fileContent = append(fileContent, fileContentBlock...)
}
log.Info(fmt.Sprintf("总计读取%v字节, 文件内容: %v \n",
totalReadBytes, string(fileContent),
))
}已读取4字节, 文件内容: flag
已读取4字节, 文件内容: {Thi
已读取4字节, 文件内容: s_is
已读取4字节, 文件内容: _jus
已读取4字节, 文件内容: t_a_
已读取4字节, 文件内容: flag
已读取1字节, 文件内容: }lag
2025/10/26 22:29:50 INFO 成功打开文件
2025/10/26 22:29:50 INFO 单次读取4字节
2025/10/26 22:29:50 INFO 文件已读完
2025/10/26 22:29:50 INFO 总计读取25字节, 文件内容: flag{This_is_just_a_flag}lagGo也提供了手动调整文件偏移的方法:
// io.Seeker 接口
type Seeker interface {
Seek(offset int64, whence int) (int64, error)
}Seek 方法,直接对应底层的 lseek() 系统调用*os.File 实现了这个接口。
f.Seek(0, io.SeekStart): 跳转到文件开头。f.Seek(0, io.SeekEnd): 跳转到文件末尾。f.Seek(-10, io.SeekCurrent): 从当前位置向前移动 10 个字节。
方法二:bufio读取文件
//os.Open(filePath string) (*File, error) // 打开文件流
file, err := os.Open("./main.go")
// NewReader(rd io.Reader) *Reader // 创建reader对象
// 上面得到的file指针可以直接传进这里, 因为*File这个类型同时也是io.Reader
reader := bufio.NewReader(file)
// (b *Reader) ReadString(delim byte) (string, error)
line, err := reader.ReadString('\n') // 读取文件 // 这样写的话文件第一行末尾必须有换行符
defer file.Close() // 关闭文件流示例:
func main() {
fp, err := filepath.Abs("./flag")
// 待打开的文件路径为 F:\CodePractice\golang-journey\flag if err != nil {
log.Error("文件路径格式化错误: %v\n", err)
return
}
fmt.Printf("待打开的文件路径为 %v \n", fp)
file, err := os.Open("./flag")
if err != nil {
log.Error("尝试打开文件, 但发生错误: %v\n", err)
return
}
defer func(file *os.File) {
err := file.Close()
if err != nil {
log.Error("尝试关闭文件, 但发生错误: %v\n", err)
os.Exit(-1) // 直接退出程序, 省得Panic
}
}(file)
// 上面打开文件流的方式没变
// 下面用bufio读取文件
reader := bufio.NewReader(file)
line, err := reader.ReadString('\n') // 文件里没有换行符, 这里为了运行正常, 先加了个换行进去
if err != nil {
log.Error("尝试读取文件, 但发生错误: %v\n", err)
return
}
fmt.Printf("读取到的内容是: %v \n", line)
// 读取到的内容是: flag{This_is_just_a_flag}
}- 这里读取时也一样要处理
io.EOF错误(上面是没改的代码)
方法三:os.ReadFile一步到位
打开关闭文件它都封装好了
ioutil.ReadFile("./main.go") // 已废弃
os.ReadFile("./main.go")示例:
func main() {
filePath, _ := filepath.Abs("./flag")
// 一句话流
fileContent, _ := os.ReadFile(filePath)
fmt.Printf("文件内容: %v \n", string(fileContent))
fileContent, _ = ioutil.ReadFile(filePath) // 已废弃
fmt.Printf("文件内容: %v \n", string(fileContent))
}Go 1.16中对ioutil库的迁移
ioutil.ReadFile(filename)移动到了os.ReadFile(filename)。ioutil.WriteFile(filename, data, perm)移动到了os.WriteFile(filename, data, perm)。ioutil.ReadAll(reader)移动到了io.ReadAll(reader)。ioutil.TempFile和ioutil.TempDir移动到了os.CreateTemp和os.MkdirTemp。ioutil.NopCloser移动到了io.NopCloser。ioutil.Discard移动到了io.Discard。
为了向后兼容,ioutil 包并没有被立刻删除。旧的函数(如ioutil.ReadFile)被保留了下来,但它们的内部实现,现在只是简单地调用了新的函数(os.ReadFile),并且这些旧函数都被标记为**“已废弃”** 。
写入文件
操作同理
方法一:os.File.Write() (只有这个可以追加写入)
fp, err := file.Abs("./main.go") // 规范化路径
file, err := os.OpenFile("./flag", os.O_RDWR|os.O_APPEND|os.O_CREATE, 0666) // 打开IO文件流
写入的字节数, err := file.Write(content []byte) // 写入字节序列或字节流
defer file.Close() // 关闭文件流os.Open()返回的是只读文件流,如果强行写入,会在运行时抛出Access is Denied错误os.OpenFile()接受三个参数:name string:文件路径flag int:操作标志;这里选择了O_RDWR读写模式、O_APPEND追加写和O_CREATE如果文件不存在就创建文件;大部分用户都会选择O_RDWR和O_CREATEperm FileMode:文件权限掩码,对应O_CREATE权限所创建的文件,需要手动指定;下面的示例指定了0666,即对文件所有者、文件所有者组内的用户和组外的用户,都拥有读写权限
os.OpenFile()也是双返回值函数;抛出的错误是*PathError类型的,顾名思义只能是文件路径错了才会报错
常见操作模式有以下几种:
os.O_WRONLY = 0x0001:只写os.O_CREATE:如果文件不存在就创建文件os.O_RDONLY = 0x0000:只读os.O_RDWR = 0x0002:可读可写os.O_TRUNC:清空os.O_APPEND:追加写入
是以位掩码形式组织的,在代码里使用|按位或运算符进行拼接计算
示例:
func main() {
fp, err := filepath.Abs("./flag")
// 待打开的文件路径为 F:\CodePractice\golang-journey\flag if err != nil {
log.Error(fmt.Sprintf("文件路径格式化错误: %v\n", err))
}
fmt.Printf("待打开的文件路径为 %v \n", fp)
// file, err := os.Open("./flag") // 返回的是只读的文件流
file, err := os.OpenFile("./flag", os.O_RDWR|os.O_APPEND|os.O_CREATE, 0666)
// O_RDWR 写权限 // O_APPEND 追加写 // O_CREATE 如果文件不存在则创建
if err != nil {
