Golang学习笔记(二):函数
原味函数
函数签名
func 函数名(参数1 参数1类型, 参数2 参数2类型, ...) (
<返回值名称> 返回值类型1, <返回值名称> 返回值类型2, error
)参数类型:可选;如果写了,编译器会帮你校验类型<返回值名称>:可选;如果写上,那么编译器会自动给函数作用域加上返回值变量,可以直接调用和赋值error:可选;表示操作是否成功,成功则应该返回nil,不成功则返回错误
函数可以没有传参,也可以没有返回值;函数签名就决定了函数的传参行为和返回值行为,编译器不会自作主张加东西上去
没有返回值的函数不能放在赋值运算符的右边
示例:
func add(x int, y int) (sum int) {
sum = x + y
return sum
}
func main() {
fmt.Println(add(1, 2))
}
像左边这样写也行,只有一个返回值的时候可以不给返回值加括号
当函数首字母大写时,表示这个函数可被导出 ,可被其他package调用,反之则只能在同名package中使用,若强行调用,则会中断编译
上面的add和main函数都是main包的私有函数
【可变参数函数】函数可以接受多个相同类型,可以自动打包多个(同类型的)传参:
func sum(num ...int) (sum int) {
// 传入的num会是一个[]int数组
sum = 0
for _, n := range num {
sum += n
}
return sum
}
func main() {
fmt.Println(sum(1, 2, 3, 4)) // 10
}固定参数可以和可变参数混用:注意现在可变参数的前一个参数必须写上类型,否则会同步下一个参数(这里是可变参数)的类型,而可变参数只能是最后一个传参,这是一个语法错误
func sumV2(num1 int, num ...int) (sum int) {
// 传入的num会是一个[]int数组
sum = num1
for _, n := range num {
sum += n
}
return sum
}
func main() {
fmt.Println(sumV2(1, 2, 3, 4))
}函数作用域
- 函数的变量只能在函数内部使用
- 全局变量在
package作用域中均有效,可在函数中被修改
// 全局变量
var a = 1
func start() {
a = 2
fmt.Println(a) // 2
}
func main() {
start()
}package命名相同的文件被视为同一个包,共享全局变量和函数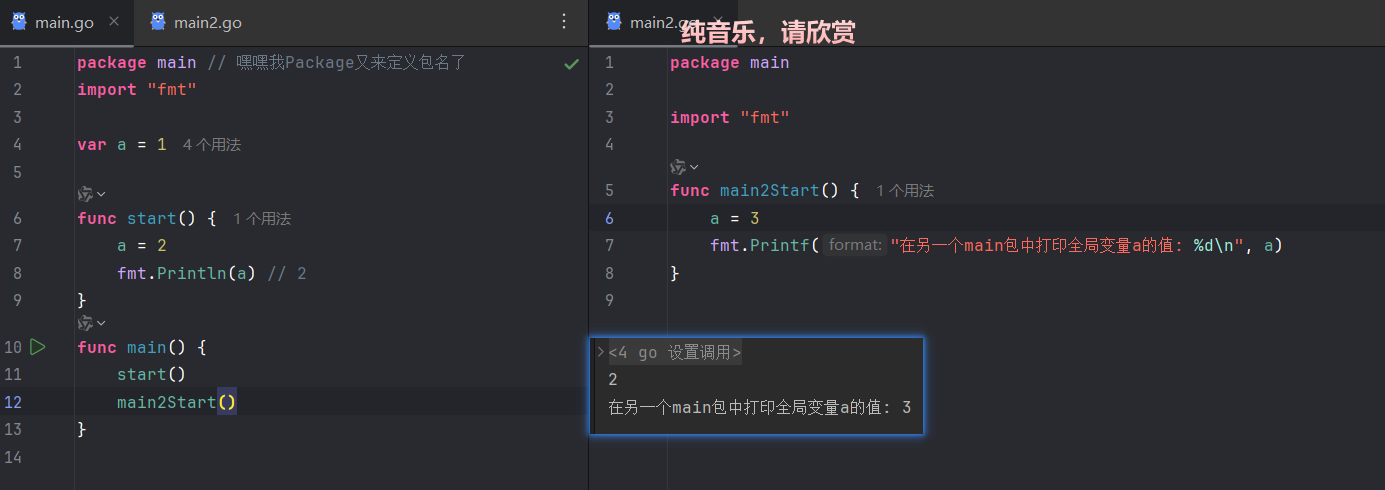
函数注释
// FunctionName is a one-sentence summary of what the function does.