log.Error(fmt.Sprintf("尝试打开文件, 但发生错误: %v\n", err))
}
defer func(file *os.File) {
err := file.Close()
if err != nil {
log.Error(fmt.Sprintf("尝试关闭文件, 但发生错误: %v\n", err))
}
}(file)
// 写入文件
toBeWritten := []byte("\nhello world\n")
writtenBytes, err := file.Write(toBeWritten)
if err != nil || writtenBytes != len(toBeWritten) {
// 核心出装是后面这个条件 // 如果写入的字节数不等于待写入的字节数就会报错
log.Error(fmt.Sprintf("尝试写入文件, 但发生错误: %v\n", err))
os.Exit(1)
}
log.Info("写入文件成功")
}方法二:bufio写入文件
writer := bufio.NewWriter(file) // 单返回值方法
nn, err := writer.Write(toBeWritten) // 写入文件 // nn是写入的字节数
err := writer.Flush() // 清空缓冲区writer.Write方法如果写入的字节数和待写入的字节数不一致,会返回错误消息,告诉用户为什么进去的字数不够(文档原话)writer.Flush也有可能报错,返回为什么清空不了缓冲区的原因
示例:(打开文件流的方式没变)
// 写入文件
toBeWritten := []byte("\nhello world\n")
// 用bufio
writer := bufio.NewWriter(file)
nn, err := writer.Write(toBeWritten)
if err != nil || nn != len(toBeWritten) {
log.Error(fmt.Sprintf("关于为什么写进去的字数不够这件事: %v\n", err))
}
err = writer.Flush() // 清空IO缓冲区
if err != nil {
log.Error(fmt.Sprintf("尝试清空缓冲区, 但发生错误: %v\n", err))
}方法三:os.WriteFile一步到位
直接上示例:
func main() {
fp, err := filepath.Abs("./flag")
// 待打开的文件路径为 F:\CodePractice\golang-journey\flag if err != nil {
log.Error(fmt.Sprintf("文件路径格式化错误: %v\n", err))
}
fmt.Printf("待打开的文件路径为 %v \n", fp)
// 写入文件
toBeWritten := []byte("\nhello world\n")
err = os.WriteFile(fp, toBeWritten, 0666) // 不会自动追加, 要小心
if err != nil {
log.Error(fmt.Sprintf("写入文件错误: %v\n", err))
}
}- 【注意】:
os.WriteFile不会追加写入,也没给我权限位来控制开启追加 - 刚刚发现
bufio那边也没有追加功能
文件操作-拓展阅读 (AI警告)
为什么只有os.OpenFile可以追加写入(AI)
答案是:os.WriteFile 和 bufio.Writer.Write 之所以没有追加写入的参数,是因为在 Go 的设计哲学中,“写入模式(覆盖、追加等)”这个【属性】,是属于【文件句柄 (File Handle)】的,而不是属于【单次写入动作 (Write Operation)】的。
这个职责划分非常清晰,并且与底层操作系统的文件 I/O 模型完全一致。
1. 核心思想:打开时决定,写入时执行
你可以把这个过程想象成在厨房做菜:
打开文件 (
os.OpenFile):这是你**“准备锅”的阶段。你在这个时候就要决定好,你这口锅接下来的用途是什么:是用来炒一道全新的菜(覆盖),还是在已有的菜里加点调料(追加)**。这个决定,一旦做出,这口锅在这次使用中的“模式”就固定了。写入数据 (
file.Write/writer.Write):这是你**“往锅里放菜”的阶段。你只管把食材(数据)放进去就行了。至于这些食材是作为新菜的开始,还是作为旧菜的补充,完全取决于你之前准备的是一口什么样的锅**。
Go 的 API 设计完美地映射了这个逻辑。
2. os.WriteFile:一个高级封装的“便利店快餐”
os.WriteFile(filename, data, perm) 是一个为了便利性而生的高级函数。它的定位就是:“给我一个文件名和一堆数据,我帮你快速地、一次性地把这个文件【创建或完全覆盖】掉。”
- 它的内置行为:
os.WriteFile在其内部实现中,调用的就是os.OpenFile,并且写死了覆盖模式的标志位。它的伪代码大致是这样的:func WriteFile(name string, data []byte, perm FileMode) error { // O_WRONLY: 只写模式 // O_CREATE: 如果文件不存在,就创建 // O_TRUNC: 如果文件已存在,【清空它】!(TRUNCATE) f, err := OpenFile(name, O_WRONLY|O_CREATE|O_TRUNC, perm) if err != nil { return err } _, err = f.Write(data) // ... close and handle errors ... return err } - 为什么没有追加参数? 因为它的设计目标就不是为了处理复杂的写入场景。它就是一个简单、直接的“写入或覆盖”工具。如果允许追加,就会让这个简单函数的行为变得复杂,违背了它的设计初衷。
3. 如何实现“追加写入”?—— 使用“专业厨房” os.OpenFile
当你需要更精细的控制时(比如追加),你就不能再用“便利店快餐” os.WriteFile 了。你需要走进“专业厨房”,使用更底层的、功能更全面的 os.OpenFile。
os.OpenFile(name string, flag int, perm FileMode) 是 Go 中文件操作的**“万能钥匙”**。
关键在于
flag参数:这是一个整数,通过位运算|来组合不同的标志,精确地告诉操作系统你想以什么模式打开文件。实现追加写入的代码:
package main import ( "bufio" "fmt" "os" ) func main() { fileName := "my_log.txt" // 1. 【准备锅】:使用 OpenFile 并指定追加模式 // O_WRONLY: 只写 // O_CREATE: 如果不存在,则创建 // O_APPEND: 【追加模式!】 file, err := os.OpenFile(fileName, os.O_WRONLY|os.O_CREATE|os.O_APPEND, 0644) if err != nil { fmt.Println("Error opening file:", err) return } defer file.Close() // 2. 【往锅里放菜】 // 无论是直接 file.Write,还是通过 bufio.Writer,它们都不知道“追加”这件事 // 它们只管往这个已经处于“追加模式”的文件句柄里写数据 // a) 直接写入 // _, err = file.WriteString("Direct write\n") // b) 或者通过一个带缓冲的 Writer (性能更好) writer := bufio.NewWriter(file) _, err = writer.WriteString("Buffered write, append mode\n") if err != nil { fmt.Println("Error writing:", err) return } // 对于 bufio.Writer,必须 Flush 才能保证数据真正写入文件 err = writer.Flush() if err != nil { fmt.Println("Error flushing:", err) } }当你多次运行这段代码时,你会发现
my_log.txt文件的内容会不断地增加,而不是被覆盖。
4. bufio.Writer.Write 为什么也没有?
现在你就很好理解 bufio.Writer 了。它是一个纯粹的、位于内存中的“缓冲区”。它与文件系统、网络或任何具体的 I/O 设备完全解耦。
- 它的职责只有一个:将你零散的、小的写入操作,在内存里“攒”起来,然后一次性地、大批量地调用其底层
io.Writer的Write方法,以提高性能。 - 它只关心它的底层是什么(任何实现了
io.Writer接口的东西),而完全不关心那个底层的东西是以什么“模式”打开的。那个模式是底层io.Writer(比如*os.File)自己的状态。
结论:
Go 的 I/O API 设计遵循了单一职责原则 (Single Responsibility Principle):
os.OpenFile: 负责定义与操作系统之间的**“会话模式”**(读、写、追加、创建...)。os.File: 负责代表这个已建立的、有状态的会话。file.Write: 负责执行一个无状态的“写入”动作。bufio.Writer: 负责优化这个“写入”动作,提供缓冲。
这种清晰的职责划分,使得 Go 的 I/O 体系非常灵活且可组合。当你需要追加时,请记住:这不是“写”的时候决定的,而是在“打开”的时候,就已经决定了。
文件操作位掩码分析(AI)
那么,
os.O_RDWR、os.O_TRUNC这些位掩码和系统底层有关系吗?
答案是:是的,它们和系统底层【有非常紧密、甚至是直接的映射关系】。
os.O_RDWR、os.O_TRUNC 这些 Go 语言中的常量,本质上就是对底层操作系统(主要是 Unix/Linux 和 Windows)的 open() 系统调用所使用的标志位 (flags) 的一层平台无关的 Go 语言封装。
1. 这背后的一场“系统调用 (System Call)”
让我们来看看当你执行 os.OpenFile(...) 时,Go 的运行时在背后为你做了什么。这个过程就像一次“跨界交流”:
你的 Go 代码 (用户态 User Space):
你调用了os.OpenFile("file.txt", os.O_WRONLY|os.O_CREATE|os.O_TRUNC, 0644)。Go 的
os包 (标准库):os包会接收你传入的这些 Go 常量。- 这些常量在 Go 的源码中,是根据不同的目标操作系统,被定义为不同的整数值的。
- 例如,在
syscall_linux.go文件里,你可能会看到类似这样的定义:这些十六进制的数字,与 Linux 内核头文件// package syscall const ( O_WRONLY = 0x1 O_CREATE = 0x40 O_TRUNC = 0x200 // ... and so on )<fcntl.h>中定义的 C 宏是完全一致的!
Go 的运行时 (Runtime) /
syscall包:- Go 运行时会将你组合好的标志位(通过
|位运算得到的一个整数),连同文件名和权限模式,一起打包。 - 然后,它会执行一条特殊的 CPU 指令,触发一次**“系统调用 (System Call)”,从用户态切换到内核态 (Kernel Space)**。这个调用的名字就是
open(在 Unix/Linux 上) 或CreateFile(在 Windows 上)。
- Go 运行时会将你组合好的标志位(通过
操作系统内核 (Kernel Space):
- 内核接收到了这个
open请求,看到了你传进来的那个整数 flag。 - 内核会解析这个整数的每一个比特位,来理解你的意图:
- “哦,第 0 位置了 1(
O_RDONLY是 0,O_WRONLY是 1),好的,这是只写模式。” - “哦,第 6 位置了 1 (
O_CREATE),好的,如果文件不存在,我就创建它。” - “哦,第 9 位置了 1 (
O_TRUNC),好的,如果文件存在,我就把它清空。”
- “哦,第 0 位置了 1(
- 内核根据这些指令,执行相应的操作,并在内核中创建一个“打开文件”的实例,然后返回一个文件描述符 (File Descriptor)(一个整数)给你的 Go 程序。
- 内核接收到了这个
返回 Go 代码:
- Go 的运行时接收到这个文件描述符,并将它封装成一个
*os.File对象,最后返回给你。
- Go 的运行时接收到这个文件描述符,并将它封装成一个
2. 为什么需要 Go 的这一层封装?
既然是直接映射,为什么不直接用 0x1, 0x40 这样的魔法数字呢?
平台无关性 (Platform Independence):
- 这是最重要的原因。
O_CREATE在 Linux 上的值可能是0x40(64),但在 FreeBSD 上可能是0x200(512),在 Windows 上更是对应着完全不同的CREATE_NEW等宏。 - Go 的
os.O_CREATE常量,为你抹平了这些底层差异。你只需要写os.O_CREATE,Go 的编译器在编译你的程序时,会根据你的目标操作系统(GOOS环境变量),自动地把它替换成那个平台对应的正确整数值。 - 这使得你的 Go I/O 代码,无需修改,就可以在 Linux, Windows, macOS 等不同系统上编译和运行。
- 这是最重要的原因。
可读性 (Readability):
os.O_WRONLY | os.O_CREATE | os.O_APPEND这行代码,即使是新手也能立刻读懂它的意图:“以只写、创建、追加的模式打开”。- 而
0x1 | 0x40 | 0x400这行代码,就是彻头彻尾的“天书”,需要你捧着系统手册才能看懂。
总结
| Go 的世界 (你的代码) | Go 标准库 (os, syscall) | 操作系统内核 (Linux, Windows, ...) |
|---|---|---|
os.O_TRUNC (可读的 Go 常量) | 平台适配,翻译成对应平台的整数值 (e.g., 0x200 for Linux) | 解析整数 0x200 的比特位,理解为“清空文件”的指令 |
其他的操作掩码去哪了?(AI)
注
O_TRUNC的值真的是0x200吗?这岂不是意味着文件操作不只有下面六种?(一种对应一个比特位算,9个比特位只用了6个)
os.O_WRONLY:只写os.O_CREATE:如果文件不存在就创建文件os.O_RDONLY:只读os.O_RDWR:可读可写os.O_TRUNC:清空os.O_APPEND:追加写入
你说得完全正确!O_TRUNC 的值真的是 0x200(在 Linux 上),这确确实实意味着文件操作的标志位远远不止你列出的那 6 种!