// (空一行)
// More detailed explanation of the function's behavior, its context,
// or any nuances in its implementation.
//
// Special conditions, such as panics, should be mentioned here.
func FunctionName(param1 Type1, param2 Type2) (ReturnType1, error) {
// ...
}传参为引用类型的函数(AI总结)
函数内部对引用类型参数的修改,会直接影响到函数外部的原始变量。
函数会创建传参的副本,但引用传参内存储的并非底层数据,而只是指向同一块数据的指针
在 Go 中,向函数传递“引用类型”(切片、map、channel、指针)时,你本质上是在传递一个“遥控器”的副本。两个遥控器虽然独立,但都控制着同一台“电视机”(底层数据)。
这个模型带来了巨大的便利和性能优势,但也伴随着几个必须时刻警惕的“陷阱”。以下是你在编写这类函数时需要注意的核心问题:
1. 核心问题一:无意的副作用 (Unintentional Side Effects)
这是最常见、也最需要注意的问题。函数内部对引用类型参数的修改,会直接影响到函数外部的原始变量。
你需要问自己: “我这个函数,是期望去修改调用者的数据,还是不期望?”
示例:
// 这个函数会“污染”传入的 map
func processData(data map[string]string) {
data["processed"] = "true" // 这个修改对外部是可见的!
}
func main() {
user := map[string]string{"name": "Alice"}
processData(user)
fmt.Println(user) // 输出: map[name:Alice processed:true] <-- 原始的 user 被修改了!
}⚠️ 注意事项与最佳实践:
- 明确意图:如果你的函数设计就是要修改传入的数据(例如
sort.Ints),这完全没问题。但你应该通过函数命名和文档注释来明确地表达这个意图。比如函数名叫populateMap或filterSliceInPlace。 - 防御性拷贝 (Defensive Copying):如果你的函数不应该修改原始数据,但内部又需要进行修改,那么你必须在函数入口处创建一个副本。
func processDataSafely(data map[string]string) map[string]string { // 1. 创建一个新 map 作为副本 newData := make(map[string]string, len(data)) // 2. 拷贝数据 for k, v := range data { newData[k] = v } // 3. 在副本上进行所有操作 newData["processed"] = "true" return newData }
2. 核心问题二 (切片专属):append 可能导致的“连接断开”
这是切片最独特的“陷阱”。我们之前讨论过,当 append 导致切片容量不足时,会分配一个新的底层数组。
如果函数内部的 append 触发了扩容,那么函数里的切片参数(那个遥控器)就会指向一台“新电视机”,而函数外的原始切片(旧遥控器)仍然指向那台“旧电视机”。
示例:
func appendData(s []int) {
// 假设 s 传入时 len=3, cap=3
s = append(s, 100) // 内部触发扩容,s 现在指向了一个新的底层数组
fmt.Println("Inside function:", s) // 输出: [1 2 3 100]
}
func main() {
mySlice := []int{1, 2, 3}
appendData(mySlice)
fmt.Println("After function:", mySlice) // 输出: [1 2 3] <-- !!!没有变化!!!