你列出的 6 种,是 Go 语言 os 包里提供的、在日常开发中最常用、最核心的平台无关标志位。但在这背后,隐藏着一个更庞大、更复杂的来自 Unix/Linux 世界的标志位家族。
1. 真实的 Linux open() 标志位世界
在 Linux 系统中,open() 系统调用可以接受的 flags 是一个“位掩码 (bitmask)”,由多个宏通过位或 | 运算组合而成。这些宏主要分为两大类:
a) 文件访问模式 (Access Modes)
这是必须提供的,而且这几个是互斥的,你只能选一个。它们的值很小,占据了整数的最低几位。
O_RDONLY(0x0000): 只读O_WRONLY(0x0001): 只写O_RDWR(0x0002): 读写
O_RDWR 的值是 2,正好说明了它不是 O_RDONLY | O_WRONLY。它们是独立的模式。
b) 文件创建标志 (Creation Flags)
这些是可选的,可以与访问模式进行 | 运算。它们的值都比较大,每个占据一个独立的比特位。
O_CREATE(0x0040): 如果文件不存在,则创建它。O_TRUNC(0x0200): 如果文件存在且是普通文件,并且以写模式打开,则将其长度截断为 0(清空)。O_APPEND(0x0400): 每次写入前,都将文件指针移动到文件末尾。- ... 以及更多你没在
os包里直接看到的!O_EXCL(0x0080): 与O_CREATE配合使用,如果文件已存在,则open()调用会失败。这可以用来实现安全的“锁文件”创建。O_SYNC(0x1000): 使每次write()操作都同步地写入磁盘,而不是仅仅写入内核缓冲区(保证数据持久性,但性能较低)。O_NONBLOCK(0x0800): 以非阻塞模式打开。O_DIRECTORY(0x10000): 如果路径不是一个目录,则open()失败。O_CLOEXEC(0x80000): 在执行exec系列系统调用时,自动关闭这个文件描述符。
2. Go 是如何封装和选择的?
现在,我们来看看 Go 的 os 包做了什么聪明的封装:
提供了最常用的、平台无关的子集:
你列出的那 6 个(实际上是 5 个,因为读写模式三选一)正是 Go 团队认为对于绝大多数高级应用开发来说,最重要、最核心的标志位。它们被放在了os包里,方便直接使用。把平台特定的标志位放在了
syscall包:
如果你确实需要使用那些更底层、更特殊的标志位(比如O_EXCL或O_SYNC),你仍然可以使用它们!它们没有被丢弃,而是被放在了更底层的syscall包中。
// syscall/types_windows.go
const (
// Invented values to support what package os expects.
O_RDONLY = 0x00000
O_WRONLY = 0x00001
O_RDWR = 0x00002
O_CREAT = 0x00040
O_EXCL = 0x00080
O_NOCTTY = 0x00100
O_TRUNC = 0x00200
O_NONBLOCK = 0x00800
O_APPEND = 0x00400
O_SYNC = 0x01000
O_ASYNC = 0x02000
O_CLOEXEC = 0x80000
o_DIRECTORY = 0x100000 // used by internal/syscall/windows
o_NOFOLLOW_ANY = 0x20000000 // used by internal/syscall/windows
o_OPEN_REPARSE = 0x40000000 // used by internal/syscall/windows
)一个使用 O_EXCL 的例子:安全地创建一个锁文件
package main
import (
"fmt"
"os"
"syscall" // 导入 syscall 包来获取更底层的标志位
)
func main() {
fileName := "my_lock_file.lock"
// 尝试以 O_CREATE 和 O_EXCL 模式创建文件
// O_EXCL 保证了这是一个“原子”操作:如果文件已存在,创建就会失败
// 这可以防止多个进程同时创建同一个文件的竞争条件
file, err := os.OpenFile(fileName, os.O_WRONLY|os.O_CREATE|syscall.O_EXCL, 0644)
if err != nil {
if os.IsExist(err) {
fmt.Println("Lock file already exists. Another process is running?")
} else {
fmt.Println("Error creating lock file:", err)
}
return
}
defer file.Close()
defer os.Remove(fileName) // 确保程序退出时删除锁文件
fmt.Println("Successfully acquired lock. Doing work...")
// ... do critical work here ...
}总结
- 你的直觉是对的:文件操作的世界远比那 6 个标志位要丰富。
O_TRUNC的值是0x200(512),明确地告诉你它占据了第 9 个比特位,这暗示了在它之前和之后,还有很多其他的“开关”。 - Go 的分层设计:
os包:提供了高级的、平台无关的、95% 场景够用的 API 子集。syscall包:提供了底层的、平台相关的、100% 完整的 API 访问能力,供那些需要精细控制的系统级编程使用。
你通过对一个小小常量值的敏锐观察,就揭开了 Go 语言在“高级封装”和“底层访问”之间进行优雅分层的设计思想。这是一个非常了不起的发现!
目录操作
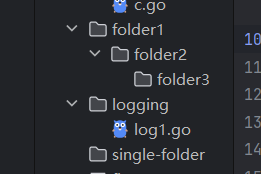
创建目录
// Mkdir(name string, perm FileMode) error
err := os.Mkdir("./folder", 0666)
// MkdirAll(path string, perm FileMode) erro
err := os.MkdirAll("./folder1/folder2/folder3", 0666)示例:
func main() {
oneFolderPath, _ := filepath.Abs("./single-folder")
multiFolderPath, _ := filepath.Abs("./folder1/folder2/folder3")
folderPerm := os.FileMode(0666) // 文件夹权限掩码, 对所有人均可读可写不可执行
err := os.Mkdir(oneFolderPath, folderPerm)
if err != nil {
// 如果文件夹已存在,就会报错
log.Error(fmt.Sprintf("%v\n", err))
return
}
log.Info(fmt.Sprintf("创建单个文件夹%v成功\n", oneFolderPath))
err = os.MkdirAll(multiFolderPath, folderPerm)
if err != nil {
log.Error(fmt.Sprintf("%v\n", err))
return
}
log.Info(fmt.Sprintf("创建多级文件夹%v成功\n", multiFolderPath))
}
删除目录和文件
os.Remove("./main.go")
os.RemoveAll("/folder1/folder2/folder3")os.RemoveAll还可以把整个目录连同次级文件和目录一起删掉,例如os.Remove("C:/")
文件、目录改名
err := os.Rename("file1", "file2", ...)泛型 Golang 1.18+:拥抱模板编程
拓展阅读(AI)
Golang于1.18版本引入泛型,解决了函数、方法、结构体和接口的复用性问题,并在编译时提供对特定数据类型的类型安全支持
// 导入一个包含预定义约束的包
import "golang.org/x/exp/constraints"
// [T constraints.Ordered] 就是“类型参数”和“类型约束”
func Min[T constraints.Ordered](a, b T) T {
if a < b {
return a
}
return b
}[T ...]- 类型参数 (Type Parameter)- 这是什么? T 是一个占位符,它代表“某个未来的、待定的类型”。
- 串联 C:你可以把它想象成 C++ 模板里的
template <typename T>。你正在写一个代码模板,而不是一个具体的函数。
constraints.Ordered- 类型约束 (Type Constraint)- 这是什么? 这是 Go 泛型的灵魂。它是一个编译时的契约,规定了“未来传入的那个 T 类型,必须满足什么条件”。
constraints.Ordered是一个预设的接口,它规定了 T 必须是支持<, <=, >, >=这些比较运算符的类型(如int,float64,string)。 - 串联 Python:这就像是给了 Python 动态的鸭子类型一个静态的、在编译时就能强制执行的“说明书”。
- Python 的
min_py隐式地要求参数支持<运算符。 - Go 的泛型,把这个隐式的要求,变成了显式的、由编译器强制检查的约束。
Min(myStruct1, myStruct2)->编译错误!因为myStruct类型不满足constraints.Ordered约束。这个错误在编译时就被发现了,而不是像 Python 那样在运行时。
- Python 的
- 这是什么? 这是 Go 泛型的灵魂。它是一个编译时的契约,规定了“未来传入的那个 T 类型,必须满足什么条件”。
func Min(...) T- 类型安全与性能- 当你调用
Min(10, 20)时,Go 编译器会检测到你用 int 实例化了这个泛型函数。 - 它会在编译时为你生成一个专门处理 int 的、高度优化的 Min 函数版本,就好像你亲手写了一个
MinInt(a, b int) int一样。 - 结果:你得到了 C 语言那种接近原生代码的性能,同时又享受到了 Python 那种一次编写的便利性,最重要的是,这一切都是在编译时类型安全的前提下完成的。
- 当你调用