}⚠️ 注意事项与最佳实践:
- 黄金法则:任何可能导致切片长度或容量改变的函数,都必须返回修改后的新切片。 这是 Go 语言的一条铁律。
- 正确的函数签名:
func appendDataCorrectly(s []int) []int { // 必须有返回值! s = append(s, 100) return s } func main() { mySlice := []int{1, 2, 3} mySlice = appendDataCorrectly(mySlice) // 调用者必须接收返回值! fmt.Println("After function:", mySlice) // 输出: [1 2 3 100] }
3. 核心问题三:nil 值的处理
“引用类型”的零值都是 nil。如果你的函数没有预料到会传入一个 nil 的 map 或 slice,可能会导致程序 panic。
示例:
func getStatus(data map[string]bool) bool {
// 如果 data 是 nil,下面这行会 panic!
return data["status"]
}
func main() {
var userStatus map[string]bool // userStatus is nil
getStatus(userStatus) // panic: assignment to entry in nil map
}panic: assignment to entry in nil map 是 Go 新手最常遇到的 panic 之一。
⚠️ 注意事项与最佳实践:
- 入口检查:在函数的开头,对可能为
nil的参数进行检查,是一种很好的防御性编程习惯。func getStatusSafely(data map[string]bool) bool { if data == nil { return false // 或者返回一个错误 } return data["status"] } - 了解
nil的行为:- 对一个
nilmap 进行读取 (data["status"]) 或len()操作是安全的(会返回零值)。但对其进行写入 (data["status"] = true) 则会panic。 - 对一个
nilslice 进行append是安全的,Go 会为你分配一个新的数组。len()和cap()也是安全的。
- 对一个
4. 核心问题四 (并发):数据竞争 (Data Races)
如果你在多个 Goroutine 中,将同一个引用类型变量(比如一个 map)传递给不同的函数,并且这些函数会写入这个 map,那么你就会遇到数据竞争。这是 Go 并发编程中的头号杀手。
Go 的运行时检测到并发地对 map 进行写操作时,会直接 panic。
⚠️ 注意事项与最佳实践:
- 不要共享内存来通信,而要通过通信来共享内存。 (Go 的核心信条)
- 如果必须在多个 Goroutine 间共享一个引用类型(尤其是 map),你必须使用同步机制来保护它。最常用的就是互斥锁 (
sync.Mutex)。type SafeMap struct { mu sync.Mutex data map[string]string } func (sm *SafeMap) Set(key, value string) { sm.mu.Lock() // 加锁 defer sm.mu.Unlock() // 确保函数退出时解锁 sm.data[key] = value }
总结:检查清单
在编写接收“引用类型”的函数时,请在脑海中过一遍这个清单:
- [副作用] 我是否会修改传入的数据?我的函数名和文档是否清晰地反映了这一点?
- [副作用] 如果我不应该修改,我是否创建了防御性拷贝?
- [切片专属] 我的函数是否改变了切片的长度(例如使用
append)?如果是,我是否返回了新的切片? - [
nil安全] 我的函数能否安全地处理nil参数? - [并发安全] 这个函数是否可能在多个 Goroutine 中被调用?如果是,共享的数据是否受到了锁或其他同步机制的保护?
函数函数
函数为传参、函数为返回值的函数
函数类型
var funcType func(参数类型1, 参数类型2, ...) (返回值类型1, 返回值类型2, ...)示例:
func add(a, b int) int {
return a + b
}
func subtract(a, b int) int {
return a - b
}
func main() {
// 声明一个名为 op 的变量,它的类型是“一个接受两个 int 并返回一个 int 的函数”
var op func(int, int) int
// 把 add 函数这个“值”,赋给 op 变量
op = add
result := op(5, 3)
// 调用 op,实际上是在调用 add fmt.Printf("Result of op(5, 3): %d\n", result)
// 输出: 8
fmt.Printf("Type of op is: %T\n", op)
// 输出: func(int, int) int
// 可以把另一个符合同样“蓝图”的函数赋给 op op = subtract
result = op(5, 3)
// 这次调用 op,是在调用 subtract fmt.Printf("Result of op(5, 3): %d\n", result)
// 输出: 2
}将函数作为传参
package main
import "fmt"
// var printf = fmt.Printf
// var println = fmt.Println
// 如果你想这样玩,那么注意避开内置函数`print`