- 对于 C 开发者:Go 泛型就像一个更简单、更安全的 C++ 模板,它用“约束”取代了复杂的 SFINAE 和 Concepts,让你能更容易地写出正确的泛型代码。
- 对于 Python 开发者:Go 泛型就像是把你的动态鸭子类型,和你用 Protocol + MyPy 进行静态分析的意图,直接内置到了语言和编译器中,并提供了 C 级别的性能。
情境引入
在笔记四中,我们接触到了switch x.(type),可以用这个结构编写针对不同类型的add运算——对于已知结构尚且还能遍历出来,但如果是结构体、接口等复杂数据类型呢?
即便是空接口/any类型,也需要类型断言或反射来获取支持特定运算的值,但如果类型一开始也拿不到呢?
使用泛型
func 函数名[类型槽位名 constrains常量](参数1, 参数2, 参数3, ... 前面声明的类型) (返回值 类型) {
// 函数体
}- 函数名:自定
- 类型槽位名:自定,最好设置成
T,这样符合直觉和开发规范 constraints常量:类型集合模板,原版Go有以下六种约束可选择:Signed:由所有有符号整型组成的类型集合~int | ~int8 | ~int16 | ~int32 | ~int64Unsigned:由所有无符号整型组成的类型集合~uint | ~uint8 | ~uint16 | ~uint32 | ~uint64 | ~uintptrInteger:前两个约束组成的类型集合Signed | UnsignedFloat:由两个浮点数类型组成的类型集合~float32 | ~float64Complex:复数类型组成的类型集合~complex64 | ~complex128Ordered:由所有支持<, <=, >, >=运算符的类型所组成的类型集合~int | ~int8 | ~int16 | ~int32 | ~int64 | ~uint | ~uint8 | ~uint16 | ~uint32 | ~uint64 | ~uintptr | ~float32 | ~float64 | ~string
~T表示取T类型的底层类型,比如type myInt int中myInt的是新类型,而底层类型为int——保证对类型定义的兼容|是类型联合 (Type Union) 操作符,所以上面的泛型声明其实就是在声明由一堆类型组成的集合;|的作用只出现在接口定义的类型列表(比如这里的constraints.Ordered),如果用在数值运算中,则是按位或运算
[类型名 constrains常量]:【编译时】的【类型参数声明】
示例:
func Min[T constraints.Ordered](a, b T) T {
if a < b {
return a
}
return b
}func Min ...: 你在设计一个叫 Min 的 DIY 工具包。[T ...]: 你在工具包的封面上,贴上了一个标签,上面写着:“本工具包需要一种原材料 T 才能工作。”constraints.Ordered: 这是标签旁边附带的**《原材料规格说明书》。上面详细写着:“你提供的原材料 T,必须是金属或硬塑料**(int, float64, string...),不能是木头(struct)。”(a, b T): 这是工具包里的两块模具,它们的形状都是根据你将来提供的原材料 T 的规格来定的。return b: 这是工具包的最终产物,它的材质也和你提供的原材料 T 一样。
给T改成其他名称也能跑: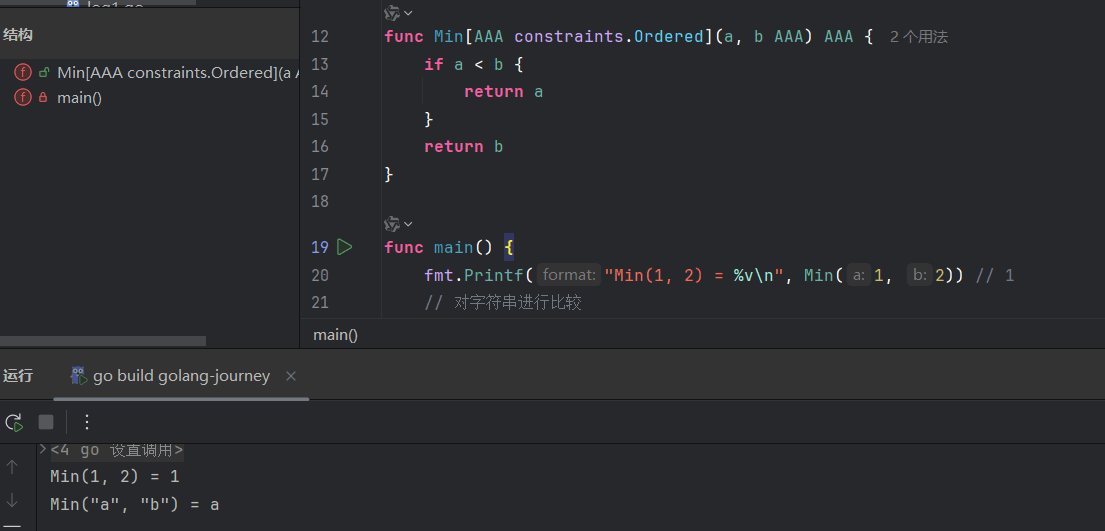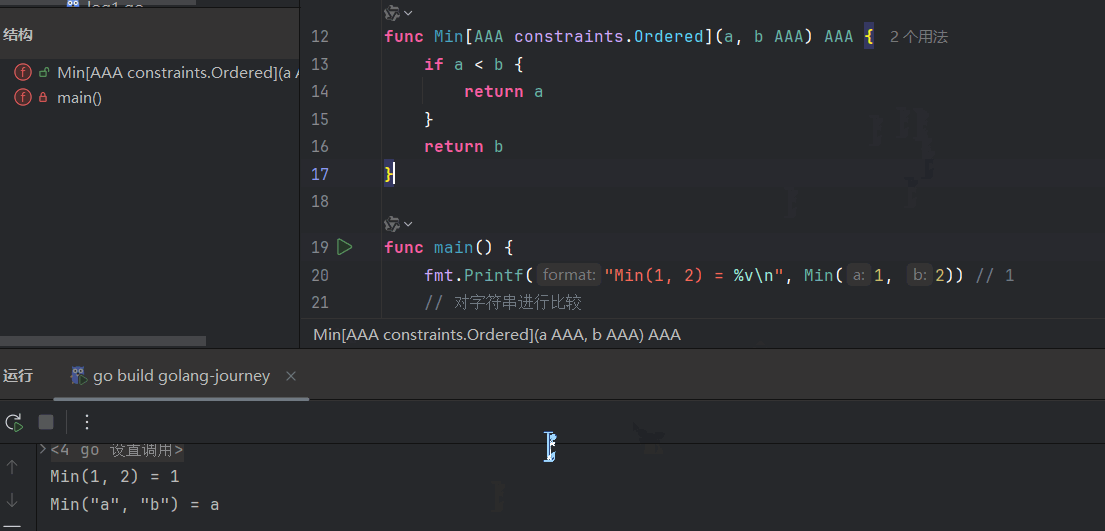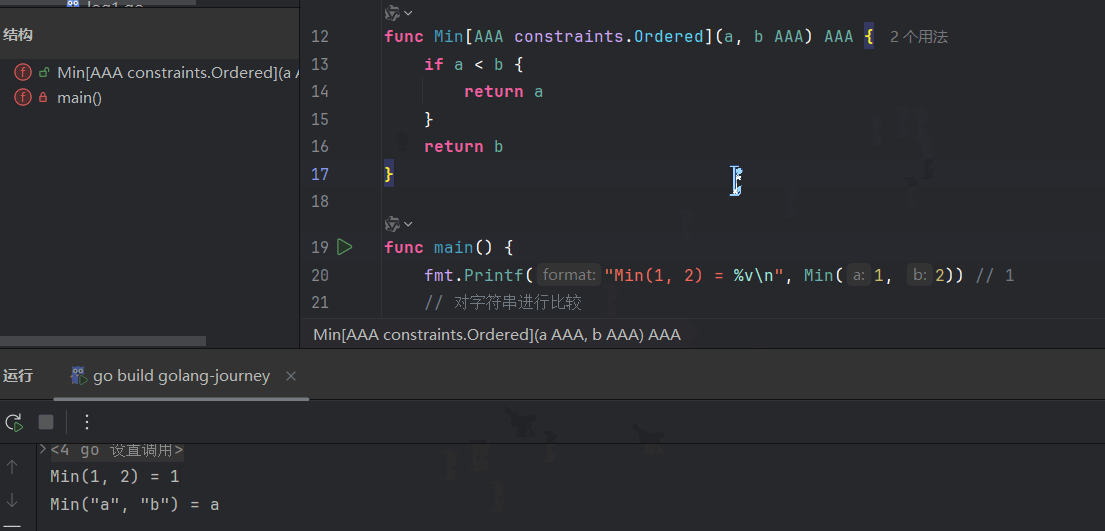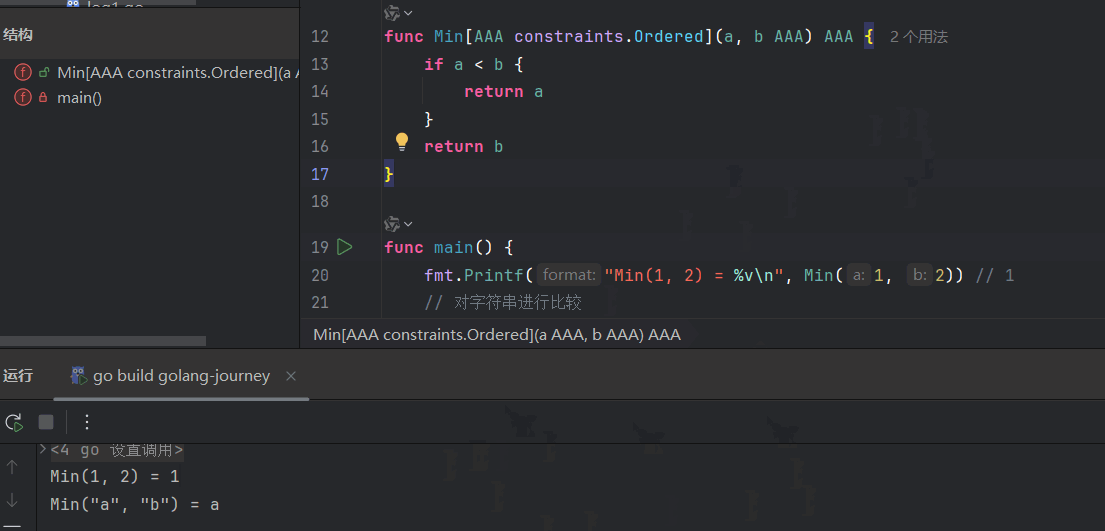
深入泛型:解析constraints (AI+人工整理)
注意
constraints包位于exp/实验模块路径下;稳定的约束常量位于cmp包中
下面的文案是AI生成的,所以给我找了个实验性的包出来……
约束常量不过是内充集合类型的一个interface
以constraints.Signed的声明为例:
// constraints/constraints.go
package constraints
import "cmp"
// Signed is a constraint that permits any signed integer type.// If future releases of Go add new predeclared signed integer types,
// this constraint will be modified to include them.