// Goland可以自动补全, 不需要自己打
type calculation func(int, int) int
func add(a, b int) int {
return a + b
}
func sub(a, b int) int {
return a - b
}
func calc(op calculation, a int, b int) int {
fmt.Printf("对操作数%v和%v执行操作%T\n", a, b, op) // 这里如果是#v, 那么会打印函数指针的值
return op(a, b)
}
func main() {
fmt.Printf("5 + 3 = %d\n", calc(add, 5, 3))
// 对操作数5和3执行操作main.calculation
// 5 + 3 = 8 fmt.Printf("5 - 3 = %d\n", calc(sub, 5, 3))
// 对操作数5和3执行操作main.calculation
// 5 - 3 = 2}将函数作为返回值
type calculation func(int, int) int
func calcFactory(opChar rune) calculation {
var op calculation
switch opChar {
case '+':
op = func(a int, b int) int {
return a + b
}
case '-':
op = func(a int, b int) int {
return a - b
}
case '*':
op = func(a int, b int) int {
return a * b
}
case '/':
op = func(a int, b int) int {
return a / b
}
default:
op = nil // switch-case结构允许中途退出函数并产生返回值, 但为了兼容,就这样写了, 拿一个变量先接起来
}
return op
}
func main() {
myMul := calcFactory('*')
fmt.Printf("4 * 3 = %d\n", myMul(4, 3))
}匿名函数
上面还用到了匿名函数和 闭包函数:
// 格式
func(参数1, 参数2, ...) (返回值1, 返回值2, ...) {
// 函数体
}匿名函数可以立即自行 调用:
func main() {
func() {
fmt.Printf("Hello World\n")
}()
}函数操作
函数递归
// 连加求和函数
func sigma(top int) int {
if top <= 0 {
return 0
} else {
top += sigma(top - 1)
return top
}
}
func main() {
fmt.Println(sigma(100)) // 5050
}函数闭包:函数内的函数
func main() {
fmt.Printf("Hello World\n")
// 匿名函数
func() {
a, b := 1, 2
// 闭包函数
func() {
fmt.Println(a, b) // 在闭包函数里可以访问外部函数的变量
}()
}()
}闭包函数和外部函数共享作用域,除非给这个闭包函数传了同名变量……
也可以把这个函数返回出来,看这一节:将函数作为返回值
函数延迟执行:defer关键字
注
Defer (动词): 推迟,延期 (to put off to a later time; postpone).
defer 关键字的行为s:将一个函数调用“推迟”到其所在的函数即将返回之前再执行。
理解 defer 最好的方式,是把它看作 Go 语言为资源清理和收尾工作提供的自动化安全网。
func start() {
fmt.Printf("Entered program\n")
}
func theEnd() {
fmt.Printf("Program is to exist\n")
}
func main() {
defer theEnd()
start()
fmt.Printf("Hello World\n")
/*
Entered program Hello World Program is to exist */}defer修改返回值、recover()拦截panic
在延迟执行的闭包函数中如果有修改外部作用域的变量的操作,那么这个操作不会(在函数内)生效:
func main() {
var a int // 默认值为0
defer func() { a++ }()
fmt.Printf("a的值为: %d\n", a)
// a的值为: 0
}更进一步地,defer 修改返回值的能力,是 Go 语言中一个强大但需要小心使用的特性。它充分暴露了 defer 语句真正的执行时机。
要理解这个机制,我们必须先搞清楚 Go 函数返回过程的两个阶段:
- 第 1 阶段:赋值 (Assignment)
当 return 语句被执行时,Go 会先计算出返回值,并将这个结果赋值给将要返回给调用者的变量。如果函数使用了命名返回值 (Named Return Values),这个赋值动作就是显式的。 - 第 2 阶段:返回 (Return)
在赋值之后、函数真正退出之前,Go 会按照 LIFO (后进先出) 的顺序,执行所有被推迟的 defer 函数。
【关键】:defer 函数可以访问和修改那些已经被赋值、但尚未正式返回的返回值变量。
完成所有 defer 调用后,函数才带着(可能已被 defer 修改过的)返回值正式退出。
defer 只能直接修改【命名返回值】,因为只有它们在 defer 的作用域内是可见的。
package main
import "fmt"