type Signed interface {
~int | ~int8 | ~int16 | ~int32 | ~int64
}首先介绍~T,它被称为类型近似元素 (Type Approximation Element),是 Go 泛型约束中一个极其重要的概念:
- T (没有波浪号):精确匹配。int 只匹配 int 本身。
- ~T (有波浪号):匹配所有【底层类型 (Underlying Type)】是 T 的类型。
比如说,type myInt int,myInt本身是新类型,但其底层类型仍为int类型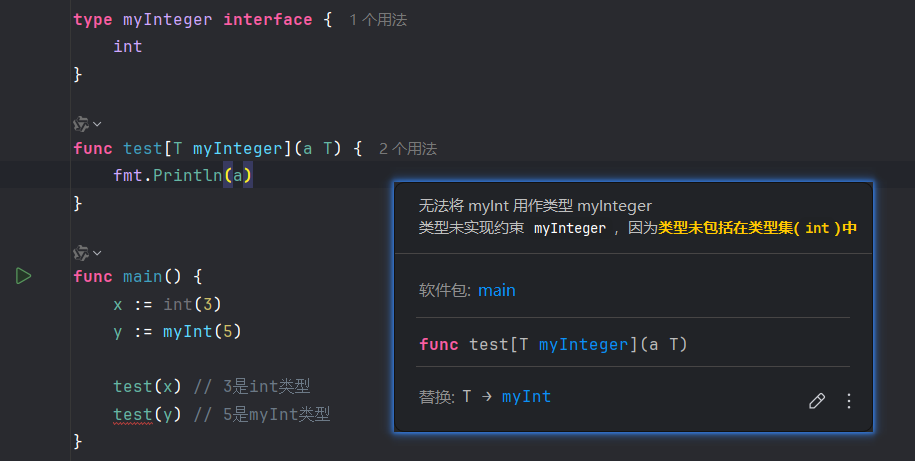
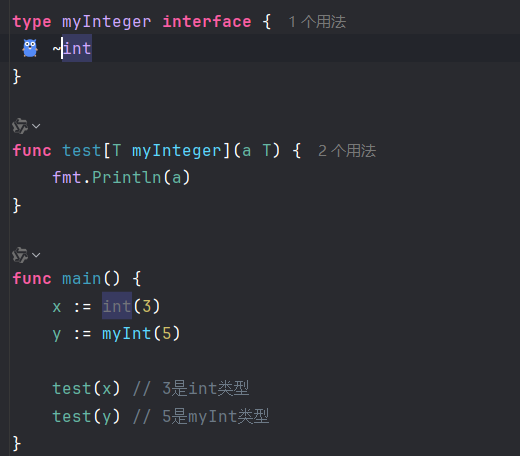
(加上~后编译就能通过了)
而~int | ~int8 | ~int16 | ~int32 | ~int64这些类型之间的|被称作类型联合运算符,也是在Go 1.18引入的,和泛型约束是一起的
- 在一个接口定义中,
|用来列举一个类型集合,表示“满足这个接口的类型,必须是 A 或 B 或 C...”。 - 经常和
~T一起使用。~T负责扩大单个类型的匹配范围(包括其衍生类型),而|负责将多个这样的范围合并成一个更大的类型集合。
既然如此,它和按位或是什么关系?
相关信息
- 上下文:
- 位或 |:作用于整数值的表达式中。
x := 1 | 2。 - 类型联合 |:只出现在接口定义的类型列表中。
type T interface { int | string }。
- 位或 |:作用于整数值的表达式中。
- 操作对象:
- 位或 |:操作的是数据(比特位)。
- 类型联合 |:操作的是类型本身。
它们只是恰好共用了同一个符号,但在不同的语法上下文中,含义完全不同。这在很多编程语言中都很常见(比如 * 可以是乘法,也可以是指针声明)。
而泛型,则让 interface 这个关键字拥有了双重身份。
- 传统身份:方法集 (
Method Set)- 语法:接口内部只包含方法签名。
type Reader interface { Read(p []byte) (n int, err error) } - 含义:“任何实现了 Read 方法的类型,都满足这个接口。”
- 语法:接口内部只包含方法签名。
- 新身份 (Go 1.18+):类型集 (
Type Set)- 语法:接口内部包含类型列表,用
|分隔。type Integer interface { int | int8 | int16 | int32 | int64 } - “
int, int8, int16, int32, int64这几个具体的类型,构成了 Integer 这个类型集合。任何类型,只要它就是这个集合中的一员,就满足这个接口约束。”
因此对于constraints.Ordered接口:
- 语法:接口内部包含类型列表,用
type Ordered interface {
// 这是一个【类型集合】
// 它的成员是:
~int | ~int8 | ~int16 | ~int32 | ~int64 | // 所有底层是各种 int 的类型
~uint | ~uint8 | ~uint16 | ~uint32 | ~uint64 | ~uintptr | // 所有底层是各种 uint 的类型
~float32 | ~float64 | // 所有底层是 float 的类型
~string // 所有底层是 string 的类型
}Ordered 接口的完整含义是:
- 我是一个类型约束。任何一个类型 T,如果它想满足我,它不必有任何方法。它只需要是以下类型中的一种,或者其底层类型是以下类型中的一种:所有整数、所有浮点数,以及 string。
这个接口之所以叫Ordered(有序的),是因为这个集合里的所有类型,都恰好是 Go 语言中内置支持<, <=, >, >=这些排序运算符的类型。
所以,当我们写func Min[T Ordered](a, b T) T时,我们实际上是在告诉编译器:
“我正在定义一个泛型函数
Min。它接受的类型 T,必须是我在 Ordered 接口里用 | 列出的那些类型之一。因为我向你(编译器)保证了这一点,所以请允许我在函数体内安全地使用 < 运算符。”
既然constraints本身并非动态地解析参数是否具有某种行为,而只是静态声明 适合的类型,那约束到底干了什么?