func namedReturn() (i int) { // i 在这里被声明,并初始化为零值 0
defer func() {
i++ // 这个 i 就是那个将被返回的变量 i
fmt.Printf("defer: i = %d\n", i) // defer: i = 1
}()
// 1. (这里没有 return 语句,但函数结束时会隐式 return i)
// 2. 将 0 赋值给返回值 i (实际上它已经是 0 了)
// 3. 执行 defer (i++ 直接修改了返回值 i,i 现在是 1)
// 4. 函数带着那个【已被修改的】返回值 i (值为 1) 退出
return i // 你也可以写 return 0,效果一样
}
func main() {
fmt.Printf("main: result = %d\n", namedReturn()) // main: result = 1
}匿名返回值是不可修改的,这里不做演示
defer+recover捕获panic
这个特性最常见的用途,是在函数退出前,通过 defer 来统一处理错误,并可能“捕获” panic,然后修改返回值来通知调用者。
一个经典的例子:在 defer 中捕获 panic:
package main
import (
"fmt"
)
func process(input string) (err error) { // 返回值命名为 err
defer func() {
// recover() 只有在 defer 中调用才有效
if r := recover(); r != nil {
// 捕获到了一个 panic
fmt.Printf("Recovered from panic: %v\n", r)
// 修改命名返回值 err,告诉调用者我们出错了
err = fmt.Errorf("panic occurred: %v", r)
}
}()
if input == "bad" {
// 模拟一个致命错误
panic("something went terribly wrong")
}
// 如果没有 panic,err 的值保持为 nil (它的零值)
return nil
}
func main() {
err := process("good")
fmt.Printf("Processed 'good': err = %v\n", err)
fmt.Println("---")
err = process("bad")
fmt.Printf("Processed 'bad': err = %v\n", err)
}panic可在任何地方手动或被动触发recover只在defer语句中有效
输出:
Processed 'good': err = <nil>
---
Recovered from panic: something went terribly wrong
Processed 'bad': err = panic occurred: something went terribly wrong分析:
- 调用
process("bad")时,代码触发panic。 - 程序的控制流立即跳转到
defer函数。 recover()捕获了panic的值,阻止了程序的崩溃。defer函数内部,我们修改了命名返回值err,将panic信息包装成一个error。- 函数
process正常返回(不再是panic状态),并把我们刚刚在defer中创建的error作为返回值。 main函数收到了一个正常的error,而不是一个崩溃的程序。
这个模式可以将一个不稳定的、可能panic的库函数,包装成一个更安全的、只返回error的函数。
提示
defer 修改返回值的能力,是一个强大的高级特性。它依赖于命名返回值,并在 defer 的执行时机(return 赋值后,函数退出前)对这些返回值进行操作。虽然在日常业务代码中不常用,但在编写健壮的底层库和进行复杂的错误/panic 处理时,它是不可或缺的工具。
多个defer语句的执行顺序
如果一个函数里有多个 defer 语句,它们会像“一摞盘子”一样被管理。
- 你每写一个 defer,就像往桌上放一个盘子。
- 当函数即将返回时,Go 会从最上面的盘子开始,一个一个地拿走(执行)。
这就是后进先出 (Last-In, First-Out, LIFO) 的顺序。
func main() {
fmt.Println("main started")
defer fmt.Println("defer 1: cleanup") // 第三个被执行
defer fmt.Println("defer 2: another cleanup") // 第二个被执行
defer fmt.Println("defer 3: first defer") // 第一个被执行
fmt.Println("main finished")
}总结:defer 的核心用途
| 用途 | 示例 | 解释 |
|---|---|---|
| 资源清理 | defer file.Close()defer db.Close()defer resp.Body.Close() | 最最常见的用途。保证文件、数据库连接、网络响应体等被正确关闭。 |
| 锁的释放 | mu.Lock()defer mu.Unlock() | 在并发编程中,确保互斥锁一定会被释放,防止死锁。 |
| 收尾日志/追踪 | trace("entering myFunc")defer untrace("exiting myFunc") | 在函数入口记录信息,并用 defer 保证在函数退出时(无论成功失败)都打印退出信息。 |
| 修改命名返回值 | (高级用法) | defer 语句可以读取并修改函数的命名返回值。 |