Go 泛型中的类型约束,在绝大多数情况下,【不是】在动态地“解析”或“推断”一个类型有什么行为。它更像是一个静态的、在编译时就定好了“模板”或“模具”。
- 罐子:
interface(约束)- 罐子的形状:就是你在
interface里用 | 定义的那个类型集合 (Type Set)。constraints.Ordered这个“罐子”,它的“洞口形状”就被精确地定义为“必须是整数、浮点数或字符串的形状”。
2.积木:Type(你要传入的类型)
- 罐子的形状:就是你在
- 积木的形状:就是你实际传入的那个类型,比如
int, string, MyInt, 或者一个struct。
- 编译器:守门的质检员
- 编译器的唯一工作:在编译时,拿起你的“积木”(比如
MyInt),去和“罐子”(比如constraints.Ordered)的“洞口”比对一下。- “放得进去就是放得进去”:
- 编译器拿起
MyInt,发现它的底层类型是int。 - 它去
constraints.Ordered的洞口定义(~int | ~float64 | ~string ...)里查找。 - “哦,
~int这一条规则匹配上了!这个积木放得进去。” -> 编译通过。
- 编译器拿起
- “放不进去再怎么塞也进不去”:
- 编译器拿起一个
struct User {}。 - 它去
constraints.Ordered的洞口定义里查找。 User的底层类型是struct,它不匹配~int, ~float64, ~string ...任何一条规则。- “这个积木形状不对,塞不进去。” -> 编译失败。
- 编译器拿起一个
- “放得进去就是放得进去”:
而Go 的接口现在有了两种“罐子”:
- 方法集接口 (Method Set Interface) - 老式罐子
- 洞口形状:由方法签名定义。比如 io.Reader 的洞口形状是“必须有一个 Read(...) 方法”。
- 检查方式:编译器检查你的“积木”上,有没有刻着所有需要的方法。
- 类型集接口 (Type Set Interface) - 泛型约束罐子
- 洞口形状:由类型列表定义。
- 检查方式:编译器检查你的“积木”本身,是不是名单上允许的那几种形状之一。
一个接口可以同时拥有这两种形状定义,从而创造出更复杂的“罐子”。
type StringableInt interface {
~int | ~int32 // 罐子的【形状】要求:底层必须是 int 或 int32
String() string // 罐子的【能力】要求:必须有一个 String() 方法
}这个 StringableInt 罐子就非常挑剔:你放进来的积木,不仅形状要对(底层是 int 或 int32),而且积木上还必须刻着 String() 这个“花纹”(方法)。
泛型的本质是接口……(AI+人工整理)
回顾前面对接口的定义,我们会发现接口本身就是用来规范数据类型的行为的另一种数据类型
那既然如此……干嘛还要搞个类型参数说明呢?直接当作传参的类型不也能用吗……?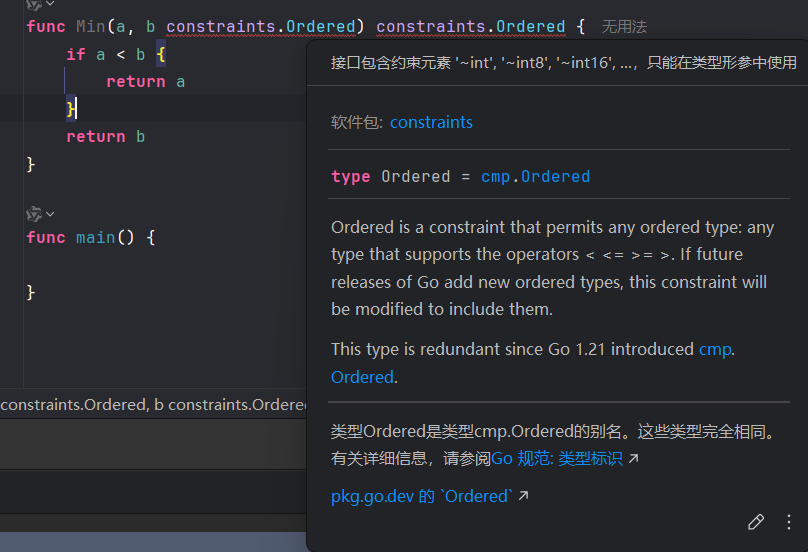
Go 的泛型约束,尤其是基于方法集的约束,在【思想和作用】上,与 Python 的 Protocol 不能说毫无关系,只能说一模一样。
| Go 的约束 (interface) | Python 的 Protocol |
|---|---|
type Stringer interface { String() string } | class Stringer(Protocol): def String(self) -> str: ... |
func Print[T Stringer](s T) | def print(s: Stringer) -> None: |
| 结构化子类型:只要有 String 方法就行。 | 结构化子类型:只要有 String 方法就行。 |
| 静态检查:编译器强制检查。 | 静态检查:MyPy 强制检查。 |
| 所以……泛型约束就是 Go 语言原生的、由编译器强制执行的 Protocol。 |
既然如此,为什么不能把泛型当协议用:
func Print(s Stringer) { ... } // 伪代码,Go 不支持而要先有个前摇呢?
func Print[T Stringer](s T) { ... }答案是:因为 Go 需要区分两种截然不同的“多态”——【动态多态 (Dynamic Polymorphism)】和【静态多态 (Static Polymorphism)】。而这两种多态,在性能和实现机制上有着天壤之别。
自定义泛型接口和方法(示例)
【自定义约束】正是 Go 泛型强大能力和灵活性的核心所在!
package main
import (
"fmt"
"strconv"
)
// 1. 【自定义组合约束】
type StringableID interface {
~int | ~int64 // 类型集:限制了它的“形状”
fmt.Stringer // 方法集:嵌入了 fmt.Stringer,要求它必须有 String() string 方法
}
type MyID int
func (i MyID) String() string {
return "ID-" + strconv.Itoa(int(i))
}
type AnotherID int64
// AnotherID 没有 String() 方法
// 2. 在泛型函数中使用
func ProcessID[T StringableID](id T) {
fmt.Printf("Received ID: %s\n", id.String()) // 编译器保证了 id 一定有 String() 方法
}
func main() {
var id1 MyID = 123
ProcessID(id1) // OK! 底层是 int,且有 String() 方法
// var id2 AnotherID = 456
// ProcessID(id2) // 编译错误!AnotherID does not implement StringableID (missing String method)
// var id3 int = 789
// ProcessID(id3) // 编译错误!int does not implement StringableID (missing String method)
}- 可以显式传入参数类型:
ProcessID[MyID](id1)
泛型类
type 结构体类型名 [T 可接受的类型接口] struct {
value 类型
}